




大家好,我是爱酱。我们在之前文章聊了算法跟模型的部分,也讲述了在选择算法及训练模型之前要做的数据准备。今天,我们就来聊聊之后的步骤。选好算法、训练好模型只是机器学习项目的中段,后续还有许多重要步骤,决定了模型能否真正落地并持续产生价值。今天我们就系统梳理一下,不同任务类型下该如何科学评估和优化你的模型。
注:本文章颇长近3000字,建议先收藏再慢慢观看。新频道发展不易,你们的每个赞、收藏跟转发都是我继续分享的动力!
一、五大机器学习任务类型及主流评估指标
注:这篇文章除了分类以外我就不细讲不同指标的算法了,因为每个都讲篇幅会太长了。如果大家有兴趣我可以单独再讲几期。分类我就附上算法当做个小小的例子。
1. 分类(Classification)——监督学习
-
常用指标:
-
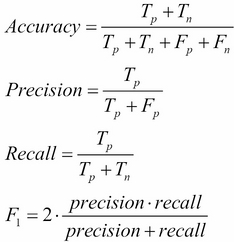
准确率(Accuracy):预测正确的样本占总样本比例。
-
精确率(Precision):预测为正例中,真正正例的比例。
-
召回率(Recall):实际正例中被正确识别的比例。
-
F1分数(F1 Score):精确率与召回率的调和平均数。
-
ROC-AUC:衡量模型区分正负样本能力,AUC越接近1越好。
-
-
适用场景:垃圾邮件识别、图片分类等。
-
算法(这次只给分类的算法,当是做个例子):
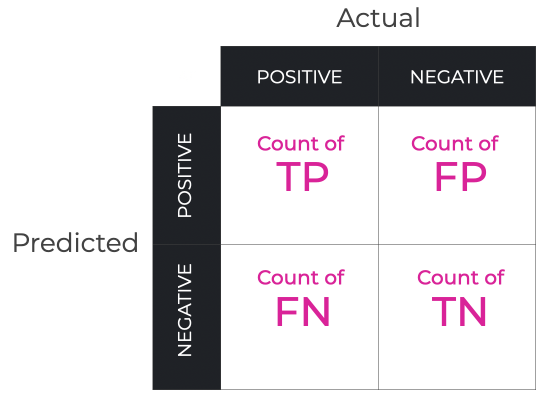
我们先讲解一下什么是 true positive (TP), false positive (FP), false negative (FN), 和 true negative (TN)。
True/ False,顾名思义就是正确与否。
Positive/ Negative,就是判断结果为阳性或阴性了。
我们会称这概念为混淆矩陣。
当然,我身为一个现实主义者,怎么能缺少例子呢?
让我举最简单以辨认猫狗图片为例。
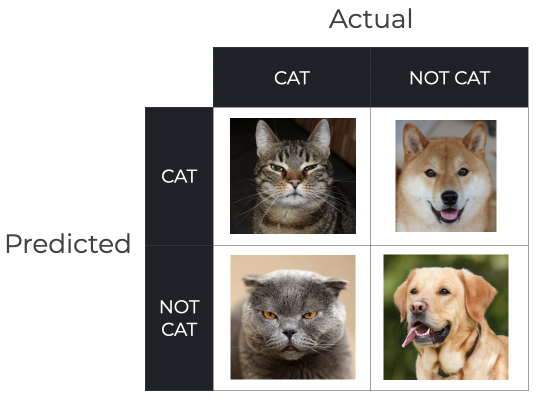
我们先假设我们的目标是猫猫(阳性):
1. 如果实际图片是猫,结果判断也是猫,那当然就是真阳性,也就是 true positive (TP)
2. 如果实际图片是狗,结果判断却是猫,那就是出现假阳性,也就是 false positive (FP)
3. 如果实际图片是猫,结果判断却是狗,那就是出现假阴性,也就是 false negative (FN)
4. 如果实际图片是狗,结果判断也是猫,那当然就是真阴性,也就是 true negative (TN)

