



大模型争宠让世界沸腾!
奥特曼刚更新GPT-5.1。高情商,更智能,更遵从指令。让全网惊呼最爱的GPT-4o又回来了。
马斯克后脚就悄悄发布了Grok 4.1,它在对话智能、情感理解和现实世界实用性方面设立了全新基准。
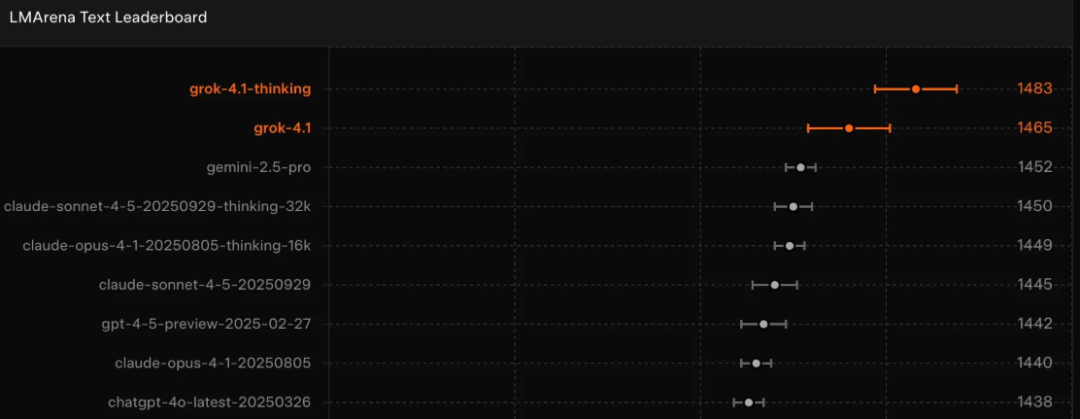
在行业权威的LMArena文本排行榜上,其深度推理模式以1483的Elo评分夺得榜首,领先之前排名最前Gemini-2.5-pro模型整整31分。
xAI引入了一个名为EQ-Bench的评估基准,Grok 4.1情商遥遥领先。
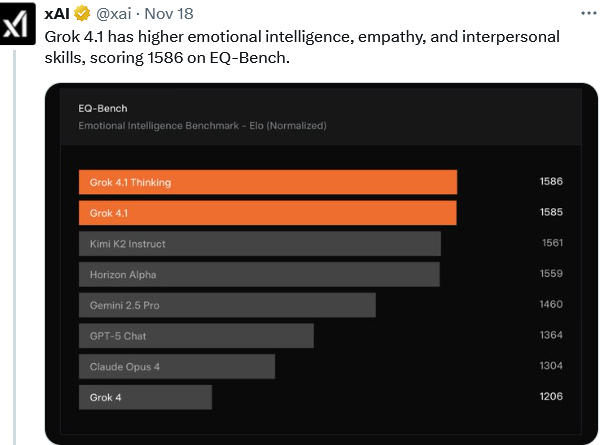
创意写作、理解力、洞察力、同理心和人际交往技巧等多个维度,展现出巨大的应用潜力。
但是在Gemini 3面前,它们都成了配角,小配角。
谷歌刚刚发布的Gemini 3,定义智能新高度
股神巴菲特都被“震撼”到了。他预先知晓了Gemini 3能力,砸了43亿美元买了谷歌母公司Alphabet的股份。

甚至网友搞了个梗,“Cloudflare 出事的原因找到了”。

来源@歸藏的AI工具箱
Gemini 3究竟有多强?
