



DeepSeekV3.2正式版刚刚开源了。

同时发布两个正式版模型:DeepSeek-V3.2 和 DeepSeek-V3.2-Speciale。
DeepSeek-V3.2标准版,旨在成为日常任务与通用智能体(Agent)场景的首选。
它在架构设计上极度克制,力求在推理能力与输出长度之间找到最优解。
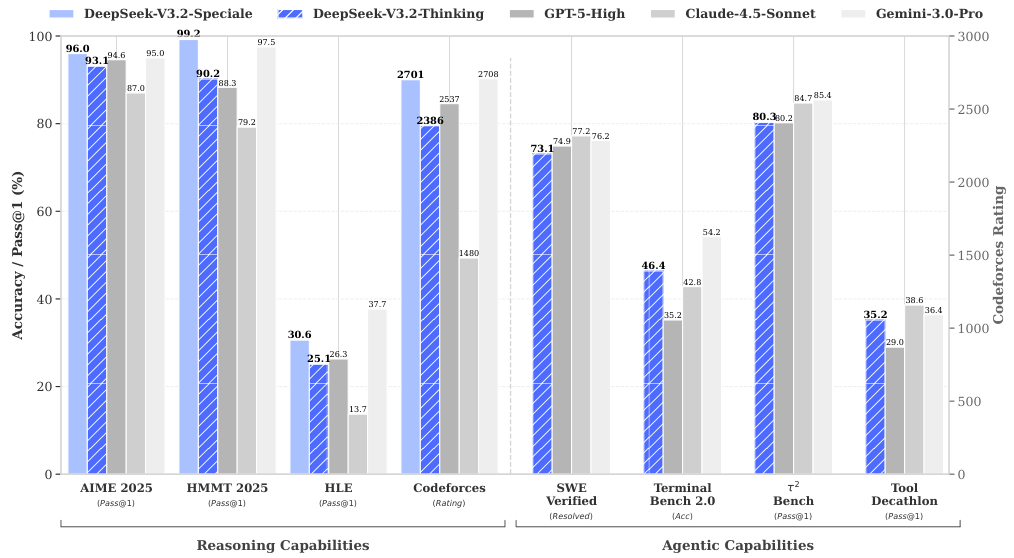
在公开的推理类基准测试中,DeepSeek-V3.2展现出了与GPT-5分庭抗礼的实力,仅以微弱差距次于Gemini-3.0-Pro。
对于用户而言,更直观的感受在于其显著降低的计算开销与等待时间。
相比于Kimi-K2-Thinking等竞品,V3.2在保持高智商的同时,输出更加精炼,不再为了展示思考过程而产生冗长的废话,这使得它在实际部署中具备了极高的性价比。
DeepSeek-V3.2-Speciale的目标则是将开源模型的推理能力推向极致,探索模型能力的边界。
这是一个不计成本、追求极致推理能力的长思考增强版。
它不仅继承了基础版本的架构优势,更融合了DeepSeek-Math-V2在定理证明领域的深厚积累。
在指令跟随、严谨数学证明与逻辑验证等高难度任务上,Speciale展现出了令人咋舌的统治力。
该模型在主流推理基准测试上的表现足以让整个开源界为之振奋。
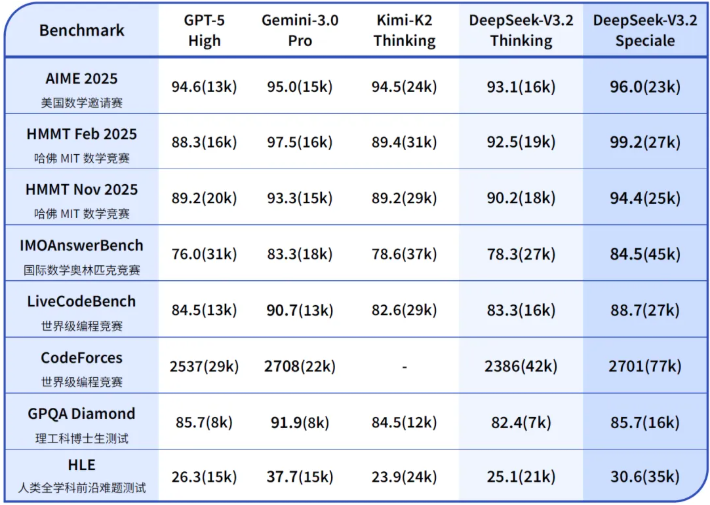
数据不会说谎。DeepSeek-V3.2-Speciale在2025年国际数学奥林匹克(IMO)和中国数学奥林匹克(CMO)中均斩获金牌。
在国际大学生程序设计竞赛全球总决赛(ICPC World Finals)中,它的表现相当于人类选手的第二名;在国际信息学奥林匹克(IOI)中,它位列第十。
这些成绩意味着,在纯粹的逻辑与代码竞赛领域,开源模型已经能够与人类最顶尖的大脑一较高下。
当然,这种极致能力伴随着高昂的代价,Speciale版本消耗的Token数量显著增加,且暂不支持工具调用,目前仅供研究使用。
