









目录
Olfati-RL算法是一种用于解决分布式一致性问题的高效算法,它在许多实际应用中具有广泛的使用。本文将详细介绍Olfati-RL算法的原理、公式和实现过程。
1.背景介绍
一致性问题在分布式系统中非常重要,因为多个节点需要协调行动以保证系统整体的正确性。一致性问题的常见解决方案包括:Raft算法、Paxos算法和Olfati算法等。其中,Olfati算法是一种基于远程监督(remote supervision)的一致性算法,它具有高效、简单和易于理解的特点。
2.算法原理
Olfati算法的核心思想是通过节点之间的相互监督来达成一致性。每个节点维护一个状态,并通过接收其他节点的消息来更新自己的状态。节点之间通过交换消息来相互监督,以保证所有节点的状态都保持一致。
具体来说,Olfati算法的原理可以概括为以下几个步骤:
(1)节点通过发送消息来告诉其他节点自己的状态。
(2)当一个节点收到另一个节点的消息时,它会比较两个节点的状态,并选择一个更优的状态作为两个节点的共同状态。
(3)如果一个节点收到了所有其他节点的消息,但没有任何一个消息比自己的状态更优,那么它将把自己的状态设置为“空”(null)。
(4)当一个节点收到其他节点的“空”状态消息时,它会将自己的状态设置为“空”。
(5)重复以上步骤,直到所有节点的状态都保持一致。
3.公式
为了更好地理解Olfati算法的实现过程,我们可以用以下公式来表示算法的核心思想:
设节点集合为N,节点i的初始状态为si。对于任意的节点i和j,定义节点i比节点j更优的状态为(si>sj),反之则为(si<sj)。在Olfati算法中,节点i的状态更新规则如下:
(1)如果节点i收到了比自己更优的状态消息,则将自己的状态更新为该消息所表示的状态。即:如果存在某个节点j使得sj>(si),则将节点i的状态更新为sj。
(2)如果节点i收到了与自己相同或更差的状态消息,则不更新自己的状态。即:如果存在某个节点j使得sj≤si,则不更新节点i的状态。
(3)如果节点i没有收到任何消息,则将自己的状态设置为“空”。即:如果节点i没有收到任何消息,则将节点i的状态设置为null。
4.实现过程
为了实现Olfati算法,每个节点需要维护一个状态和一个消息队列。在每个时间步中,节点将自己的状态发送给其他所有节点,并从其他节点接收状态消息。在收到其他节点的消息后,节点按照上述规则更新自己的状态。如果节点的状态被更新为“空”,则该节点需要将自己的状态再次发送给其他所有节点,以便其他节点也能够将自己的状态更新为“空”。
Olfati算法的关键在于实现消息的发送和接收机制。为了保证算法的正确性,每个节点都需要保证自己的消息能够发送到其他所有节点,并且每个节点都需要正确地处理从其他节点接收到的消息。此外,为了防止节点之间的通信出现故障或延迟,Olfati算法还需要实现一些额外的机制来保证算法的稳定性和可靠性。
Olfati算法是一种简单、高效的一致性算法,它在分布式系统中具有广泛的应用前景。虽然该算法的实现过程相对复杂,但它的核心思想和实现方法都非常简单易懂。未来,我们可以进一步研究Olfai算法的优化和扩展,以提高其在不同应用场景下的性能和适用性。
5.核心matlab程序
%Olfati算法2
%---------系统赋初始值------------------------
clear;clc;
loop=200; %确定循环周期
s=0.5; %s取值范围为(0,1)
n=100; %确定智能体个数
m=1; %确定领导者直接影响智能体数目
r=3; %确定智能体感知半径
ra=(1/s)*[sqrt(1+s*(r^2))-1];
dw=5; %确定网格Lattice距离
dwa=(1/s)*[sqrt(1+s*(dw^2))-1];
