




大家好,我是爱酱。本篇我们将系统讲解K-近邻算法(KNN),内容涵盖原理、数学公式、案例流程、代码实现和工程建议,适合新手和进阶者学习。详细内容涵盖:K值选择与模型表现、距离度量的选择与影响、加权KNN,分类跟回归任务都会覆盖到!
注:本文章含大量数学算式、大量详细例子说明及大量代码演示,大量干货,建议先收藏再慢慢观看理解。新频道发展不易,你们的每个赞、收藏跟转发都是我继续分享的动力!
注:本文章颇长超过8500字、以及大量Python代码、非常耗时制作,建议先收藏再慢慢观看。新频道发展不易,你们的每个赞、收藏跟转发都是我继续分享的动力!
一、KNN算法简介
K-近邻算法(K-Nearest Neighbors, KNN)是一种非参数化、懒惰学习的监督学习算法,可用于分类和回归任务。KNN的核心思想是:对一个新样本,找到训练集中距离最近的K个邻居,根据这些邻居的类别或数值来预测新样本的类别或数值。

-
分类任务(Classification):采用多数投票原则,K个邻居中出现最多的类别为预测类别。
-
回归任务(Regression):取K个邻居的均值作为预测值。
我之前也在其他文章仔细介绍过分类任务和回归任务,有兴趣可以去补一下。
传送门:
回归任务介绍:
二、KNN算法原理与数学表达
1. 距离度量
KNN的关键在于如何度量样本间的距离。常用距离有:
-
欧氏距离(Euclidean Distance):
-
曼哈顿距离(Manhattan Distance):
-
闵可夫斯基距离(Minkowski Distance):
-
其他:汉明距离(Hamming)、余弦距离(Cosine)等
2. KNN分类数学表达
对一个新样本,KNN的预测类别
为:
其中为距离
最近的第
个训练样本的类别。
3. KNN回归数学表达
对一个新样本,KNN的预测值
为:
其中为最近K个邻居的真实数值。
三、KNN算法详细流程
Step 1:准备数据
-
收集并整理训练数据集,包含特征和标签。
-
对特征进行归一化或标准化(KNN对尺度敏感)。
Step 2:选择距离度量方式
-
通常选用欧氏距离,也可根据实际需求选择其他距离。
Step 3:确定K值
-
K是超参数,需通过交叉验证或“肘部法则”选择。
-
K太小易受噪声影响,K太大则可能欠拟合。
Step 4:预测新样本
-
对于每个新样本,计算其与所有训练样本的距离。
-
选出距离最近的K个邻居。
-
分类任务:统计K个邻居中出现最多的类别作为预测结果。
-
回归任务:取K个邻居的均值作为预测结果。
Step 5:评估与调优
-
用测试集评估模型准确率或均方误差。
-
调整K值、距离度量方式等参数优化模型。
四、KNN案例流程与完整代码演示
案例:二维数据点分类
我们用一组二维点(2D Points)作为训练集,类别用颜色区分。新样本点用KNN算法预测其类别,并可视化决策边界。
1. 数据准备与可视化
import matplotlib.pyplot as plt
import numpy as np
# 训练数据
X_train = np.array([[1,2],[2,3],[3,1],[6,5],[7,7],[8,6]])
y_train = np.array([0,0,0,1,1,1]) # 0: 蓝色, 1: 红色
plt.scatter(X_train[y_train==0,0], X_train[y_train==0,1], color='blue', label='Class 0')
plt.scatter(X_train[y_train==1,0], X_train[y_train==1,1], color='red', label='Class 1')
plt.xlabel('X1')
plt.ylabel('X2')
plt.title('KNN Training Data')
plt.legend()
plt.show()