谷歌DeepMind团队表示:AI从单纯的信息处理迈向了具备深度思考与自主行动的新纪元。
它在推理能力上达到了目前的最高水平(State-of-the-art)。各项指标全面领先,很多甚至断崖式领先。
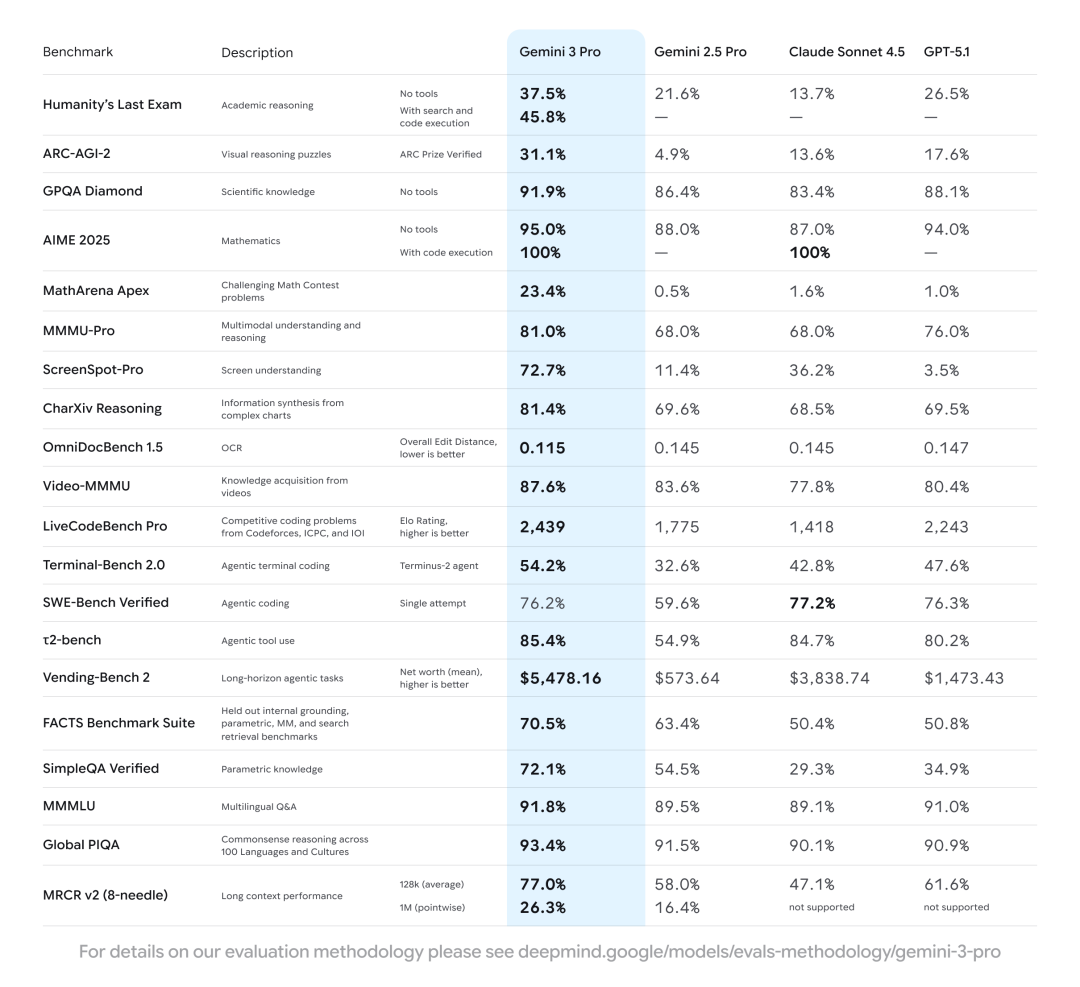
人类的最后一次考试(跨学科的专家级问题),不用工具就达到了37.5%,用上工具提升至45.8%,超越了之前Kimi K2 Thinking 用300轮工具调用达到的记录(44.9%)。
ARC-AGI-2抽象与推理语料库 (Abstraction and Reasoning Corpus)。这是目前公认最难测试“通用智能”的项目。它要求模型通过极少的例子学会全新的视觉规律,测试的是适应新任务的能力而非死记硬背。Gemini 3达到31.1%,是GPT-5.1的近两倍。
MathArena Apex顶级数学难题集合。Gemini 3达到23.4%,是Claude-4.5的14.6倍。
GPQA Diamond研究生级别的科学问题(物理、化学、生物等)。Gemini 3达到91.9%。
LiveCodeBench Pro编程竞赛题目。Gemini 3得分2439,高出GPT-5.1近200分。
Terminal-Bench 2.0终端(命令行)操作能力,54.2%。
τ2-bench (Tau-2)和Vending-Bench 2,使用工具和进行长程规划的能力极强。Vending-Bench 2更是达到$5478.16,断崖式领先。
MMMU-Pro大规模多学科多模态理解(看懂医学、工程、艺术等专业领域的图表和图像,并进行推理)81.0%。
ScreenSpot-Pro屏幕理解72.7%,比上一代高近7倍,比Claude高两倍多。
