 Qwen3-VL:开源多模态新高度
Qwen3-VL:开源多模态新高度




在发布 Qwen3-VL 数月后,阿里巴巴近日发布了这款开源多模态模型的详细技术报告。数据显示,该系统在基于图像的数学任务上表现出色,并能分析数小时的视频内容。
该模型可处理海量数据,在 25.6 万 token 的上下文窗口内,轻松处理两小时长的视频或数百页的文档。
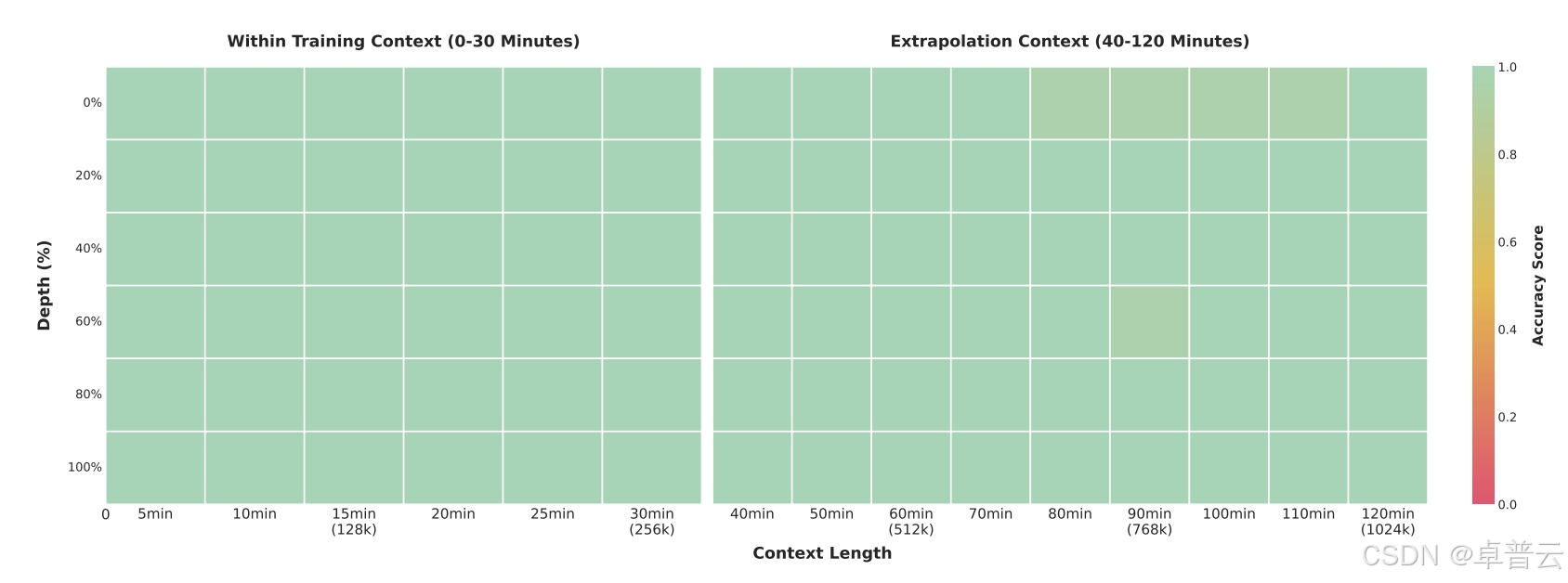
在“大海捞针”(needle-in-a-haystack)测试中,其旗舰版 2350 亿参数模型能在 30 分钟视频中以 100% 的准确率定位单个关键帧。即使在包含约 100 万 tokens 的两小时视频中,其准确率仍高达 99.5%。该测试方法是在长视频中随机插入一个语义上重要的“针”帧,要求模型找出并分析它。
在已发布的基准测试中,Qwen3-VL-235B-A22B 模型经常超越 Gemini 2.5 Pro、OpenAI GPT-5 和 Claude Opus 4.1 —— 即使竞争对手启用了推理功能或高“思考预算”(high thinking budgets),Qwen3-VL 依然领先。
该模型在视觉数学任务中优势显著:
- 在 MathVista 上得分 85.8%,高于 GPT-5 的 81.3%;
- 在 MathVision 上以 74.6% 领先,超过 Gemini 2.5 Pro(73.3%)和 GPT-5(65.8%)。
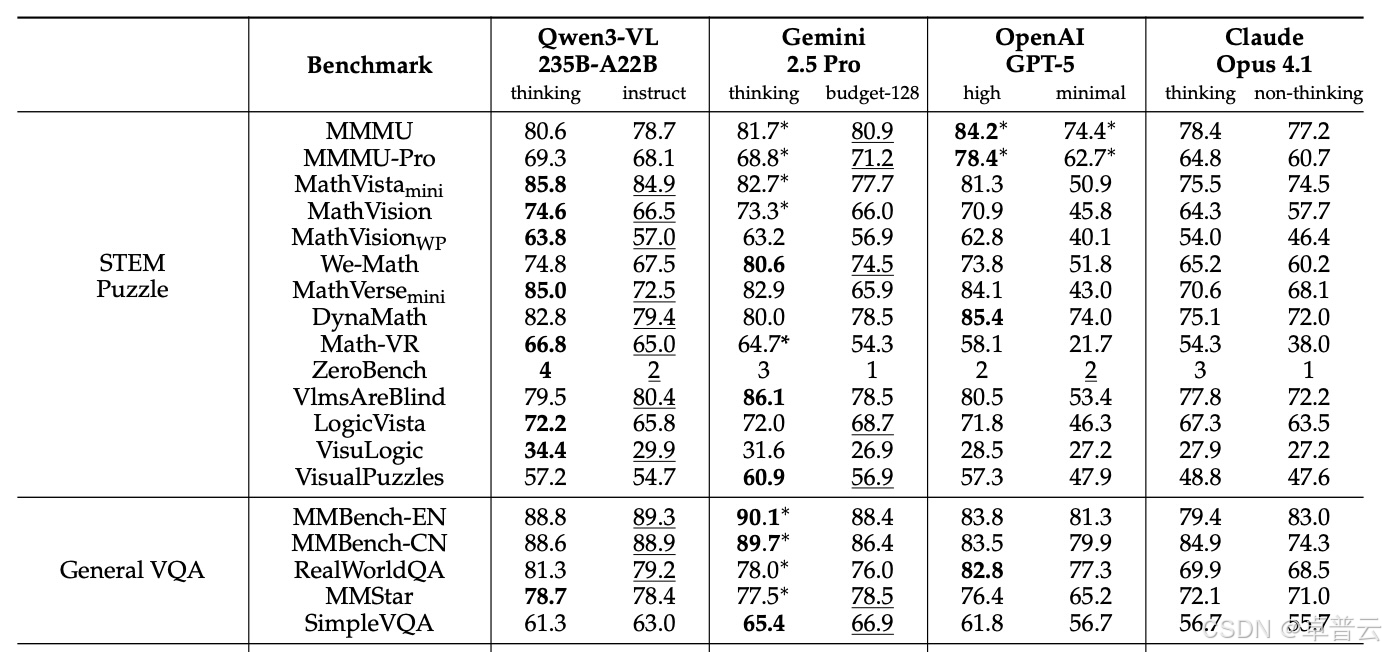
该模型在专业领域也表现全面:
- 在文档理解测试 DocVQA 中得分为 96.5%;
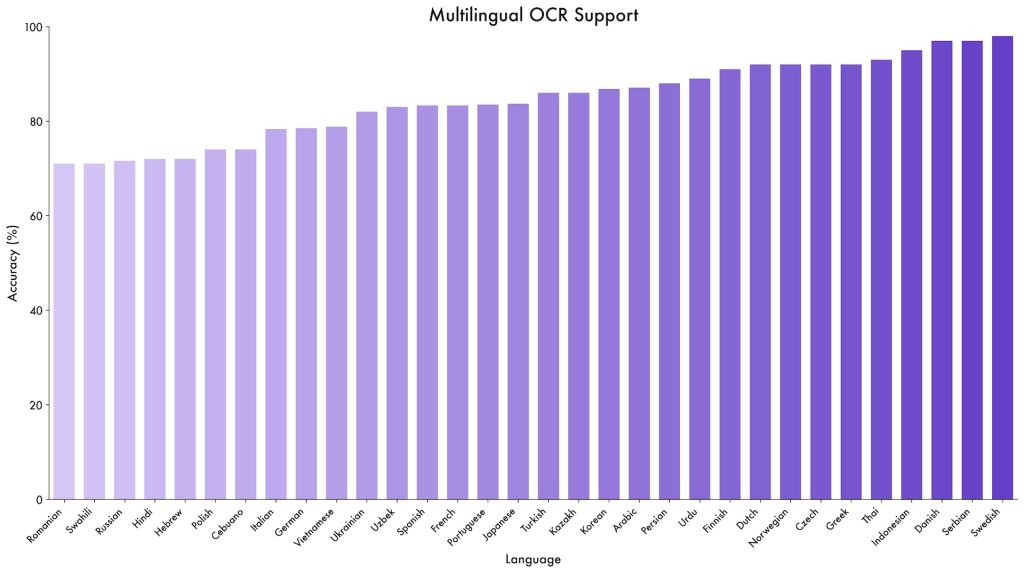
- 在 OCR 基准 OCRBench 中获得 875 分,支持 39 种语言,是前一代模型的近 4 倍。
阿里巴巴称,该系统在 图形用户界面(GUI)智能体任务中展现出新能力:
- 在测试 GUI 导航的 ScreenSpot Pro 上准确率达 61.8%;
- 在 AndroidWorld(要求模型独立操作 Android 应用)中,Qwen3-VL-32B 达到 63.7%。
该模型还能处理复杂的多页 PDF 文档:
- 在长文档分析基准 MMLongBench-Doc 上得分为 56.2%;
- 在科学图表理解基准 CharXiv 中,描述任务达 90.5%,复杂推理问题达 66.2%。
不过,它并非全面领先。在复杂的 MMMU-Pro 测试中,Qwen3-VL 得分 69.3%,落后于 GPT-5 的 78.4%。商业竞争对手在视频问答(Video QA)类基准中也普遍领先。数据表明,Qwen3-VL 是视觉数学与文档理解的专家,但在通用推理方面仍有差距。
多模态 AI 的三大关键技术突破
技术报告列出了三项主要架构升级:
- 交错式 MRoPE(Interleaved MRoPE) 取代了此前的位置编码方法。旧方法按维度(时间、水平、垂直)分组数学表示,而新方法将这些表示均匀分布到所有可用数学区域,旨在提升长视频处理性能。
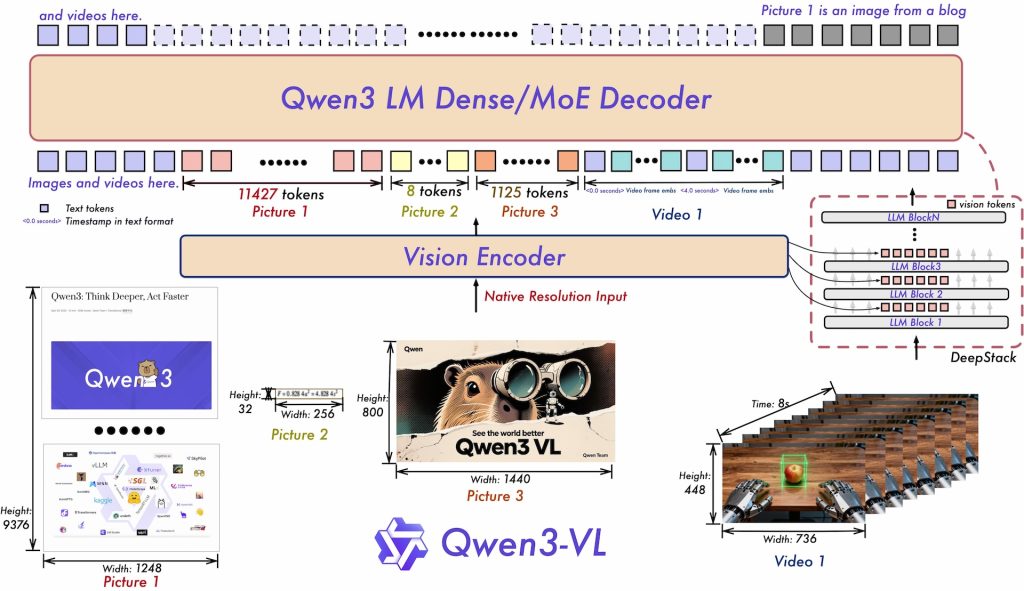
- DeepStack 技术 允许模型不仅使用视觉编码器的最终输出,还能访问中间层结果,从而在不同细节层次上利用视觉信息。