h=0.8; %定义参数h,其取值范围为(0,1)
size=50; %定义初始范围
a=1;b=3; %0<=a<=b
c1=0.05;c2=0.3; %领导者影响函数参数,c1,c2>0
step=0.1; %确定步长
%-----------系统初始化--------------------------
q=size*rand(2,n); %初始化智能体初始位置向量
p=2*rand(2,n)-1; %初始化智能体初始速度向量
qr=size*rand(2,1); %初始领导者位置向量
pr=2*rand(2,1)-1; %初始领导者速度向量
qqr=zeros(2,loop); %每个时间段领导者的位置向量
ppr=zeros(2,loop); %每个时间段领导者的速度向量
uur=zeros(2,loop); %每个时间段领导者的加速度向量
qq=zeros(2,n,loop); %每个时间段智能体的位置向量
pp=zeros(2,n,loop); %每个时间段智能体的速度向量
%----------开始循环--------------------------
%---------对智能体进行循环,实验主题---------
for ld=1:loop
qq(:,:,ld)=q(:,:);
pp(:,:,ld)=p(:,:);
qqr(:,ld)=qr(:,:);
ppr(:,ld)=pr(:,:);
ur=cos(qr(:,1));
uur(:,ld)=ur(:,:);
%定义共识网络A,判断智能体之间的相互影响
A=zeros(n,n);
for i=1:n
for j=1:n
if [q(1,i)-q(1,j)]^2+[q(2,i)-q(2,j)]^2<=r^2
A(i,j)=1;
end
end
end
for i=1:n
A(i,i)=0;
end
d=zeros(n,n);
for i=1:n
for j=1:n
d(i,j)=sqrt((q(1,i)-q(1,j))^2+(q(2,i)-q(2,j))^2);
end
end
%实现fya(z)
%计算n(i,j)
N=zeros(n,n,2);
for i=1:n
for j=1:n
N(i,j,1)=(q(1,j)-q(1,i))/sqrt(1+s*d(i,j)^2);
N(i,j,2)=(q(2,j)-q(2,i))/sqrt(1+s*d(i,j)^2);
end
end
%计算da=||qj-qi||σ
da=zeros(n,n);
for i=1:n
for j=1:n
da(i,j)=(1/s)*[sqrt(1+s*(d(i,j)^2))-1];
end
end
%计算fya(da)
fya=zeros(n,n);
ph=zeros(n,n);
for i=1:n
for j=1:n
z1=da(i,j)/ra;
if z1<h & z1>=0
ph(i,j)=1;
elseif z1<=1 | z1>=h
ph(i,j)=0.5*(1+cos(pi*((z1-h)/(1-h))));
else
ph(i,j)=0;
end
z2=da(i,j)-dwa;
c=(b-a)/sqrt(4*a*b);
fy(i,j)=0.5*((a+b)*((z2+c)/sqrt(1+(z2+c)^2))+(a-b));
fya(i,j)=ph(i,j)*fy(i,j)*A(i,j);
end
end
%-----------------求智能体的位置影响------------------
%求u11=fya*N(i,j)
u11=zeros(n,n,2);
for i=1:n
for j=1:n
u11(i,j,1)=fya(i,j)*N(i,j,1);
u11(i,j,2)=fya(i,j)*N(i,j,2);
