



上海巨人网络AI实验室(AI Lab, GiantNetwork)提出的YingVideo-MV框架,通过级联架构将音乐语义分析、导演级镜头规划与时间感知的视频生成模型结合,解决了传统音频驱动视频生成中运镜单一和长序列画面崩坏的难题,实现了具备精准口型、自然肢体与丰富运镜的高质量音乐视频生成。

数字人技术在音乐视频、Vlog和广告领域的应用价值日益凸显,但要让虚拟形象不仅是对口型,而是真正呈现出具有感染力的音乐表演,一直是业界的难点。
现有的模型大多只能保证面部表情和口型的同步,一旦涉及到复杂的运镜、场景调度以及长时间的连续表演,往往会出现画面单调、动作僵硬甚至人物身份特征丢失的问题。
真正的音乐视频不仅仅是画面的堆砌,它需要电影级的叙事语言,运镜的推拉摇移、景深的变换以及构图的节奏都必须与音乐的情绪严丝合缝。
针对这些痛点,YingVideo-MV并未停留在单一的模型优化上,而是构建了一个类似于人类剧组的级联工作流,引入了MV导演这一智能体概念,并配合专门设计的摄像机控制模块和长视频一致性策略,试图在AI生成的视频中复刻专业MV的制作水准。
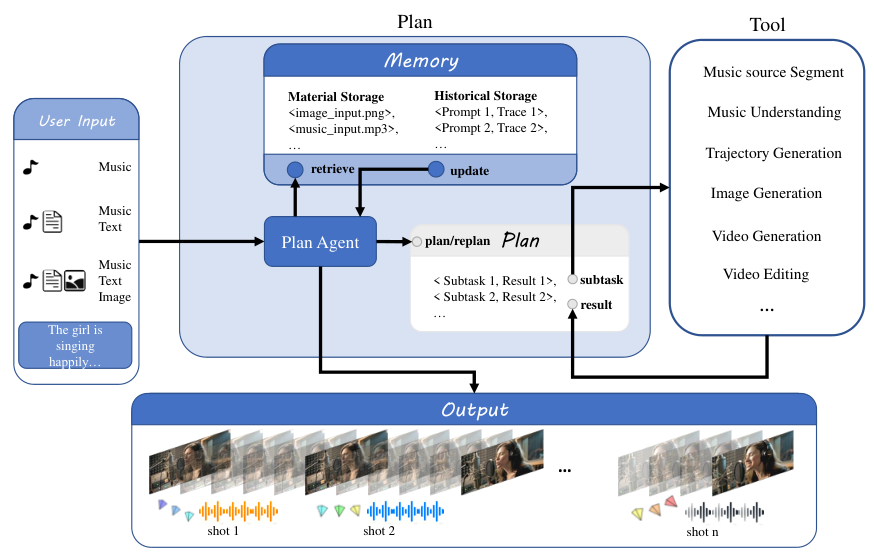
YingVideo-MV的核心逻辑被设计为一个顺序决策过程。
它不像传统模型那样直接从音频猜视频,而是分两步走:先想后做。
系统首先根据输入的音乐生成一份详尽的镜头列表,这份列表包含了每一段画面的构图、节拍点和角色运动模式。
有了这份蓝图,后续的视频生成模型就能并行地生成各个分镜头片段。
这些片段经过时间上的精细对齐和视觉上的平滑融合,最终组装成一部完整的音乐视频。
这种设计思路本质上是将复杂的长视频生成任务拆解成了可控的短片段生成与拼接任务,既保证了局部的细节质量,又维持了全局的叙事逻辑。
智能体化身的MV导演
整个框架的大脑是MV导演模块(MV-Director Module)。
它在一个由用户设定的高级目标环境中运行,这个目标可以是一个模糊的叙事意图,也可以是具体的视觉风格或情感基调。
为了达成这个目标,MV导演配备了一个功能丰富的工具箱,涵盖了音乐分析、场景规划、图像生成等多个环节。
它的工作不是简单的指令执行,而是像一个真实的导演一样进行统筹规划,将初始的素材转化为符合预期的最终成片。
音乐源分割是导演的第一项工作。
原始的音乐流必须被切分成语义完整的片段,系统通过迭代识别节拍起始强度的局部最大值来确定切割点。
这里遵循两个核心原则:一是按节拍剪辑(cut-to-the-beat),即场景的转换点必须落在强拍上,以保证视觉节奏与听觉节奏的同步;二是场景的持续时间通常与音乐的小节长度相关。
系统计算出的平均片段时长近似于一个音乐小节,这一数值与每分钟节拍数(bpm)紧密挂钩,从数学上保证了视频剪辑的音乐性。