- 基于文本的时间戳系统 替代了 Qwen2.5-VL 中复杂的 T-RoPE 方法。新系统不再为每帧分配数学时间位置,而是直接在输入中插入简单文本标记(如
<3.8 seconds>),简化流程并提升对视频时序任务的理解能力。
基于万亿 token 的大规模训练
阿里巴巴在多达 1 万块 GPU 上分四个阶段训练该模型。在初步学习图文对齐后,系统接受了约 1 万亿 tokens 的全模态训练,数据来源包括:
- 网络爬取内容
- Common Crawl 中的 300 万份 PDF
- 超过 6000 万项 STEM 任务
训练后期,上下文窗口从 8,000 逐步扩展到 32,000,最终达到 26.2 万 tokens。“Thinking”(思考)版本还接受了专门的思维链(Chain-of-Thought)训练,使其能显式规划推理步骤,以更好解决复杂问题。
Apache 2.0 开源授权
自 2025 年 9 月以来发布的所有 Qwen3-VL 模型均以 Apache 2.0 许可证开源权重,可在 Hugging Face 获取。产品线包括:
- 稠密模型:参数规模从 2B 到 32B
- 混合专家模型(MoE):30B-A3B 和巨型 235B-A22B
虽然“从长视频中提取帧”这类功能并非全新(Google 的 Gemini 1.5 Pro 早在 2024 年初就已实现),但 Qwen3-VL 在开源生态中提供了极具竞争力的性能。鉴于前代 Qwen2.5-VL 已在研究社区广泛应用,新一代模型有望进一步推动开源多模态 AI 的发展。
如何部署 Qwen3-VL?