end
end
%求位置反馈u1
u1=zeros(2,n);
for i=1:n
for j=1:n
u1(1,i)=u1(1,i)+u11(i,j,1);
u1(2,i)=u1(2,i)+u11(i,j,2);
end
end
%----------------求智能体的速度影响----------------------
%求u22=aij*(pj-pi)
u22=[n,n,2];
for i=1:n
for j=1:n
u22(i,j,1)=A(i,j)*(p(1,j)-p(1,i));
u22(i,j,2)=A(i,j)*(p(2,j)-p(2,i));
end
end
u2=zeros(2,n);
for i=1:n
for j=1:n
u2(1,i)= u22(i,j,1)+ u2(1,i);
u2(2,i)= u22(i,j,2)+ u2(2,i);
end
end
%-----------------求领导者的影响------------------
%-----------------加入影响百分比--------------------
M=zeros(1,n);
M(1,1:m)=1;
%--------------------------------------------------
u3=zeros(2,n);
for i=1:n
u3(1,i)=M(1,i)*(-c1*(q(1,i)-qr(1,1))-c2*(p(1,i)-pr(1,1)));
u3(2,i)=M(1,i)*(-c1*(q(2,i)-qr(2,1))-c2*(p(2,i)-pr(2,1)));
end
%-----------------求加速度u-------------------------------------
%-----其中ur项为加入领导者反馈的影响,可以让智能体精确跟随领导者----
u=zeros(2,n);
for i=1:2
for j=1:n
u(i,j)=u1(i,j)+u2(i,j)+u3(i,j)+ur(i,1);
end
end
%----------------进行下一步运算--------------
%----------------对智能体进行计算------------
for i=1:2
for j=1:n
q(i,j)=q(i,j)+step*p(i,j);
p(i,j)=p(i,j)+step*u(i,j);
end
end
%----------------对领导者进行计算------------
for i=1:2
qr(i,1)=qr(i,1)+step*pr(i,1);
pr(i,1)=pr(i,1)+step*ur(i,1);
end
end
%---------------------循环结束,绘图------------------------
%---------------------智能体位置情况------------------------
%---------------------初始时刻-----------------------------
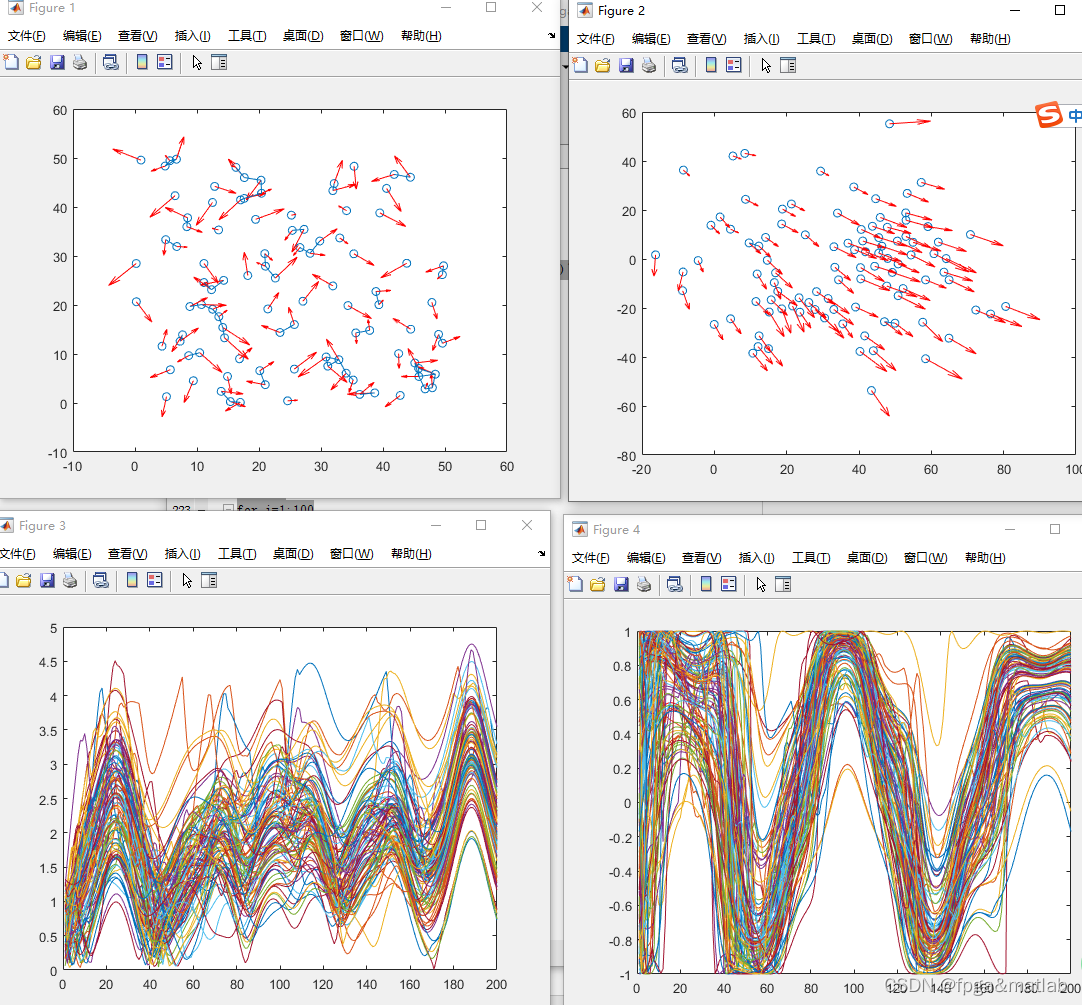
figure(1);
%-------以下注释为领导者,画出后图形不理想------
% plot(qqr(1,1),qqr(2,1),'o');
% hold on
% quiver(qqr(1,1),qqr(2,1),ppr(1,1),ppr(2,1),'Color','--');
% hold on;
plot(qq(1,:,1),qq(2,:,1),'o');
hold on;
quiver(qq(1,:,1),qq(2,:,1),pp(1,:,1),pp(2,:,1),'Color','red');
