



刚刚,全球首个AI外教一对一产品斑马口语的正式上线,标志着人工智能在教育领域的角色正发生根本性转变,它不再仅仅是辅助工具,而是开始成为教学过程的主导者。(应用商店可下载)
这场变革并非一日之功,背后是AI教育范式从纯文本交互到可视化教学的跃迁,是评测体系从单纯的知识考核到知识与育人并重的深刻反思,最终才催生出能够产业化落地的AI教师产品。
AI教师学会了动手教学
人工智能在教育领域的探索已持续数十年,从简单的问答系统演进到今天的大语言模型。这些工具在知识传递上表现出色,却始终存在一个根本局限,它们主要通过文本与人交流。
这种单一的信息传递方式,在处理语言、历史等人文学科时尚可应对,但在科学、技术、工程和数学(STEM)等学科的教学中则显得力不从心。
复杂的数学公式、抽象的物理定律、动态的编程过程,都难以用纯粹的文字清晰、直观地传授。
开源ChatTutor的出现,就是要打破这一僵局。
它是一个集成了电子白板功能的AI教师系统,让AI第一次拥有了动手的能力。
这个系统将现实教学中的粉笔、画板、尺规等工具数字化,赋予AI一种全新的表达维度,实现了从说教到演示的跨越。
ChatTutor的技术心脏是其创新的多代理(Multi-agent)架构。
这一设计将复杂的教学任务分解。
其中,一个名为Agent的代理负责与用户进行流畅的对话沟通,如同班级里的主讲老师。
而另一个名为Painter的专家代理,则专注于在电子白板上进行专业的数学图形绘制,扮演着板书助教的角色。
这种明确的分工协作,确保了ChatTutor能够同时进行高质量的口头讲解和精确的图形绘制,实现了边讲边画的教学模式,无限趋近于人类教师的真实授课场景。
基于此架构,ChatTutor构建了一个覆盖多个学科领域的智能教学引擎矩阵。
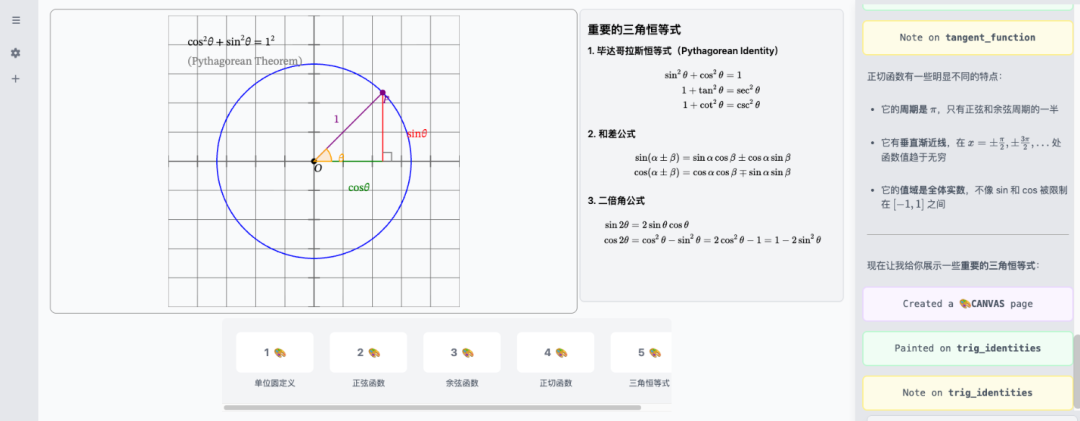
它的数学画板(Math Canvas)功能,可以一键生成函数图形、几何图形和统计图表。
当用户询问如何平移二次函数时,AI不再仅仅是输出一段文字解释,而是在画板上实时绘制出曲线,清晰地标记出顶点,并通过动画直观地演示整个变换过程。抽象的数学知识因此变得具体可见。