在理解音乐内容方面,YingVideo-MV借鉴了多模态大语言模型(MLLMs)的能力,采用了Qwen 2.5-Omni作为核心引擎。
这个模型不仅能听出音乐中的歌词内容,还能精准捕捉音乐片段中的情感属性。
它将提取到的转录文本和情感标签映射到一个共享的语义空间中,为后续的画面生成提供高级控制信号。
摄像机轨迹的设计是MV导演的另一项绝活。
运镜不仅是视角的改变,更是叙事的手段。
该模块会依据场景的具体内容和脚本级的指导,生成平滑且符合上下文逻辑的摄像机运动路径。
它不再依赖于简单的几何启发式算法,而是结合了电影摄影建模的最新进展,确保生成的运镜不仅在物理上是连贯的,在艺术上也是服务于叙事的。
镜头取景的选择、深度的转换以及镜头间的衔接,都在这一阶段被精细规划,为最终的成片奠定了电影质感的基础。
视频生成模型的骨架与感知
在导演完成了规划之后,具体的执行任务交给了视频生成(S2V)模块。
这一模块建立在WAN 2.1框架之上,采用了全时空注意力的Transformer架构(DiT)。
它的任务是将导演的意图转化为具体的像素,同时处理好音频、图像和文本之间的复杂关系。
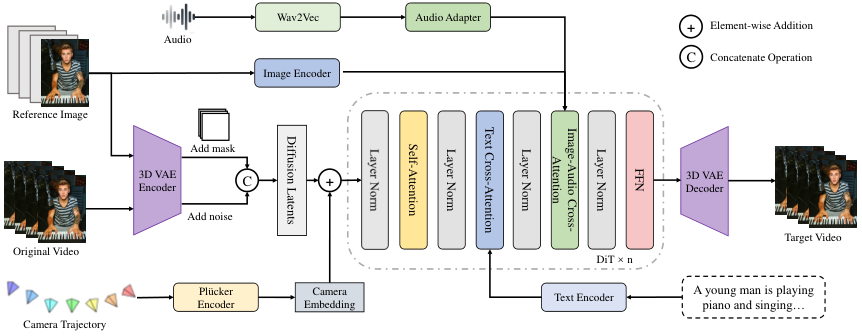
为了让模型听得更准,音乐音频输入首先通过Wav2Vec提取音频嵌入。
由于预训练模型可能存在分布不匹配的问题,这些嵌入还会经过StableAvatar的音频适配器进行微调优化。
优化后的音频特征被送入去噪管道,成为视频生成的重要条件。
对于视觉参考图像,系统设计了两条处理路径:一条路径通过时间轴填充和3D VAE编码器处理,将潜在编码与压缩视频帧及二进制掩码连接;另一条路径则利用CLIP图像编码器生成图像嵌入,并在每个图像-音频交叉注意力块中注入。
精准的运镜控制是YingVideo-MV的一大亮点。
为了让AI理解摄像机的运动,研究团队采用了Plücker嵌入来表示摄像机位姿。
相比于传统的坐标表示,Plücker嵌入提供了更强的几何解释性和细粒度的像素级编码。
对于视频中的每一帧,系统都会计算其对应的Plücker嵌入,从而形成一个完整的轨迹序列。
为了将这些几何信息有效地注入到扩散模型中,系统设计了一个专门的摄像机适配器(Camera Adapter)。
这个适配器由PixelUnshuffle、Conv2d和ResidualBlock层组成,它的作用是将摄像机嵌入投影为与噪声潜在变量形状匹配的张量。
随后,这些投影信息通过逐元素相加的方式直接融合进潜在变量中。
长视频的连贯性与人类偏好对齐
生成几秒钟的视频容易,但要生成长达数分钟且画面不崩坏的视频却很难。
为了解决长序列生成中的一致性问题,YingVideo-MV提出了一种时间感知动态窗口范围策略(Timestep-aware Dynamic Window Range Strategy)。
