




大家好,我是爱酱。本篇将会系统梳理大语言模型(Large Language Model, LLM)、Transformer/BERT/GPT与传统NLP(Natural Language Processing)模型的本质区别、联系、代表性架构和应用场景,帮助你系统理解NLP领域的范式变迁。
注:本文章含大量数学算式、详细例子说明及大量代码演示,大量干货,建议先收藏再慢慢观看理解。新频道发展不易,你们的每个赞、收藏跟转发都是我继续分享的动力!
一、基本定义与发展脉络
1. 传统NLP模型(Traditional NLP Models)
-
定义:传统NLP模型指的是深度学习兴起前,广泛应用于文本处理的统计和浅层机器学习模型,如n-gram、TF-IDF、朴素贝叶斯(Naive Bayes)、隐马尔可夫模型(HMM)、条件随机场(CRF)、支持向量机(SVM)、逻辑回归等。
-
特点:
-
依赖人工特征工程和领域知识。
-
适合任务专用、结构化输出,如分词、词性标注、情感分析等。
-
训练和推理速度快,资源消耗低,易于解释和部署。
-
通常只处理短文本或局部上下文,难以捕捉长距离依赖。
-
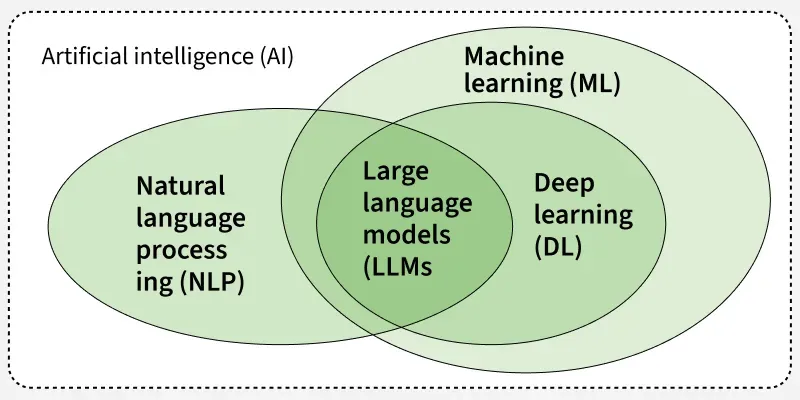
2. 大语言模型(LLM, Large Language Model)

-
定义:LLM是基于Transformer架构、参数规模极大的深度神经网络,通过预训练和微调,在大规模语料库上学习语言规律,具备强大的理解、生成和推理能力。
-
代表模型:GPT系列(GPT-3/4)、BERT及其变体、T5、PaLM、Llama、ERNIE等。
-
特点:
-
端到端学习,无需手工特征工程。
-
能处理长文本,理解复杂上下文,实现多任务一体化(如问答、摘要、翻译、写作、代码生成等)。
-
具备强大的泛化能力和上下文理解能力,支持zero-shot、few-shot、in-context learning。
-
训练和推理资源消耗极高,需大规模硬件支持。
-
二、核心架构与代表性模型
1. Transformer架构(LLM的基石)
-
原理:基于自注意力机制(Self-Attention),可并行处理序列中所有位置,捕捉长距离依赖。
-
结构:包含编码器(Encoder)、解码器(Decoder)或两者结合,支持大规模参数扩展和预训练-微调范式。
2. BERT vs. GPT:两大Transformer流派
| 维度 | BERT(Encoder-only) | GPT(Decoder-only) |
|---|---|---|
| 架构 | 仅用Transformer编码器,双向自注意力 | 仅用Transformer解码器,单向自回归 |
| 训练目标 | Masked Language Model(MLM),预测被mask的词 | Causal Language Model(CLM),预测下一个词 |
| 方向性 | 双向建模,能看左右上下文 | 单向建模,只看左侧上下文 |
| 典型应用 | 分类、问答、检索、NER、语义理解 | 文本生成、对话、续写、摘要、翻译 |
| 代表模型 | BERT、RoBERTa、ERNIE、ALBERT | GPT-2/3/4、Llama、ChatGPT、T5(编码-解码) |
-
数学表达(以BERT为例):
(
为去掉第
个词的上下文)
-
数学表达(以GPT为例):
3. 传统NLP模型的典型结构