2. 用KNN预测新样本
import matplotlib.pyplot as plt
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
# 训练数据
X_train = np.array([[1,2],[2,3],[3,1],[6,5],[7,7],[8,6]])
y_train = np.array([0,0,0,1,1,1]) # 0: 蓝色, 1: 红色
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, y_train)
# 新样本
X_test = np.array([[3,4],[7,5]])
y_pred = knn.predict(X_test)
print("Predicted classes:", y_pred)
![]()
3. 可视化决策边界
import matplotlib.pyplot as plt
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
# 训练数据
X_train = np.array([[1,2],[2,3],[3,1],[6,5],[7,7],[8,6]])
y_train = np.array([0,0,0,1,1,1]) # 0: 蓝色, 1: 红色
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, y_train)
# 新样本
X_test = np.array([[3,4],[7,5]])
y_pred = knn.predict(X_test)
print("Predicted classes:", y_pred)
# 绘制决策边界
h = .02 # 网格步长
x_min, x_max = X_train[:, 0].min() - 1, X_train[:, 0].max() + 1
y_min, y_max = X_train[:, 1].min() - 1, X_train[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
Z = knn.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.3, cmap=plt.cm.RdBu)
plt.scatter(X_train[y_train==0,0], X_train[y_train==0,1], color='blue', label='Class 0')
plt.scatter(X_train[y_train==1,0], X_train[y_train==1,1], color='red', label='Class 1')
plt.scatter(X_test[:,0], X_test[:,1], color='green', marker='*', s=200, label='Test Points')
plt.xlabel('X1')
plt.ylabel('X2')
plt.title('KNN Decision Boundary (K=3)')
plt.legend()
plt.show()

五、KNN进阶内容与工程实践
1. K值选择与模型表现
KNN的K值直接影响模型的泛化能力:
-
K太小(如K=1):模型对噪声敏感,容易过拟合(Overfitting),决策边界复杂。
-
K太大:模型过于平滑,容易欠拟合(Underfitting),决策边界简单。

常用K值选择方法:
-
交叉验证(Cross Validation):在训练集上用不同K值测试,选择准确率最高的K。
-
“肘部法则”:画出K与错误率的关系曲线,选择拐点处的K。
KNN在“月牙形”数据集上的K值交叉验证的示例代码(K值交叉验证):
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score
# 增加噪声、减少样本数
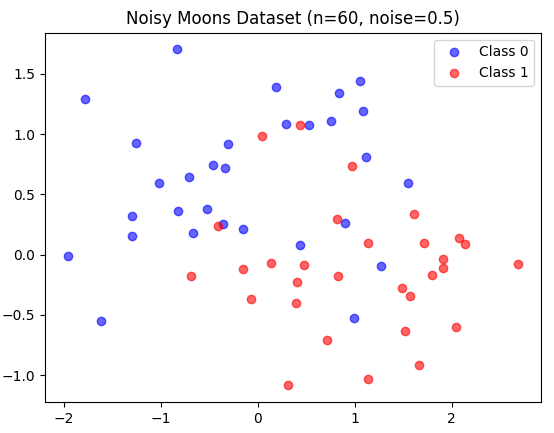
X, y = make_moons(n_samples=60, noise=0.5, random_state=42)
plt.scatter(X[y==0,0], X[y==0,1], color='blue', label='Class 0', alpha=0.6)
plt.scatter(X[y==1,0], X[y==1,1], color='red', label='Class 1', alpha=0.6)
plt.title('Noisy Moons Dataset (n=60, noise=0.5)')
plt.legend()
plt.show()
cv = 5
max_k = 20
k_range = range(1, max_k+1)
scores = []
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
score = cross_val_score(knn, X, y, cv=cv, scoring='accuracy').mean()
scores.append(score)
plt.plot(k_range, scores, marker='o')
plt.xlabel('K')
plt.ylabel('Cross-validated Accuracy')
plt.title('K Selection for KNN on Noisy Moons (n=60, noise=0.5)')
plt.grid(True)
plt.show()
best_k = k_range[np.argmax(scores)]
print(f"Best K: {best_k}, Best CV Accuracy: {max(scores):.3f}")
print("All scores:", scores)

