




注:本系列将有五部分,分别对应五大机器学习任务类型,包括:
1. 分类(Classification)、2. 回归(Regression)、3. 聚类(Clustering)、4. 降维(Dimensionality Reduction)以及 5. 强化学习(Reinforcement Learning)
此文含大量干货,建议收藏方便以后再读!
注:此为两部分中的下部,上部请按下面链接前往!(强烈建议先看上部分)
大家好,我是爱酱。强化学习是机器学习五大任务中最具挑战性和潜力的分支之一,广泛应用于智能控制、博弈、机器人、自动驾驶、推荐系统等领域。作为强化学习专题的第二部分,本节将围绕实际案例,详细讲解强化学习的典型算法、核心思想、数学表达与操作流程,帮助你系统掌握强化学习的实践方法。(将继续延续上部分的完结部分)
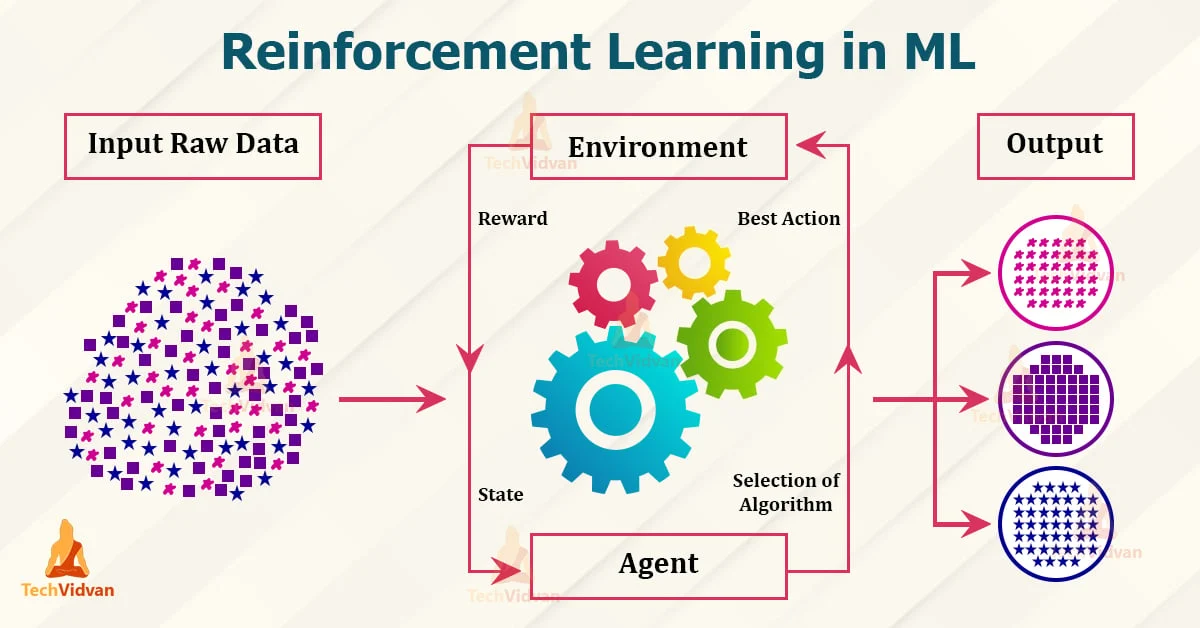
七、强化学习主流算法与详细流程
1. 动态规划(Dynamic Programming, DP)
适用场景:环境模型已知(即状态转移概率$P$和奖励已知)
代表方法:值迭代(Value Iteration)、策略迭代(Policy Iteration)
值迭代核心流程
-
初始化所有状态的价值
为0
-
重复更新:对每个状态
,按贝尔曼方程迭代
-
直到
优缺点:理论完备,但需环境模型,难以扩展到大规模或未知环境。
2. 蒙特卡洛方法(Monte Carlo Methods)
适用场景:环境模型未知,但能采样完整回合
核心思想:通过多次采样完整轨迹,直接用经验平均累计奖励估计价值函数
流程
-
反复采样完整回合,记录每步状态、动作、奖励
-
每个状态的价值由其后续实际累计奖励的平均值估计
-
可用于策略评估和策略改进
优缺点:无需环境模型,样本利用率低,需完整回合。
3. 时序差分学习(Temporal Difference, TD)
适用场景:环境模型未知,可在线学习
核心思想:结合动态规划和蒙特卡洛,边采样边更新价值函数
TD(0)更新公式
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 842
842




 到【灌水乐园】发言
到【灌水乐园】发言