-
n-gram语言模型:统计窗口内词的共现概率,难以捕捉长依赖。
-
TF-IDF+分类器:将文本转为稀疏向量,输入SVM、逻辑回归等模型。
-
HMM/CRF:建模序列标签任务,适合分词、词性标注、命名实体识别等。
三、LLM与传统NLP模型的本质区别
1. 模型架构与复杂度
-
传统NLP模型多采用规则、统计、浅层机器学习(如朴素贝叶斯、SVM、HMM、CRF、TF-IDF+分类器等),结构简单,参数较少,依赖人工特征工程和领域知识。
-
LLM(如GPT、BERT、PaLM等)基于Transformer架构,拥有数亿到数千亿参数,深度神经网络+自注意力机制,能自动学习复杂语言规律和上下文。
2. 训练数据规模与泛化能力
-
传统NLP模型通常在小规模、任务专用、人工标注数据集上训练,泛化能力有限。
-
LLM在超大规模、跨领域、多语言的海量数据上预训练,具备极强的泛化能力和上下文理解能力,支持zero-shot、few-shot和in-context learning。
3. 任务适应性与灵活性
-
传统NLP模型任务专用,每个任务需单独设计、训练和调优,迁移性弱。
-
LLM具备一模多用能力,可通过Prompt、微调等方式适配多种NLP任务,如文本生成、问答、翻译、摘要、代码生成等,极大提升了模型的灵活性和适用范围。
4. 上下文理解与生成能力
-
传统NLP模型只能处理短文本或局部上下文,难以捕捉长距离依赖和复杂语义。
-
LLM通过自注意力机制,能理解和生成长文本,输出连贯、上下文相关的内容,甚至具备一定的推理和创造能力。
5. 资源消耗与部署难度
-
传统NLP模型轻量级、易部署,适合资源受限场景和嵌入式应用。
-
LLM资源消耗极高,训练和推理需强大算力(GPU/TPU),部署和维护成本高,能耗大。
6. 可解释性与安全性
-
传统NLP模型可解释性强,决策过程易于追溯,适合高透明度需求场景(如金融、医疗)。
-
LLM为“黑盒”模型,决策过程难以解释,易受训练数据偏见影响,存在幻觉(hallucination)、安全和伦理风险。
四、优缺点对比
| 维度 | 传统NLP模型 | LLM(大语言模型) |
|---|---|---|
| 架构 | 规则/统计/浅层ML/小型神经网络 | Transformer深度神经网络,参数量大 |
| 数据需求 | 小规模、任务专用、标注数据 | 海量、多领域、多语言无监督数据 |
| 任务适应性 | 任务专用,需单独设计 | 一模多用,Prompt/微调即可适配多任务 |
| 上下文理解 | 局部、短文本、长依赖能力弱 | 长文本、全局上下文、复杂推理能力强 |
| 资源消耗 | 低,易部署,适合嵌入式 | 高,需GPU/TPU,部署和维护成本高 |
| 可解释性 | 强,透明,便于监管 | 黑盒,难解释,安全与伦理风险高 |
| 生成能力 | 无,主要用于分析、分类等判别任务 | 强,能生成文本、代码、摘要、翻译等 |
| 典型应用 | 分词、词性标注、情感分析、实体识别、文本分类 | 对话、写作、代码生成、问答、摘要、跨领域多任务 |

五、应用场景与工程选择建议
1. 传统NLP模型适用场景
-
资源受限、低算力环境(如移动端、IoT、嵌入式设备)
-
任务专用、数据量小、对可解释性要求高(如金融、医疗监管)
-
结构化文本、短文本处理(如分词、实体识别、关键词提取)
2. LLM适用场景
-