代码解释
-
make_moons生成了一个有噪声、非线性可分的二分类数据集,非常适合演示KNN的K值选择。
-
cross_val_score对每个K进行5折交叉验证,记录平均准确率。
-
scores曲线显示不同K值下模型的泛化能力。
结果解读
-
K=1时,模型容易过拟合噪声点,准确率较低。
-
K变大后,模型对噪声不敏感,准确率提升,达到一个峰值(通常在K=5~10)。
-
K再变大,模型变得过于平滑,欠拟合,准确率下降。
-
最佳K值就是准确率最高处,对应的K值就是你应该选择的K。
你会看到一条“先上升后下降”的曲线,这就是K值选择的意义所在。
注:有时候,K值到很大的情况Acc依然很高,那是因为噪声(Noise)太少了。而现实情况中,噪声是一定会出现的。因此K值不是越高越好,而是能适配最大部分情况为佳!
总结
- KNN的K值选择在数据量小、噪声大、类别分布不均时作用最明显。
-
真实业务中,务必用交叉验证和多K对比来选择最优K,避免模型过拟合或欠拟合。
2. 距离度量的选择与影响
不同的距离度量适用于不同的数据特征:
-
欧氏距离:适合连续型、尺度一致的特征。
-
曼哈顿距离:对异常值更鲁棒,适合稀疏特征。
-
闵可夫斯基距离:p参数可调节距离的“敏感度”。
-
余弦距离:适合文本、方向型特征。
-
汉明距离:适合离散/二值特征。
在sklearn中可通过metric参数设置:
knn = KNeighborsClassifier(n_neighbors=3, metric='manhattan')
示例代码:
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
# 训练数据
X_train = np.array([[1,2],[2,3],[3,1],[6,5],[7,7],[8,6]])
y_train = np.array([0,0,0,1,1,1])
# 曼哈顿距离(L1范数)
knn = KNeighborsClassifier(n_neighbors=3, metric='manhattan')
knn.fit(X_train, y_train)
# 测试数据
X_test = np.array([[3,4],[7,5]])
y_pred = knn.predict(X_test)
print("Manhattan KNN Predicted classes:", y_pred)
3. 加权KNN
加权KNN会根据距离远近给邻居不同权重,距离越近权重越高,常用权重函数为倒数权重:
在sklearn中可直接设置:
knn = KNeighborsClassifier(n_neighbors=3, weights='distance')这样,预测时距离近的邻居影响更大,模型对边界点更敏感。
示例代码:
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
import matplotlib.pyplot as plt
# 训练数据
X_train = np.array([[1,2],[2,3],[3,1],[6,5],[7,7],[8,6]])
y_train = np.array([0,0,0,1,1,1])
# 加权KNN(距离倒数加权)
knn = KNeighborsClassifier(n_neighbors=3, weights='distance')
knn.fit(X_train, y_train)
# 测试数据
X_test = np.array([[3,4],[7,5]])
y_pred = knn.predict(X_test)
print("Weighted KNN Predicted classes:", y_pred)
# 决策边界可视化
h = .02
x_min, x_max = X_train[:, 0].min() - 1, X_train[:, 0].max() + 1
y_min, y_max = X_train[:, 1].min() - 1, X_train[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
Z = knn.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.3, cmap=plt.cm.RdBu)
plt.scatter(X_train[y_train==0,0], X_train[y_train==0,1], color='blue', label='Class 0')
plt.scatter(X_train[y_train==1,0], X_train[y_train==1,1], color='red', label='Class 1')
plt.scatter(X_test[:,0], X_test[:,1], color='green', marker='*', s=200, label='Test Points')
plt.xlabel('X1')
plt.ylabel('X2')
plt.title('Weighted KNN Decision Boundary (K=3)')
plt.legend()
plt.show()
4. KNN回归
KNN不仅能做分类,也能做回归。KNN回归的预测值为K个邻居的均值或加权均值。
下面是一个更复杂的KNN回归案例,包括带噪声的非线性数据、不同权重的KNN回归曲线、可视化和详细流程解释,非常适合理解KNN回归的行为和调参意义。
示例代码:KNN回归(可视化+流程讲解)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsRegressor
# 1. 生成带噪声的非线性训练数据
np.random.seed(42)
X_train = np.sort(5 * np.random.rand(40, 1), axis=0)
y_train = np.sin(X_train).ravel() + 0.3 * np.random.randn(40) # 正弦+高斯噪声
# 2. 创建测试数据用于预测(密集采样,便于画曲线)
X_test = np.linspace(0, 5, 500)[:, np.newaxis]
# 3. 创建两个KNN回归模型,分别用uniform和distance权重
knn_uniform = KNeighborsRegressor(n_neighbors=5, weights='uniform')
knn_distance = KNeighborsRegressor(n_neighbors=5, weights='distance')
# 4. 训练模型
knn_uniform.fit(X_train, y_train)
knn_distance.fit(X_train, y_train)
# 5. 预测
y_pred_uniform = knn_uniform.predict(X_test)
y_pred_distance = knn_distance.predict(X_test)
# 6. 可视化
plt.figure(figsize=(10, 6))
plt.scatter(X_train, y_train, color='darkorange', label='Training data')
plt.plot(X_test, y_pred_uniform, color='navy', label='Uniform weights')
plt.plot(X_test, y_pred_distance, color='c', label='Distance weights')
plt.title('KNN Regression with Uniform and Distance Weights')
plt.xlabel('X')
plt.ylabel('y')
plt.legend()
plt.show()