Video-MMMU视频理解(看懂视频中的因果关系、物理现象和事件流程)87.6%。
OmniDocBench 1.5和CharXiv Reasoning文档处理能力(OCR以及从复杂的科研论文图表中提取信息并综合分析的能力)也是大幅领先。
SimpleQA Verified和FACTS Benchmark Suite回答事实性问题的准确率分别是72.1%和70.5%,重点在于不产生幻觉(Hallucination),断崖式领先。
MMMLU和Global PIQA多语言理解和跨文化常识,达到91.8%和93.4%。
MRCR v2 (8-needle)大海捞针(Needle in a Haystack)测试。评估模型在极长文本(如 100 万词)中精准找到某一个微小细节的能力,也是大幅领先。
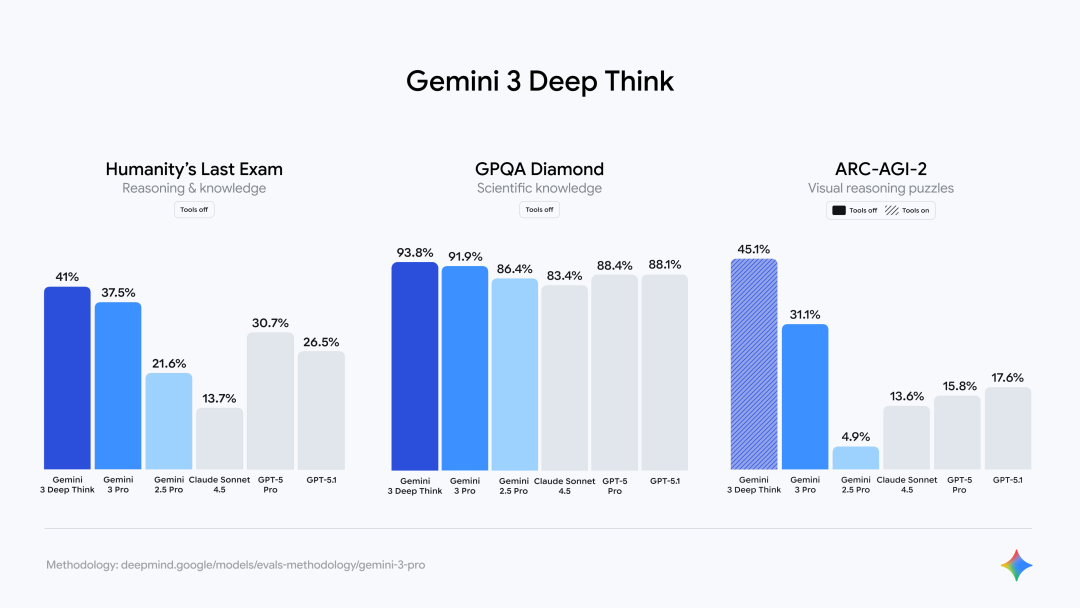
Gemini 3 Deep Think甚至再将能力往上提了提。
Gemini 3的回复智能、简洁且直接。摒弃了陈词滥调和无谓的恭维,只说你需要听的真知灼见,而不是你想听的漂亮话。
它是真正的思维伙伴,能以全新的方式帮助理解信息和表达自我。
从将晦涩的科学概念转化为高保真可视化代码,到进行创造性的头脑风暴,它无所不能。
比如模拟核聚变:

Write a written word piece about nuclear fusion, based on the following shader. Add a soundtrack. Overlay your piece, adjusting the shader and soundtrack intensity to reflect phases in achieving steady-state fusion. Return a single HTML file.