复杂语言理解与生成、多任务一体化需求(如智能客服、内容创作、代码生成、自动摘要)
-
长文本、复杂上下文、跨领域应用(如文档分析、跨语种翻译、知识问答)
-
需要强泛化能力和上下文推理的场景(如智能助手、教育、医疗辅助)
3. 工程选择建议
-
任务复杂度高、数据丰富、资源充足:优先考虑LLM,可大幅提升效果和自动化水平。
-
资源有限、需求单一、强调可解释性:优先传统NLP模型,部署简便、易于监管。
-
混合方案:可用LLM做预处理、特征提取,传统NLP模型做下游判别,或用LLM生成数据增强传统模型。
六、数学公式举例
-
传统NLP模型(朴素贝叶斯):
-
LLM(Transformer自注意力):
七、未来趋势
-
小型化与专用化LLM:未来将出现更多轻量级、领域专用的LLM,降低部署门槛,提升效率。
-
多模态融合:LLM将融合图像、音频、结构化数据,实现更强的多模态智能。
-
可解释性与安全性提升:研究可解释LLM、模型压缩、隐私保护等,推动AI合规落地。
-
混合/模块化架构:LLM与传统NLP模型协同,按需组合,兼顾效率、成本和效果。
八、总结
大语言模型(LLM, Large Language Model)与传统NLP模型代表了自然语言处理技术的两大时代。它们在模型架构、能力边界、应用场景和工程实现等方面有着本质区别,也各自具有不可替代的优势。
传统NLP模型以规则、统计和浅层机器学习为主,依赖人工特征工程和领域知识,结构简单、易于部署、可解释性强。它们适合数据量较小、任务专用、资源受限以及对可控性和透明度要求高的场景,如分词、词性标注、实体识别、情感分析等。传统NLP模型的局限在于难以捕捉长距离依赖、泛化能力有限,且难以应对复杂、多变的自然语言任务。
大语言模型(LLM)则以Transformer为核心架构,具备超大参数规模和强大的自监督预训练能力。LLM无需手工特征工程,能够自动学习复杂的语言规律和上下文关系,支持多任务、多语言、一体化应用。它们在文本生成、对话、摘要、翻译、代码生成等任务中表现卓越,极大推动了NLP的智能化、自动化和多样化发展。但LLM也面临高资源消耗、部署难度大、可解释性弱、幻觉与安全风险等挑战。
两者的本质区别在于:
-
传统NLP模型更强调“专用、可解释、轻量级”,适合小规模、结构化、任务定制的场景;
-
LLM则强调“通用、强泛化、自动化”,适合复杂、多变、长文本和跨领域的应用需求。
未来趋势是两类模型的融合与协同:
-
LLM将不断小型化、专用化,逐步降低部署门槛,提升效率和安全性;
-
传统NLP模型将在特定场景下继续发挥作用,并与LLM形成互补;
-
多模态、多任务、可解释、安全合规将成为NLP发展的新方向。
工程实践中,建议:
-
综合考虑业务需求、数据规模、算力资源、可解释性和安全合规等因素,灵活选择或组合LLM与传统NLP模型;
-
持续关注NLP领域的技术演进,善用LLM的强大能力,同时保持对模型可控性和风险的警觉。
理解LLM与传统NLP模型的本质区别与联系,是把握NLP技术变革、实现AI赋能业务的基础。未来的智能语言系统,将在两者的协同创新中不断进化,助力人类社会迈向更高水平的信息理解与交流。
谢谢你看到这里,你们的每个赞、收藏跟转发都是我继续分享的动力。
如需进一步案例、代码实现或与其他聚类算法对比,欢迎留言交流!我是爱酱,我们下次再见,谢谢收看!

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









