




大家好,我是爱酱。继上一篇DQN详解后,本篇我们来系统介绍DDPG(Deep Deterministic Policy Gradient)——一种专为连续动作空间设计的深度强化学习算法。DDPG结合了确定性策略梯度和DQN的关键技术,广泛应用于机器人控制、自动驾驶等连续控制场景。本文将详细讲解DDPG的原理、数学公式、案例流程和完整代码,风格与上一篇DQN一致,便于新手和进阶者理解和实操。
注:本文章含大量数学算式、详细例子说明及代码演示,大量干货,建议先收藏再慢慢观看理解。新频道发展不易,你们的每个赞、收藏跟转发都是我继续分享的动力!
一、DDPG算法简介
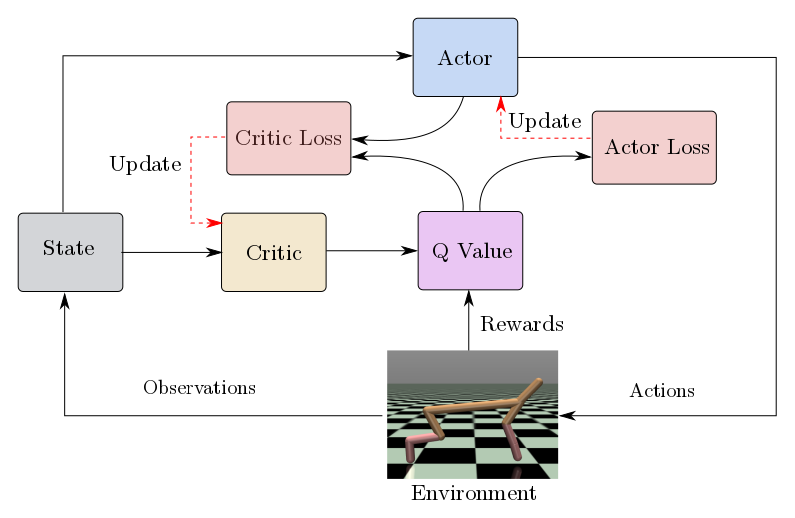
DDPG是一种基于Actor-Critic框架的深度强化学习算法,能够直接在连续动作空间下学习最优策略。它融合了DQN的经验回放和目标网络技术,同时采用确定性策略输出连续动作,通过为动作添加噪声实现探索。
不了解DQN的同学或者想重温的伙伴可以看我之前介绍DQN的文章,传送门在此:
【AI深究】深度Q网络(DQN)全网最详细全流程详解与案例(附Python代码演示)| 原理与数学基础、案例流程(CartPole示例)| 案例代码演示 | 关键点与工程建议-优快云博客
主要特点:
-
适用于连续动作空间
-
Actor-Critic结构:分别用策略网络(Actor)和价值网络(Critic)建模
-
经验回放与目标网络提升训练稳定性
-
训练时动作加噪声,增强探索能力
二、DDPG算法原理与数学公式
1. 策略与目标
DDPG采用确定性策略,直接输出动作
,目标是最大化累积期望回报:
其中为Actor网络参数,
为策略分布。
2. Critic网络(Q函数)更新
Critic网络近似动作价值函数,目标是最小化TD误差:
其中目标Q值为:
和
为目标网络。
3. Actor网络更新
Actor目标是最大化Critic输出的Q值,采用策略梯度:
即通过链式法则更新Actor参数。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5688
5688



 到【灌水乐园】发言
到【灌水乐园】发言