稀疏注意力机制打破长文本算力诅咒
架构层面的革新是DeepSeek-V3.2能够兼顾性能与效率的基石。
长久以来,主流大模型架构中广泛采用的Vanilla Attention存在一个致命缺陷:计算复杂度随着序列长度的增加呈平方级增长。
处理一篇长文档所需的算力,并不是处理短文档的简单倍数,而是指数级的暴涨。
这导致模型在面对长上下文时,要么推理速度如蜗牛爬行,要么显存瞬间爆炸,成为了限制模型扩展视窗的物理锁链。
DeepSeek团队推出了一种全新的注意力范式——DeepSeek稀疏注意力(DSA)。
DSA的核心逻辑在于将计算复杂度从平方级降低到了线性级。
它不再让模型在每一个步骤都关注上下文中的所有信息,而是引入了一种极其高效的筛选机制。
这种机制并不盲目地丢弃信息,而是像人类阅读长文时那样,学会了速读与精读的结合。
该架构由两个精密配合的组件构成:闪电索引器(Lightning Indexer)与细粒度Token选择机制(Fine-grained Token Selection Mechanism)。
闪电索引器充当了全局雷达的角色。
它被设计得极其轻量化,仅拥有少量的注意力头,并采用FP8低精度计算与ReLU激活函数。
这种设计使得索引器能够以极低的算力成本,快速扫描整个上下文,计算出当前查询(Query)与历史信息之间的关联性评分。它不负责深入理解,只负责快速定位。
一旦雷达锁定了高价值区域,细粒度Token选择机制便接管后续工作。
它利用Top-k算法,仅检索那些评分最高的键值对(Key-Value)进行精细计算。
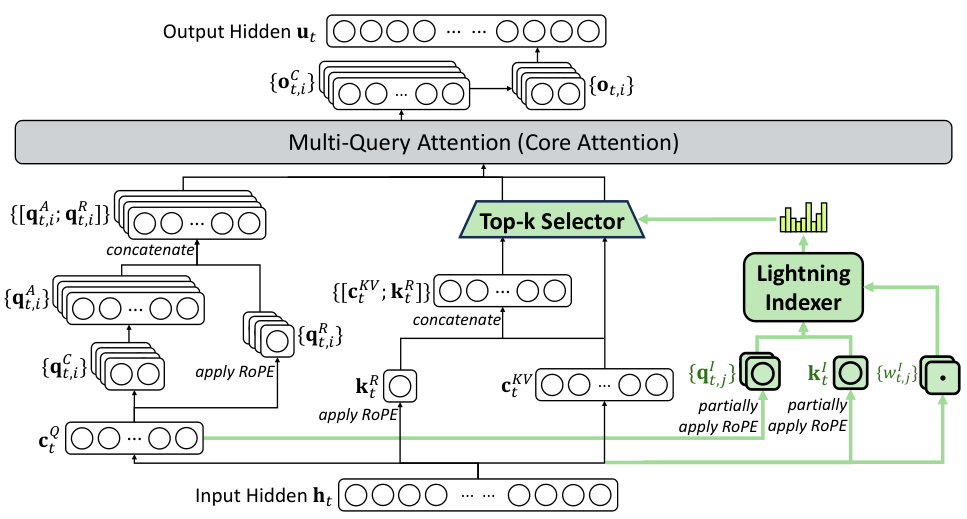
为了将这一理论落地,DeepSeek基于其独有的MLA(多头潜在注意力)架构进行了实例化。
通过采用MQA(多查询注意力)模式,让每个潜在向量在所有查询头之间共享,进一步压缩了内存占用。
DSA的训练过程本身就是一种艺术。团队设计了密集预热与稀疏训练两个阶段。
