




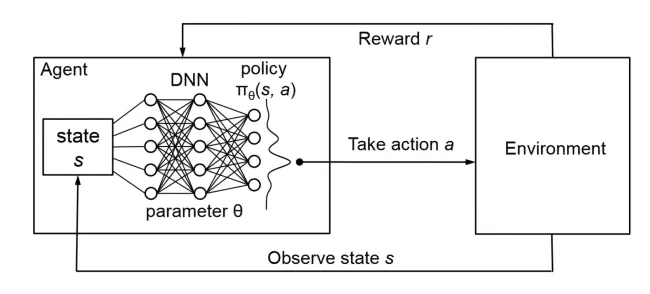
大家好,我是爱酱。本篇我们聚焦于强化学习中最具代表性的深度方法之一——DQN(Deep Q-Network)。DQN是Q-Learning的深度扩展,能处理高维状态空间(如图像),广泛用于Atari游戏、机器人等场景。下面以简单环境为例,详细讲解DQN的原理、流程和代码实现。
注:本文章含大量数学算式、详细例子说明及代码演示,大量干货,建议先收藏再慢慢观看理解。新频道发展不易,你们的每个赞、收藏跟转发都是我继续分享的动力!
一、DQN原理与数学基础
1. Q-Learning回顾
我们之前在强化学习的文章也介绍过Q-Learning,大家可以先去了解一下。这里附上传送门:
上篇:
下篇:
懒得看的伙伴可以看接下来的略解,不过强烈建议大家先去看看,对了解DQN会有大帮助!
Q-Learning算法通过维护Q表(Q-table)来学习最优动作价值函数,其更新公式为:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 877
877

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









