






论文标题
spin: accelerating large language model inference with heterogeneous speculative models
论文地址
https://arxiv.org/pdf/2503.15921
作者背景
会津大学、西安交通大学、北卡罗来纳大学格林斯伯勒分校
动机
现有的投机算法通过小型模型(SSM)快速生成候选标记,然后让大语言模型并行地去做验证,从而加速推理过程。投机算法回顾:大模型推理加速:EAGLE-3介绍
在这个过程中,主要存在三方面的问题:
SSM选择: 如何为每个请求选择合适的SSM,以应对不同的推理难度?传统方法依赖于人工设置,无法动态适应请求的特性,或者干脆只有一个SSM;
批处理支持: 在验证阶段,如果想要把不同的SSM输出放到一个batch里面让模型并行验证,由于这些输出的长度不同,必然会产生大量padding,浪费了GPU资源;此外由于不同输出被大模型接受的情况很可能不同,batch中各样本需要从不同的位置重新开始采样,这带来了对齐问题;
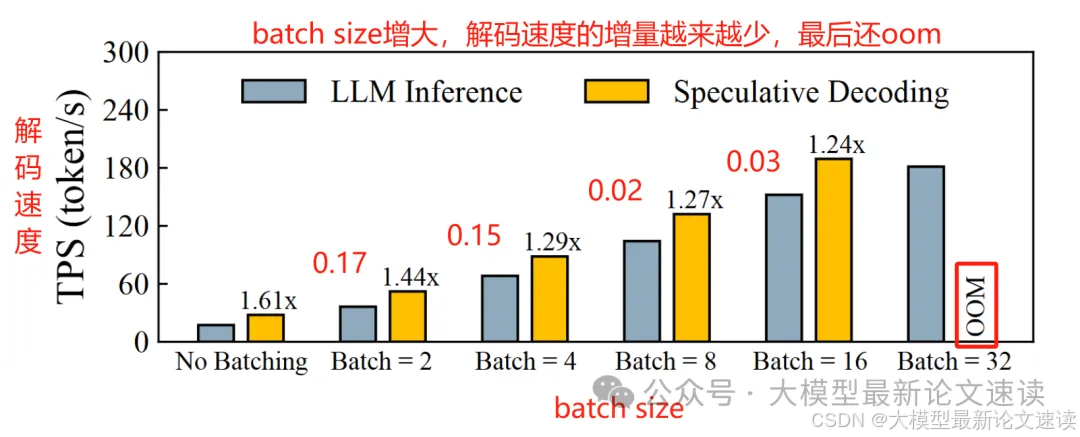
推测与验证割裂: 在当前的投机算法中,草稿和验证是两个割裂的过程,二者交替执行带来了GPU闲置;
本文方法