在预热阶段,模型保持全量注意力的开启状态,但冻结除索引器外的所有参数,强行让这个雷达去模仿主模型的注意力分布。
随后进入稀疏训练阶段,模型正式切换到筛选模式,全面优化参数以适应这种新的阅读习惯。为了保证雷达的客观性,索引器的训练信号被独立出来,不受主模型语言建模损失的干扰。
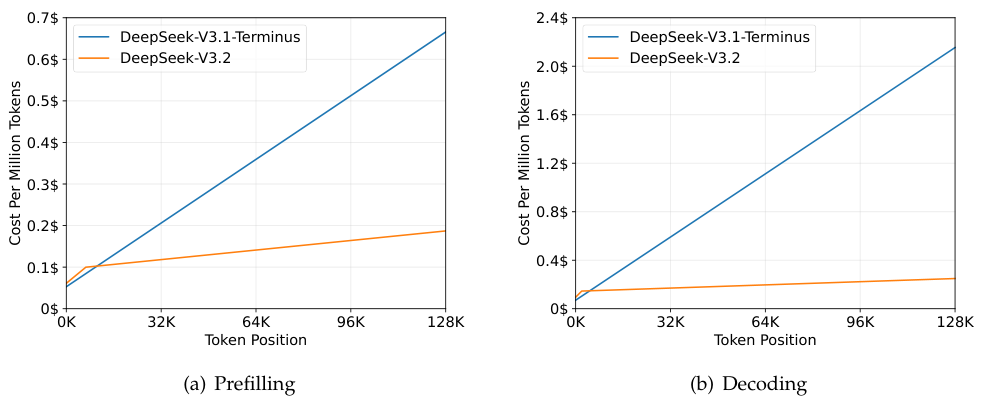
实际部署中的收益是惊人的。随着处理序列长度的拉长,DeepSeek-V3.2的推理成本曲线显得格外平缓,与上一代模型形成了鲜明对比。
这不仅意味着更低的API调用价格,更意味着在处理书籍级或代码库级长文本时,用户不再需要忍受漫长的等待。
后训练阶段的算力饱和式轰炸
DeepSeek-V3.2之所以能在逻辑推理上取得突破,很大程度上归功于其在后训练(Post-Training)阶段的激进策略。
DeepSeek将后训练阶段的计算预算提升到了预训练成本的10%以上。这多出来的算力,全部被用于强化学习(RL),旨在通过大规模的试错与反馈,将模型从懂知识进化为会思考。
团队沿用了GRPO(组相对策略优化)算法,并针对大规模训练中出现的稳定性难题,开发了一套独特的稳定机制。
在强化学习中,KL散度(Kullback-Leibler Divergence)通常被用来限制新策略偏离旧策略太远,以防止模型学傻了。
然而,传统的估计方法在处理低概率事件时极不稳定,容易产生巨大的梯度波动,导致训练过程像过山车一样震荡。
DeepSeek引入了无偏KL估计,通过数学上的修正,消除了系统性误差,使得梯度更新变得平滑而稳健。
在数学证明等对逻辑严密性要求极高的领域,团队甚至发现,适当减弱KL惩罚,允许模型更大胆地探索解题路径,反而能激发出更强的智力。
异策略序列掩码是另一项关键技术。
在强化学习的数据生成过程中,模型在不断进化,导致生成数据的策略与当前优化的策略往往不同步。
当模型生成了一些质量极差、且与当前策略差异巨大的样本时,这些数据不仅没有参考价值,反而会误导模型的学习方向。