了解完这些,你应该就能应用上面的指标了。
图标来源:Confusion Matrix, Explained - Sharp Sight
2. 回归(Regression)——监督学习
-
常用指标:
-
均方误差(MSE):预测值与真实值之差的平方的平均数。
-
均方根误差(RMSE):MSE的平方根,便于解释误差大小。
-
平均绝对误差(MAE):预测值与真实值之差的绝对值的平均数。
-
决定系数(R²):衡量模型对因变量变异的解释能力,越接近1越好。
-
-
适用场景:房价预测、销量预测等。
3. 聚类(Clustering)——无监督学习
-
常用指标:
-
轮廓系数(Silhouette Coefficient):评估聚类紧密度和分离度,越接近1越好。
-
Calinski-Harabasz指数:类间分离度与类内紧密度的比值,越大越好。
-
Davies-Bouldin指数:衡量聚类间的相似度,越小越好。
-
-
适用场景:客户分群、市场细分等。
4. 降维(Dimensionality Reduction)——无监督学习
-
常用指标:
-
重构误差(Reconstruction Error):降维后还原数据与原始数据的误差,越小越好。
-
保留方差(Explained Variance):降维后保留的信息比例,越高越好。
-
-
适用场景:特征压缩、数据可视化等。
5. 强化学习(Reinforcement Learning)——特殊类型
-
常用指标:
-
累计奖励(Cumulative Reward):智能体在环境中获得的总奖励,越高越好。
-
收敛速度(Convergence Speed):达到最优策略所需的训练轮数,越快越好。
-
策略稳定性(Policy Stability):策略在不同环境下的稳定性和鲁棒性。
-
-
适用场景:游戏AI、自动驾驶等。
二、模型验证(Model validation)方法
为了获得可靠的评估结果,通常采用以下几种数据划分与验证方法:
-
Holdout法(留出法):将数据集分为训练集和测试集(如8:2),简单高效,但评估结果依赖于一次性划分,可能有偶然性。
-
交叉验证(Cross-Validation):如k折交叉验证,将数据分为k份,轮流做训练和测试,最后取平均值,能更全面评估模型性能。
-
留一法(LOOCV, Leave-One-Out Cross-Validation):每次留一个样本做测试,其余全部训练,适合小数据集但计算量大。
三、过拟合与欠拟合
-
过拟合(Overfitting):模型在训练集表现很好,但在测试集或新数据上效果很差,常因模型过于复杂。解决方法包括简化模型、正则化、增加数据量、使用交叉验证等。
-
欠拟合(Underfitting):模型在训练集和测试集上都表现不佳,常因模型过于简单或特征不足。解决方法包括增加特征、选择更复杂的模型、减少正则化等。
出现这些致命问题,模型基本上要重新参调。实际上,也是有方法解决这些问题的,但这次就先不覆盖了。
四、模型调优(Model Tuning)
-
超参数调优:如学习率、正则化系数、树的数量等。常用方法有网格搜索(Grid Search)、随机搜索(Random Search)。
-
特征优化:进一步筛选、构造或变换特征,提升模型表现。
-
模型集成:如Bagging、Boosting等方法,结合多个模型提升准确率和鲁棒性。
五、模型保存与加载(Model Saving & Loading)
-
保存模型:将训练好的模型参数、结构保存到文件,便于后续调用和部署。
-
加载模型:在需要时快速恢复模型,无需重新训练,提升效率与可复现性。
六、模型部署(Model Deployment)
-
本地部署:模型运行在本地服务器或个人电脑,适合内部使用。
-
云端部署:利用云服务实现弹性扩展和远程调用。
-
API服务:将模型封装为REST API,便于集成到Web、App或自动化流程中。
总结
机器学习项目不是训练好模型就结束了,后续还包括针对不同任务类型选择合适的评估指标和验证方法,进行调优、保存、部署、监控和持续优化。只有全流程打通,模型才能真正为业务赋能,持续创造价值。
而实际上,就是模型上线部署了,也不是一切都做完了,我们还要继续监控、维护,以及依照用户反馈与迭代优化等。后续的部分我们之后有时间再聊。上面有关五大机器学习任务类型及主流评估指标的部分,我只探讨了分类的部分,我们在未来的日子也可以补上其余部分,敬请期待!有问题欢迎留言私信爱酱,我一定会尽我所能去为大家回答解忧的!
谢谢你看到这里,你们的每个赞、收藏跟转发都是我继续分享的动力。
我是爱酱,我们下次再见,谢谢收看!






















 到【灌水乐园】发言
到【灌水乐园】发言