Gemini 3 能够编写代码可视化托卡马克装置中的等离子体流,并写出一首捕捉聚变物理精髓的诗。
多模态感知的全景拓展
Gemini 的设计初衷就是跨模态无缝合成信息。
文本、图像、视频、音频和代码,皆在其理解范畴。
Gemini 3结合了顶尖的推理能力、视觉与空间理解力、多语言性能以及100万token的上下文窗口。
这种组合让学习变得更加个性化。
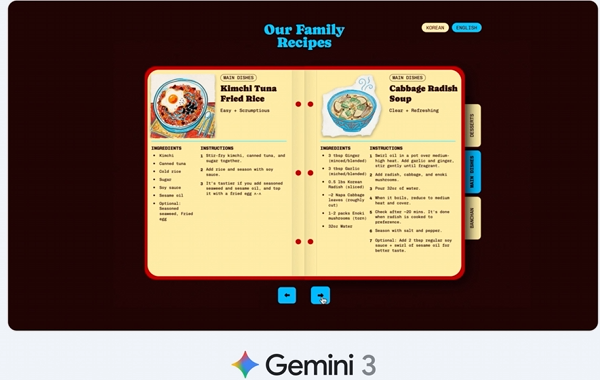
想学习家族传承的烹饪技艺,它可以解读并翻译不同语言的手写食谱,将其转化为可分享的家庭食谱书。

面对学术论文、长视频讲座或教程等新领域,它能生成交互式卡或可视化代码,辅助掌握核心内容。
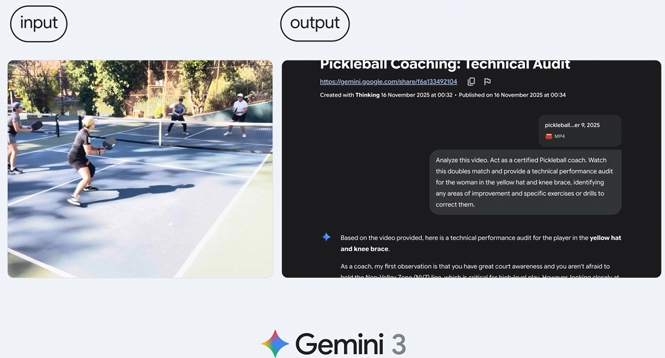
甚至在运动领域,它能分析匹克球比赛视频,识别改进点,并制定提升动作的训练计划。
为了更好地理解网络信息,谷歌搜索中的AI模式利用Gemini 3实现了全新的生成式UI体验。
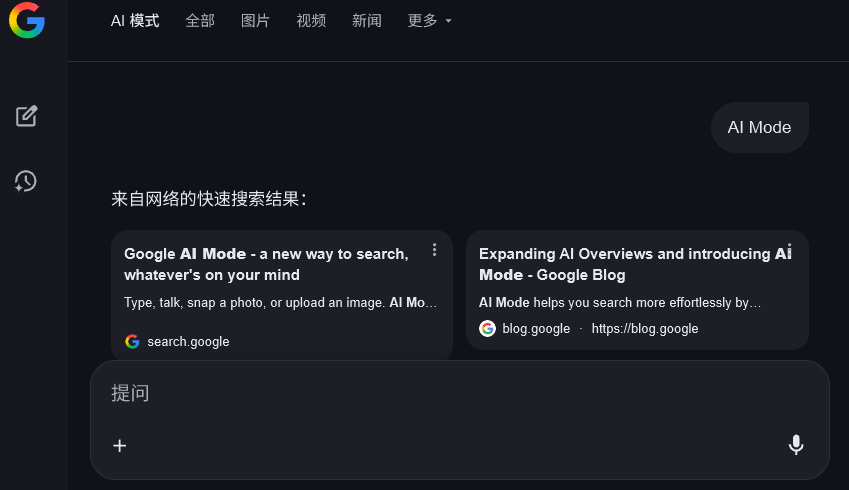
基于查询,它能即时生成沉浸式的视觉布局、交互式工具和模拟演示。
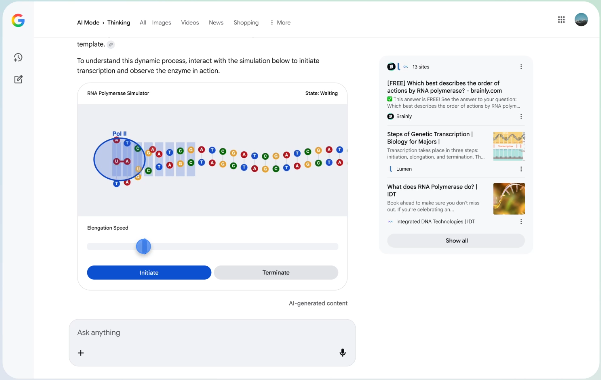
开发者体验的代际跨越
Gemini 3 进一步兑现了让开发者“实现任何想法”的承诺。
它在零样本生成方面表现卓越。能处理复杂的提示和指令,渲染出更丰富、交互性更强的Web UI。
它让产品更加自主,大幅提升了开发效率。
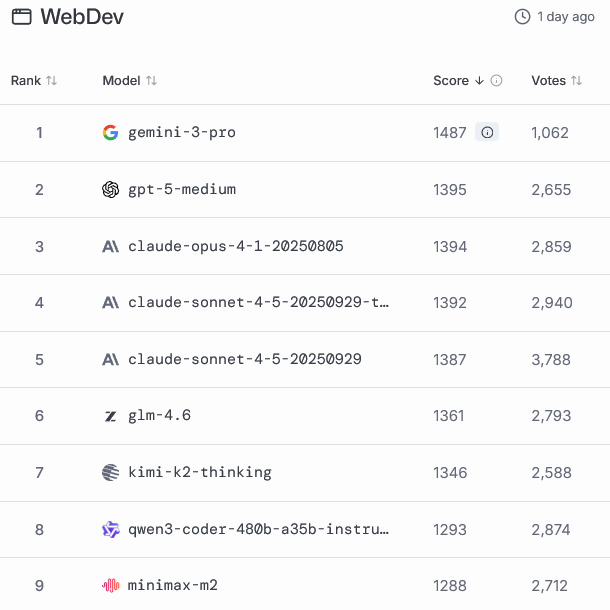
WebDev Arena排行榜上,它以1487 Elo的高分夺魁。
开发者现在可以在Google AI Studio、Vertex AI、Gemini CLI以及全新的代理开发平台Google Antigravity中使用 Gemini 3。
Cursor、GitHub、JetBrains、Manus、Replit等第三方平台也已接入。
Google Antigravity是一个全新的代理开发平台,旨在让开发者在更高维度的任务层面上进行操作。
拥有对编辑器、终端和浏览器的直接访问权限。
代理可以自主规划,代表用户同时执行复杂的端到端软件任务,并自行验证代码。