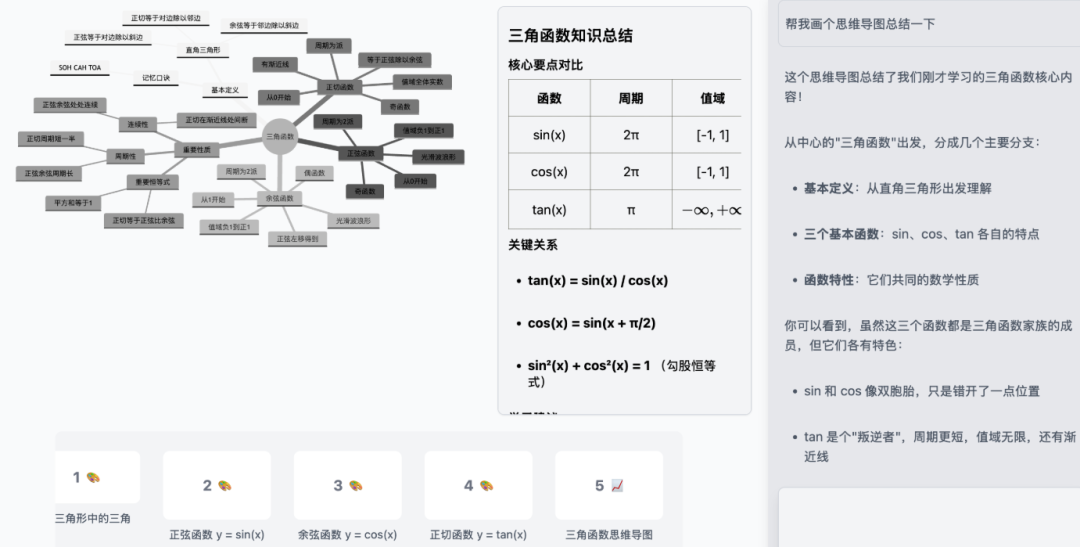
它的思维导图(Mindmap)功能,能够将复杂的概念体系自动结构化,一键生成清晰的知识图谱,帮助学生梳理脉络,建立系统性的认知框架。
正在开发中的代码页面(Code Page),将支持Python和JavaScript等主流编程语言,实现逐行编程教学。
AI会在编写代码的同时,同步解释每一行代码的执行过程,甚至模拟错误调试,这对于计算机科学初学者至关重要。
同样在开发中的物理画板(Physics Canvas),将能够即时绘制力学中的受力分析图、物体的运动轨迹、波的传播形态等。
在讲解牛顿第二定律在斜面运动中的应用时,ChatTutor可以先绘制出斜面,然后精确地标记出重力、支持力、摩擦力,并将重力分解为沿斜面和垂直斜面的两个分力,再用不同颜色的矢量和变量,一步步推导出最终的加速度公式。
整个过程逻辑清晰、节奏分明,远非传统AI助手粘贴答案的冰冷体验可比。
此外,数字逻辑画板(Digital Logic Canvas)和AI自动生成题目与解答等功能也在规划中,它们将分别服务于数字电路教学和个性化练习场景。
ChatTutor与传统聊天机器人的差异,是教学理念的根本不同。
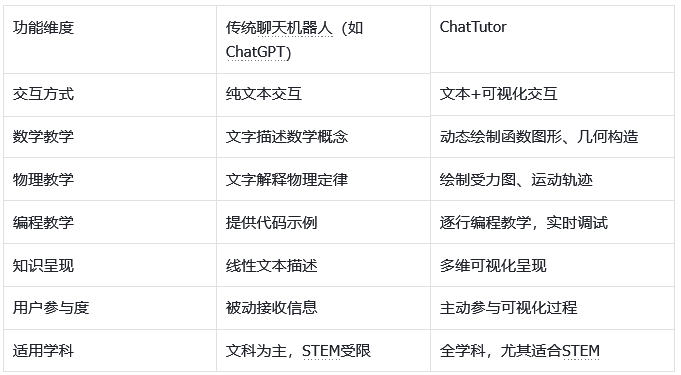
传统AI教育工具的核心在于知道如何回答问题,它们的逻辑是匹配知识库并生成最准确的答案。
而ChatTutor的核心在于知道如何去教学,它首次将教学法(pedagogy)融入AI系统的内核。
它通过视觉引导、步骤分解和交互反馈,去模拟人类教师那种启发式的、循循善诱的教学方式。
这不仅极大地提升了学生的理解效率,更有助于培养其结构化、逻辑化的思维能力。
这一转变的技术基石,是多模态生成与实时同步绘制。AI不再仅仅处理和生成文本,而是能够协同生成文本、图形、公式等多种模态的内容,并确保这些内容在对话过程中实时、同步地呈现与变化。
这种讲解、绘制、推导同时进行的体验,无限接近了人类教师的自然教学形态。
重新定义AI教育的及格线
当AI教师具备了更强大的教学工具后,一个新的问题随之而来:我们该如何科学、全面地评估它的教学水平?