本文提出了SPIN(Speculative decoding with Heterogeneous Inference Networks,基于异构推理网络的投机解码),主要有3方面的创新
一、异构SSM选择机制
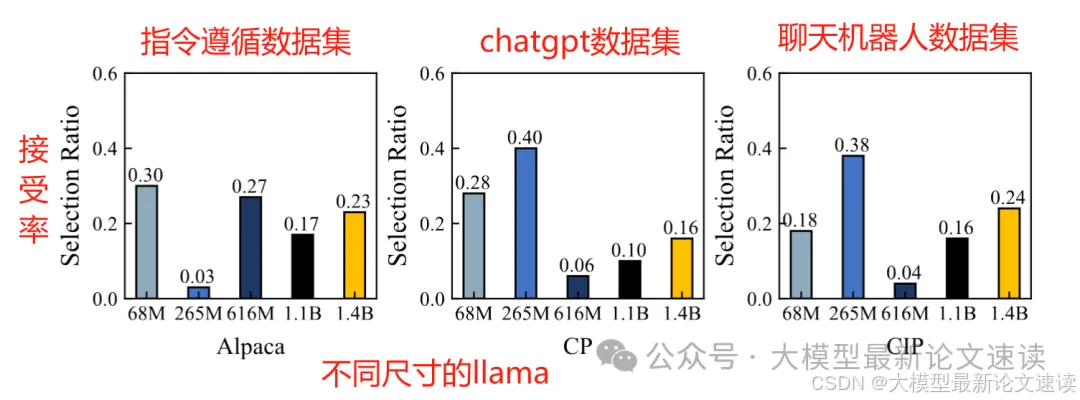
首先验证了多个异构SSM的有用性,使用5个小尺寸的llama(68M~1.4B)作为SSM,发现在不同的测试集上接受率最高的ssm分布是不同的,比如在Alpaca数据集上,265M模型仅在3%的情况下是最好的,而在CP数据集上这一比率提高到了40%,说明了异构SSM有不同的擅长领域
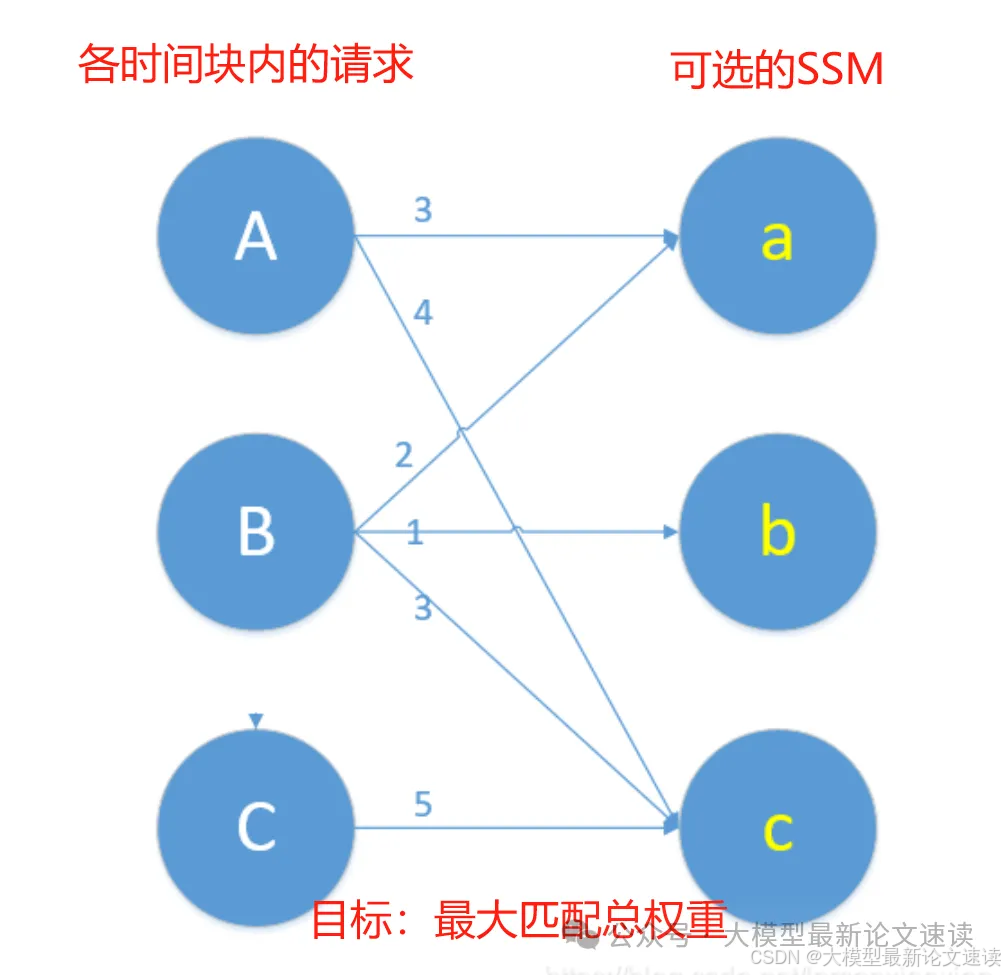
为了减少ssm切换(当然不至于每个token都换一下),作者在每个时间段内选择其中一个来进行快速草稿,并把SSM选择建模成了多臂老虎机问题(MAB):
探索阶段: 在每个epoch开始的几个时间段内,随机选择ssm进行推测,然后让大模型计算接受率;统计:【每个ssm每秒被LLM接受的token数量】,作为其分数
利用阶段: 使用KM算法解决二分图匹配问题,为每个请求分配最优的SSM
快速SSM切换: 实际推理时,如果需要从一个SSM切换到另一个SSM时,会预先在目标SSM上计算已生成token的KV缓存,同时在源SSM上继续进行推测,从而节省时间和计算资源
二、快速批量验证