Google Antigravity不仅集成了Gemini 3 Pro,还紧密耦合了最新的Gemini 2.5 Computer Use(计算机使用)模型用于浏览器控制,以及顶级的图像编辑模型Nano Banana。
比如官方demo演示,Google Antigravity使用Gemini 3驱动一个航班追踪应用的端到端代理工作流。代理独立规划、编写代码,并通过基于浏览器的计算机操作验证了其执行结果。

长程规划与原生安全
Gemini 3能保持一致的工具使用和决策制定,在模拟的全年运营中,既不偏离任务,又推动了更高的回报。
Gemini 3 Pro 长程规划能力图:
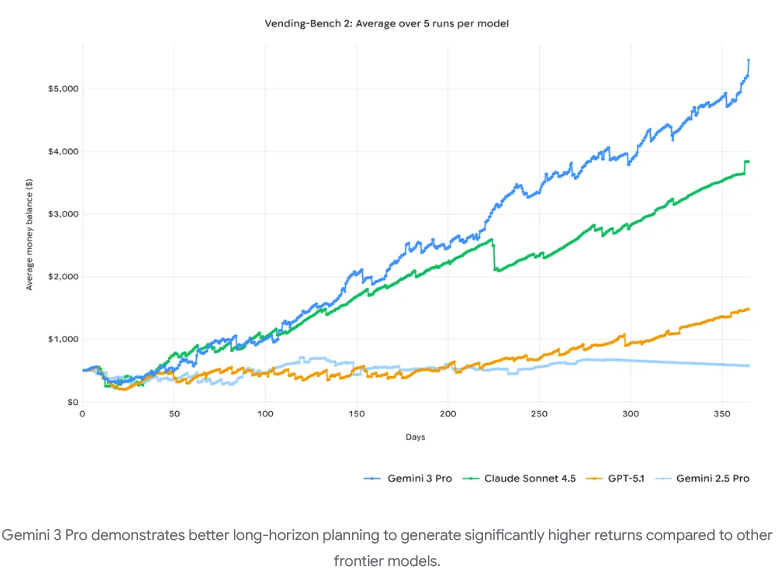
这意味着 Gemini 3 能更有效地协助处理日常生活事务。
结合更深层的推理和更一致的工具使用,它能代表用户执行操作。
从预订本地服务到整理收件箱,即使是复杂的多步骤工作流,它也能在用户的控制和指导下从头至尾完成。
在安全性方面,Gemini 3进行了谷歌AI模型史上最全面的安全评估。
模型表现出更低的阿谀奉承倾向(Sycophancy),对提示注入(Prompt Injections)的抵抗力增强,并提升了针对网络攻击滥用的防护。
除内部的前沿安全框架(Frontier Safety Framework)测试外,谷歌还与全球领先的主题专家合作。
UK AISI(英国人工智能安全研究所)等机构已获得早期访问权。
Apollo、Vaultis、Dreadnode等行业专家也提供了独立评估。
Gemini 3 Deep Think模式,谷歌将投入更多时间进行安全评估及收集测试者反馈,预计未来几周内向Google AI Ultra订阅用户开放。
Nano Banana 2也强的离谱,应该很快就要发布了。
参考资料:
https://blog.google/products/gemini/gemini-3/?utm_source=deepmind.google&utm_medium=referral&utm_campaign=gdm&utm_content=#responsible-development
https://x.com/GeminiApp/status/1990812977818431548
END

















 416
416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