DeepSeek设计了一个智能掩码,能够自动识别并屏蔽这些离谱的负面样本,确保模型只从有价值的错误中吸取教训,而不是被随机噪声带偏。
针对混合专家模型(MoE)特有的路由不稳定性,团队实施了保持路由策略。
它强制模型在训练时激活的专家路径与推理采样时保持一致,防止了参数更新时的目标漂移。配合保持采样掩码技术,确保了训练与推理在概率截断逻辑上的统一,维护了语言生成的连贯性。
正是这些看似枯燥的底层算法改进,支撑起了DeepSeek-V3.2在高难度推理任务上的稳定表现,使其能够在数千步的强化学习中持续进化,而不陷入崩溃或退化。
智能体在工具使用中学会思考
在智能体(Agent)领域,开源模型长期面临着手脑分离的窘境。
过去,当模型需要调用外部工具(如搜索、代码解释器)时,往往会中断当前的思维链,直接输出工具调用指令。
一旦工具返回结果,模型之前的推理上下文通常会被丢弃,导致它在面对多步复杂任务时,经常忘记自己刚才推导到了哪一步,不得不重新思考。
这种断裂感是导致开源智能体泛化能力弱、指令遵循差的根本原因。
DeepSeek-V3.2是DeepSeek推出的首个将思考(Thinking)与工具使用(Tool-Use)深度融合的模型,创造性地提出了一套上下文管理机制。
在这个新范式中,模型在调用工具时,其思维过程不会被打断或丢弃。
只有当用户输入新的指令时,历史的推理内容才会被清理;而如果是工具返回了执行结果,之前的推理轨迹会被完整保留。
这就像是一个经验丰富的工程师,在查阅手册或运行代码时,脑子里的解题思路始终是连贯的,不会因为翻了一下书就忘记了要解决什么问题。
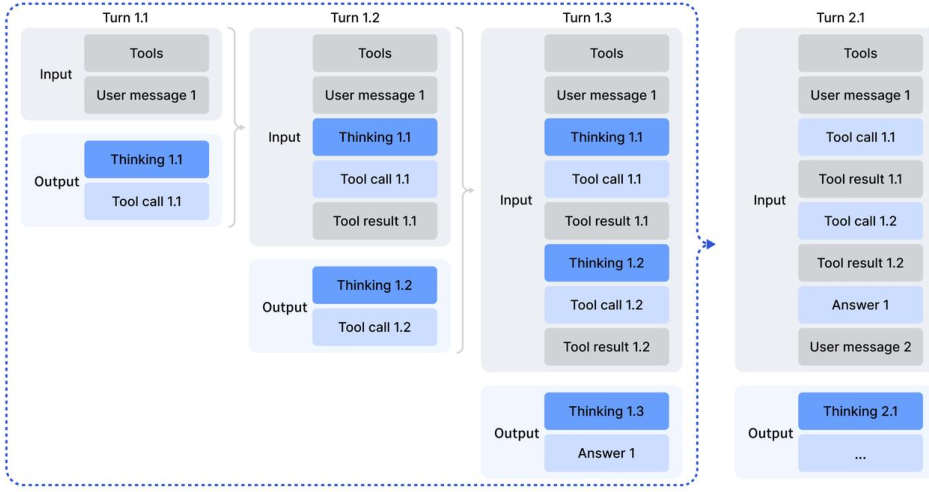
为了解决训练数据稀缺的问题,DeepSeek构建了一套庞大的智能体任务合成流水线,通过左右互搏的方式,凭空制造出了海量高质量训练数据。
在搜索智能体场景下,团队利用多智能体系统,从海量网页中挖掘长尾实体,自动构建问答对。
一个智能体负责提问,多个智能体负责生成不同质量的答案,再由一个具备搜索能力的验证智能体进行多轮核查,确保只有那些真的很难、且答案唯一的样本进入训练集。