要部署 Qwen3-VL 就需要选择合适的 GPU。Qwen3-VL 作为一款开源多模态大模型(支持图像、视频、文档等),其推理和训练对硬件有较高要求,但得益于其开源性和对主流框架(如 PyTorch、vLLM、SGLang)的兼容性,可以在多种 GPU 上运行,具体取决于你使用的部署方式、模型大小(2B ~ 235B)和量化策略。以下是针对不同规模的模型推荐的 GPU 型号:
| 模型规模 | 推荐 GPU | 量化 | 用途 |
|---|---|---|---|
| Qwen3-VL-2B/7B | RTX 4000 Ada, L40S | int4 | 本地开发、demo |
| Qwen3-VL-32B | L40S, H100 | int4/int8 | 企业推理、GUI Agent |
| Qwen3-VL-235B (MoE) | H100 ×4, H200 ×2 | int4 | 高精度视频/文档分析、训练 |
以上所提到的所有 GPU,在 DigitalOcean 云平台上都可以按需租到,而且价格低于 AWS、GCP 等云平台,具体的机型配置、价格可直接咨询 DigitalOcean 中国区独家战略合作伙伴卓普云 aidroplet.com。
具体的部署方法,我们曾经写过一篇“如何在 DigitalOcean 的服务器上部署 Qwen3 模型”,基本步骤是一样的,具体可以在卓普云官网的博客中阅读。


















 305
305

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