代码流程与结果解释
1. 数据生成
-
用正弦函数加高斯噪声生成40个训练点,模拟现实中非线性、带噪声的回归问题。
2. 测试点
-
用
np.linspace生成0~5区间的500个点,便于画出平滑的KNN回归曲线。
3. KNN回归模型
-
weights='uniform':每个邻居权重相同,预测值为K个邻居的简单平均。(普通的KNN 算法) -
weights='distance':距离越近的邻居权重越高,预测值为加权平均,更贴近局部数据。(权重和距离成反比)
4. 训练与预测
-
分别用两种权重训练模型,并对所有测试点做预测。
5. 可视化解析
-
橙色散点为训练样本。
-
蓝色曲线(uniform)和青色曲线(distance)分别为两种KNN回归预测结果。
-
可以看到distance权重的预测曲线在训练点附近更贴近真实数据,尤其在边界和噪声点多的地方。
6. 小结
KNN回归示例:带噪声的正弦数据上,使用uniform和distance权重的预测曲线对比
-
KNN回归可以拟合非线性关系,但K值和权重对结果影响很大。
-
距离加权的KNN回归在边界或噪声多时表现更好。
-
你可以调整
n_neighbors、weights、噪声大小等参数,观察模型拟合能力和泛化能力的变化。
5. KNN的优缺点与工程建议
优点
-
实现简单,无需训练过程,易于理解和可解释。
-
适用于多分类、多回归问题。
-
对异常值不敏感(K较大时)。
缺点
-
预测时计算量大,需遍历全部训练集(可用KD树等优化)。
-
对特征尺度敏感,需标准化或归一化。
-
对高维数据效果差(维度灾难)。
-
K值和距离度量需调优。
工程建议
-
特征需归一化/标准化,避免尺度影响距离计算。
-
可用交叉验证选K和距离度量。
-
大数据集可用KD树、球树等加速查找。
-
适合特征维度较低、样本量中等的场景。
六、KNN算法总结
K-近邻算法(KNN)是最经典的“懒惰学习”方法之一,凭借简单直观、无模型假设、易于实现等优点,广泛应用于分类、回归、推荐、异常检测等领域。KNN的核心思想是“以邻为师”,通过距离度量和多数投票实现预测。实际应用中,建议合理选择K值、距离度量和特征预处理方法,并结合数据规模和业务需求优化模型。
谢谢你看到这里,你们的每个赞、收藏跟转发都是我继续分享的动力。
如需进一步案例、代码实现或与其他聚类算法对比,欢迎留言交流!我是爱酱,我们下次再见,谢谢收看!

















 457
457

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