教育,从来不只是知识的单向传递,更包含着思维启发、情感支持、价值观引导等复杂的育人功能。一个只会解题的AI,算不上一个合格的老师。
现有的评测基准,尤其是在中文教育领域,普遍存在两大局限:维度单一,且严重忽视育人能力。
例如,C-Eval是中国首个全面的评估套件,包含了从初中到专业水平的52个学科的13,948道多选题。
它在评估模型的知识储备和推理能力方面做得很好,但其评估范围基本局限在知识维度内,题型也相对单一。
另一个国际知名的基准MMLU(Massive Multask Language Understanding),涵盖了57项任务,同样以多选题为主,旨在评估模型广泛的知识和问题解决能力。
它在推动模型进步、标准化比较方面意义重大,但它依然聚焦于知识本身,并且主要针对英文环境,未能充分考虑中文教育特有的语言文化和教学实践。
这些基-准就像一张只考理论知识的试卷,无法衡量一个老师在课堂互动、启发学生、处理偶发事件时的综合素养。
为了解决这一问题,华东师范大学, 浙江大学 ,帝国理工学院的研究团队推出了OmniEduBench,一个专为评估中文大模型综合教育素质而设计的全新基准。

OmniEduBench的核心创新在于其独特的双维度评估体系,它像一张更科学的考卷,同时设置了知识和育人两大考区。
知识维度(Knowledge Dimension)部分,包含18,121个条目,旨在全面考察模型的学科知识掌握程度。
它实现了从小学、中学、高中、大学到专业考试的全学段覆盖,囊括了人文历史、理工农医等41个不同学科,题型也扩展到单选、多选、填空、简答、案例分析、论述等11种常见类型,力求贴近真实的考试场景。
而育人维度(Cultivation Dimension)部分,则是OmniEduBench的精髓所在。
它包含6,481个条目,专注于评估模型在真实教学互动中的软实力。这一维度围绕思维与认知、个性化发展、情感与心理健康、品格与价值观等6大领域和20个具体教学主题展开。
在这里,模型面对的不再是标准化的知识题,而是复杂的情景题。
例如:有学生在参观烈士陵园时嬉笑打闹,我很生气,该怎么处理?
这类问题没有唯一正确答案,它考验的不是模型的知识储备,而是它的情商、价值观和教育智慧。
OmniEduBench的构建过程极为严苛,以确保其高质量与高挑战性。
研究团队首先从公开数据、内部试卷以及利用LLM生成等渠道,收集了超过92万条原始数据。随后,通过结构化清洗、去重去敏,留下了约65万条。
为了避免模型仅仅通过背题获得高分,团队采用了两款强大的模型进行对抗式筛选。
先用一个模型过滤掉它能轻易答对的简单题,再用一个更强的模型进行二次筛选,只保留那些极具挑战性的高难度样本。
最后,所有留下的题目都由50位硕士生和5位资深教育专家进行最终的人工审核与质量校验,最终形成了24,602个高质量问答对的终版基准。
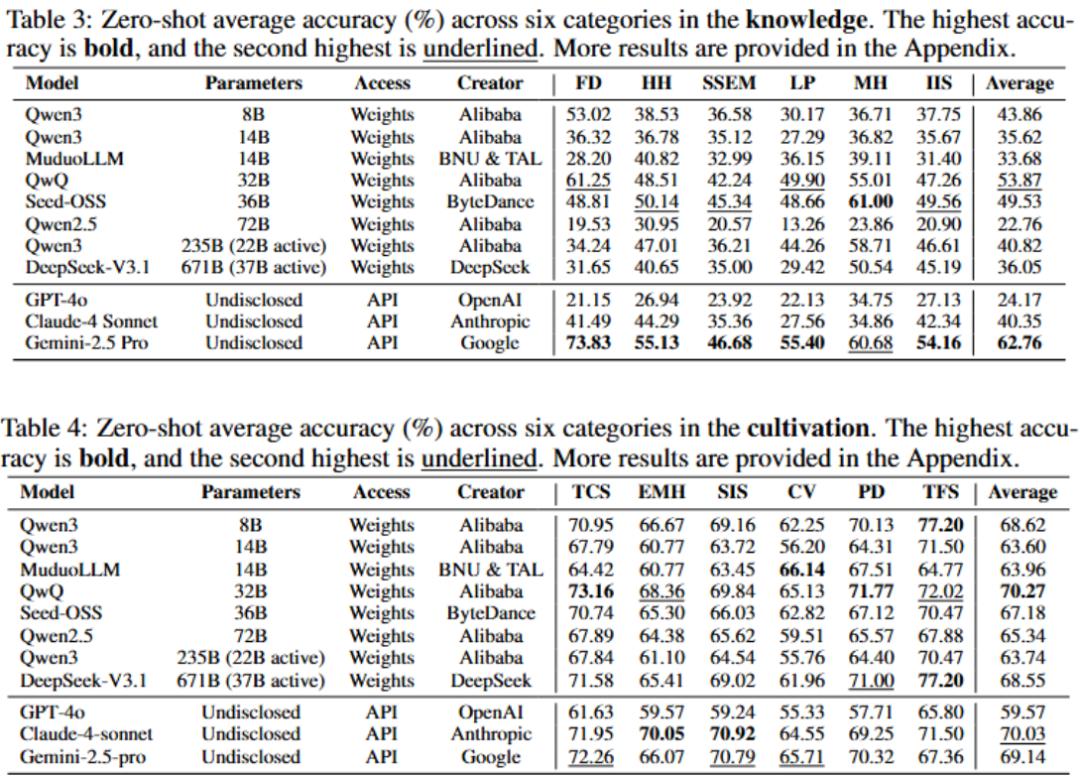
研究团队使用OmniEduBench对包括GPT-4o、Gemini-2.5 Pro在内的11个主流大模型进行了全面测试,结果揭示了当前AI教育能力的真实图景。