在代码智能体领域,团队挖掘了GitHub上数百万级的Issue与Pull Request数据,构建了真实的可执行沙盒环境。
通过自动化测试框架,验证模型生成的代码补丁是否真正解决了问题且未引入新Bug。这种基于真实执行反馈的训练,远比单纯的文本模仿要有效得多。
针对通用任务,DeepSeek设计了一个能够自动合成环境智能体。
它首先利用基础工具在沙盒中生成数据,然后编写专属的工具函数,最后构造出只有通过这些工具才能解决的复杂任务。
这是一个自我进化的过程,如果生成的任务太简单或无法验证,智能体就会不断修改,直到产出高质量的题目。
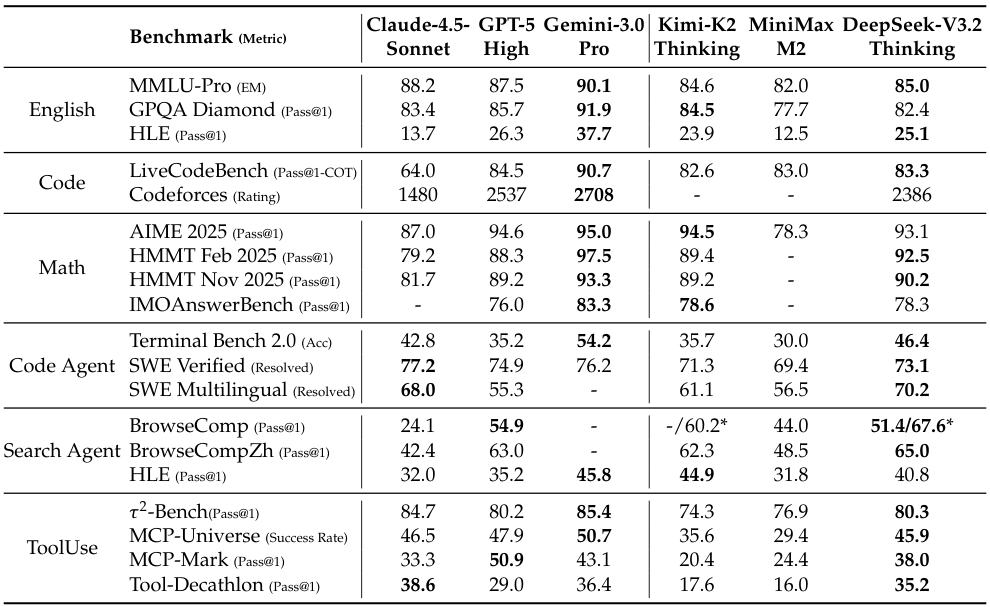
表中的数据展示了这一策略的巨大成功。DeepSeek-V3.2在各类智能体工具调用评测集上的得分,不仅横扫了开源界,更大幅缩小了与闭源顶尖模型的差距。
值得注意的是,V3.2在这些测试中并未针对特定工具进行过拟合训练,其优异表现完全源自于在合成数据海中练就的泛化能力。
这意味着,在真实世界那些千奇百怪的应用场景中,DeepSeek-V3.2能够依靠通用的逻辑与思考能力,灵活适应各种未见过的工具与任务。
尽管在绝对的世界知识广度上,受限于预训练算力总量,它与Gemini-3.0-Pro等最强闭源模型仍存差距,但在逻辑、数学、代码与智能体等核心硬核能力上,DeepSeek已经证明了开源模型完全具备冲击人类智力巅峰的资格。
参考资料:
https://huggingface.co/deepseek-ai/DeepSeek-V3.2
https://huggingface.co/deepseek-ai/DeepSeek-V3.2-Speciale
https://chat.deepseek.com/
END

















 444
444

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