for i=1:n
for j=1:n
if sqrt((qq(1,i,1)-qq(1,j,1))^2+(qq(2,i,1)-qq(2,j,1))^2)<=r
line([qq(1,i,1),qq(1,j,1)],[qq(2,i,1),qq(2,j,1)]);
end
end
end
%-------------------最终时刻---------------------
figure(2);
plot(qq(1,:,loop),qq(2,:,loop),'o');
hold on;
quiver(qq(1,:,loop),qq(2,:,loop),pp(1,:,loop),pp(2,:,loop),'Color','red');
for i=1:n
for j=1:n
if sqrt((qq(1,i,loop)-qq(1,j,loop))^2+(qq(2,i,loop)-qq(2,j,loop))^2)<=r
line([qq(1,i,loop),qq(1,j,loop)],[qq(2,i,loop),qq(2,j,loop)]);
end
end
end
%-------------时刻t的智能体位置情况-----------------------------
%------将下面注释段复制到工作窗,给t赋值,显示步数为t时的状态------
% figure(5);
% plot(qq(1,:,t),qq(2,:,t),'o');
% hold on;
% quiver(qq(1,:,t),qq(2,:,t),pp(1,:,t),pp(2,:,t),'Color','red');
% for i=1:n
% for j=1:n
% if sqrt((qq(1,i,t)-qq(1,j,t))^2+(qq(2,i,t)-qq(2,j,t))^2)<=r
% line([qq(1,i,t),qq(1,j,t)],[qq(2,i,t),qq(2,j,t)]);
% end
% end
% end
%---------------跟随情况---------------------------
%-----------画速度模跟随情况------------------------
figure(3);
mdqr=zeros(1,loop);
for i=1:loop
mdqr(1,i)=sqrt((ppr(1,i))^2+(ppr(2,i))^2);
csqr(1,i)=ppr(1,i)/mdqr(1,i);
end
plot(1:loop,mdqr(1,1:loop),'color','red')
hold on
for i=1:n
for j=1:loop
mdq(i,j)=sqrt((pp(1,i,j))^2+(pp(2,i,j))^2);
csq(i,j)=pp(1,i,j)/mdq(i,j);
end
end
for i=1:100
plot(1:loop,mdq(i,1:loop))
hold on
end
%-------------画速度方向跟随情况--------------
figure(4)
plot(1:loop,csqr(1,1:loop),'color','red')
hold on
for i=1:100
plot(1:loop,csq(i,1:loop))
hold on
end
%
% figure(5)
%
% for i=1:n
% for j=1:n
% plot(1:loop,d(i,j))
% end
% end
D124



















 526
526

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