在知识维度上,只有Gemini-2.5 Pro的平均准确率超过了60%。
令人意外的是,强大的GPT-4o在该项测试中表现不佳,准确率仅为24.17%,远低于多个顶尖的开源模型。
这或许表明,国际顶尖模型在处理多样化、本土化的中文教育考试题目时,存在明显的水土不服现象。
在更关键的育人维度上,所有模型都暴露了短板。
尽管题目多为选择题,形式相对简单,但即便是表现最好的模型,其准确率也只有70.27%,与人类在该领域的普遍表现相比,仍有近30%的巨大差距。
这清晰地表明,当前的大语言模型在同理心、启发式引导等高级教育能力上普遍缺乏。
当测试进入到专设的高难度子集OmniEduBench HARD时,所有模型的性能都出现了断崖式下跌,即便是最强的模型,准确率也不足50%。
下表展示了各模型在OmniEduBench不同维度上的具体表现:
OmniEduBench的发布,为中文AI教育领域提供了一个急需的、更全面的评测视角。
它考验的不再仅仅是AI的解题能力,更是其在真实教育场景中的可用性和适配性,推动行业去关注模型在启发、反馈、共情等互动场景中的核心价值。
这个新基准清晰地揭示了当前大模型的短板:尽管模型在知识获取上取得了长足进步,但在实现教育的核心目标——育人方面,仍有很长的路要走。
AI教师走上产业化讲台
当AI的教学能力从理论走向可视化,评估标准也从知识走向育人,这项技术终于迎来了产业化落地的时刻。
2025年11月18日上线的斑马口语,正是这场变革的产物。
这款由斑马儿童科教集团(猿辅导旗下全资子公司)历时两年、投入超2亿元研发的产品,是全球首个真正意义上的AI外教一对一产品,专为6-12岁儿童的英语口语学习而设计。
它的出现,旨在解决真人外教在儿童口语学习中的诸多痛点,例如优质外教资源稀缺且昂贵、专业水平参差不齐、可能存在口音问题,以及很多孩子在面对真人外教时会感到紧张、害怕开口。
斑马口语的核心,是一个被称为超人类外教的AI Agent(人工智能代理)。
它以AI为教学主体,全程由AI驱动,能够独立完成从教学引入到知识讲解,再到互动练习和迁移应用的完整教学闭环。
这个超人类外教具备四大核心特性。
它拥有超人类的教学能力。
其背后是数以万计的顶尖人类教师的授课数据和教学智慧。
研发团队成员来自北京大学、北京师范大学、美国哥伦比亚大学等名校,持有CELTA、TESOL等专业认证。
AI外教能够实现音素级别的精准发音纠错,清晰地向孩子展示标准发音的口型与特点,其教学水平稳定且远超普通真人教师。
它拥有超人类的记忆力。
AI外教能精准记录孩子在每一节课上的表现,包括每一次开口、每一个知识点的掌握情况,甚至孩子的口头禅、兴趣爱好和性格特点。
系统会基于这些数据为每个孩子建立专属的成长档案,并通过深度推理,在后续课程中提供高度针对性的反馈与互动。这种极致的个性化,让孩子感到被理解和关注,从而更愿意开口表达。
数据显示,孩子在第一节课的前三分钟内开口率高达98.8%,在25分钟的课程里能完成超过100次的高质量表达。
它拥有超人类的知识储备。
依托于自研的猿力大模型,AI外教的知识库覆盖了学校、生活、旅行等各种真实场景,能够轻松应对6-12岁儿童提出的各种天马行空的问题,从为什么天空是蓝色的到讨论时下流行的卡通IP,它都能给出恰当的回应,并顺势引导孩子进行结构化的英文表达。