SPIN通过把长请求分解为多个短请求的方法来减少填充token的数量,并使它们能够更好地对齐,并且拆分的逻辑是根据batch中各个请求的长度动态决定的。例如有4个请求,分别是:
请求A(10个token)、请求B(20个token)、请求C(30个token)、请求D(40个token)
在传统的批处理过程中,我们需要将请求A、B、C都填充成40个token才能组装batch;而SPIN通过请求分解,可能会把请求D均分成D1和D2(二者的长度都是20),从而更好地与较短请求对齐;
细节上需要注意这些padding不参与注意力权重运算
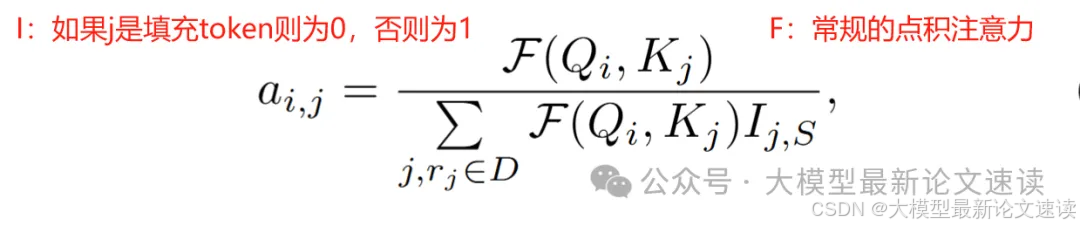
三、推测验证流水线
类似于DeepSeek提出的Dual pipe,通过对交替执行的两个任务进行编排,减少因任务资源消耗不同而造成的资源空闲:

实验结果
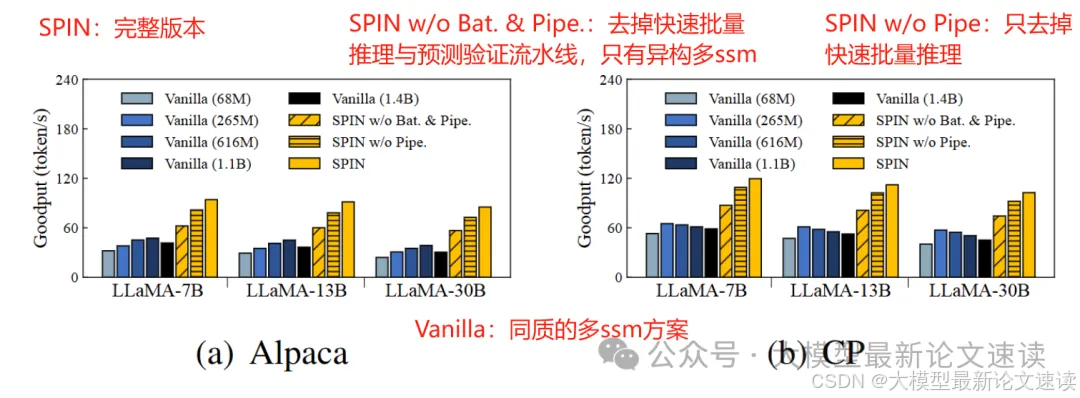
SPIN方法明显比其他使用同质的多ssm方案更快,并且上述二、三创新点都带来了效率提升
总结
本文提出了一种简单有效的投机解码方案,启发的点在于:
- 反正小模型的开销不大,可以在类似环节多用几个异构小模型试试
- 切分mini-batch,是提高效率减少各类“气泡”的常用手段


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