它还被赋予了超温暖的人格。
AI进化到了人格智能的阶段,被设计为具备耐心、真诚和尊重的特质。
它总能提供积极的反馈和及时的鼓励,为孩子创造一个低焦虑、高安全感的学习环境。在这种环境中,孩子能够轻松完成开口-被鼓励-再开口的积极正循环。
斑马口语的教学体系同样经过精心设计。
整个体系分为六个级别(L1-L6),遵循螺旋式上升的原则,适配不同英语基础的儿童。
其目标非常明确:学完最高级别L6后,学生的口语水平可以达到欧洲共同语言参考标准(CEFR)的B1级别,相当于剑桥英语PET考试的口语水平,也与国内新课标中考的口语要求相当。
每一单元课程都采用2+1+1的结构设计,包含2节场景对话、1节话题表达和1节综合运用。
从在模拟的商场中问路,到就某个话题发表结构化的观点,再到将所学知识灵活运用于全新的情境,整个学习过程旨在帮助孩子从会说,进步到说得清楚、说得完整。
这一切的实现,离不开强大的技术支撑。
技术核心是猿力大模型。
该模型于2024年通过国家备案,并在信通院的评测中获得5级认证,它为AI外教提供了强大的语言理解、教学执行和情感交互能力。
为了确保教学互动的自然流畅,团队将AI外教端到端的延迟压缩到了2.5秒以内,接近真人对话的节奏。
对于鼓励、确认等即时反馈,延迟甚至可以控制在1.5秒以内。
系统通过一个统一的时序编排引擎,协同语音、动画、手势、文字、特效等多模态元素,实现了边听边思考、边思考边说出来的沉浸式体验。
当AI外教说看这里时,它的手会指向相应的单词,同时画面上的单词也会同步高亮闪烁。
针对儿童口语学习的特殊性,团队专门训练了儿童发音识别模型,并设计了智能的语音断句策略,综合音频能量、静音时长和语义完整度三个维度来判断孩子是否说完了话,从而避免了误判和抢话。
在安全方面,系统建立了从模型训练数据源头把控,到上线前全面测试,再到运行中实时风控的三层防护体系,确保了教学内容的健康与安全。
斑马口语的上线,是AI大模型技术从通用探索走向垂直行业深度落地的一个标志性事件。
它验证了AI在教育领域的商业可行性,并为主导型AI Agent在其他垂直领域的应用,树立了一个可供参考的范本。
AI教师开始从幕后走到了台前。
最后附上一份开源礼包:国内所有小初高、大学PDF教材。开发者或许可以用来构建、训练、微调AI教育智能体呢!
https://github.com/TapXWorld/ChinaTextbook
免费体验:
https://chattutor.app/
参考资料:
https://github.com/sheepbox8646/ChatTutor
https://mind-lab-ecnu.github.io/OmniEduBench/
https://arxiv.org/pdf/2510.26422
https://github.com/remiMZ/OmniEduBench-code
END


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