传统的长视频生成方法,如滚动策略或简单的重置去噪,往往会导致帧与帧之间缺乏重叠,或者因为上下文信息的丢失而产生视觉突变。
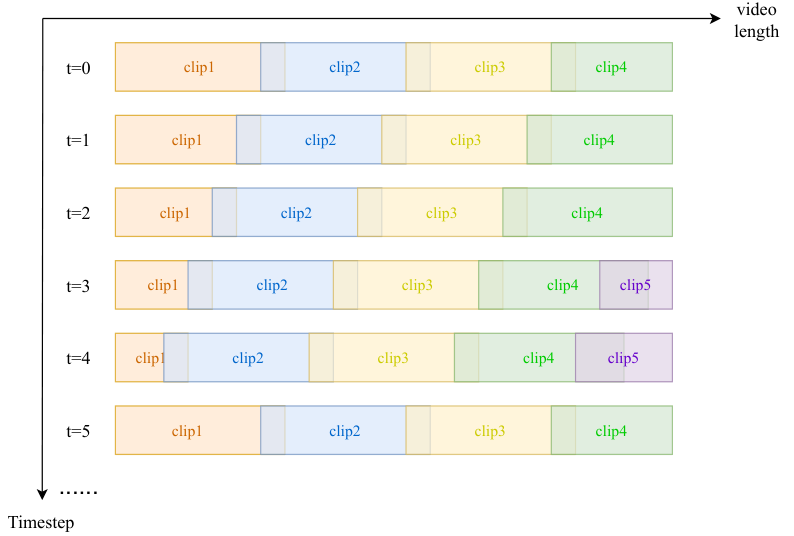
YingVideo-MV的策略包含两个嵌套循环:外循环负责逆扩散过程,内循环负责滑动窗口处理。
与固定步长的滑动不同,该策略在每个时间步都会动态调整每个剪辑的位置和长度。
系统特别关注首尾剪辑的处理。随着时间步的推移,第一个剪辑的有效帧数可能会急剧减少,导致生成质量下降。
为此,系统设定了一个阈值,一旦首剪辑长度收缩过短,下一个时间步的起始偏移量就会重置。
同理,最后一个剪辑如果过短,系统会将其向前扩展,增加与前一个剪辑的重叠帧数。
除了技术上的连贯性,视频的美学质量也至关重要。
为了让生成的视频更符合人类的审美,YingVideo-MV引入了直接偏好优化(DPO)。
在训练阶段,系统会为每个样本随机选择四个视频片段,并计算三个关键指标:基于SyncNet的唇形同步置信度(Sync-C)、手部质量奖励分数以及VideoReward分数。
通过加权聚合这些指标,系统能够区分出首选样本和非首选样本。
DPO的训练目标是最大化首选输出的似然性,同时限制模型偏离参考策略。
研究团队采用了基于流匹配速度场(velocity field)的损失函数形式,让模型预测的速度场尽可能接近首选样本,远离非首选样本,并保持与参考模型的时间动态一致性。
数据实证与性能表现
任何强大的AI模型背后都离不开高质量数据的支撑。
YingVideo-MV的训练建立在一个庞大的数据集之上,第一阶段使用了约1500小时的通用视频数据,涵盖了单人面部和身体的表演;第二阶段为了强化音乐表演的表现力,特意加入了400小时的特定领域数据,包括专业歌手和虚拟头像的高质量音视频同步录制。
实验采用Wan2.1-I2V-14B作为基线模型,并在64块NVIDIA A800-80G GPU上进行了训练。
为了全面评估模型性能,研究团队使用了HDTF、CelebV-HQ、EMTD等多个数据集,并引入了专门的摄像机运动数据集MultiCamVideo。
评估指标涵盖了视觉质量(FID)、时间一致性(FVD)、口型同步(Sync-C/Sync-D)、身份保存(CSIM)以及摄像机运动精度(RotErr/TransErr)。
定量对比显示,YingVideo-MV在各项关键指标上均优于现有的同类模型。
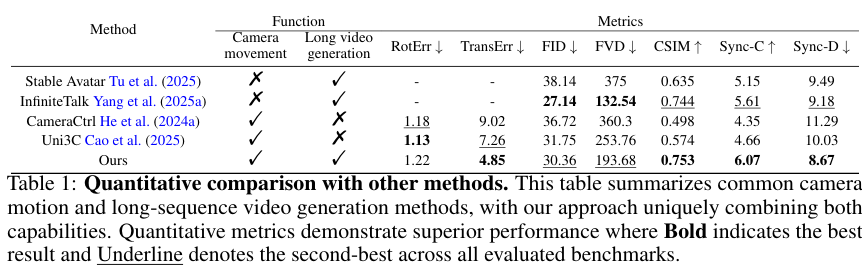
在视觉质量和时间一致性方面,FID得分为30.36,FVD得分为193.68。
虽然InfiniteTalk在FID/FVD数值上略低,但那是通过牺牲摄像机运动、仅优化局部唇部区域换来的。
相比之下,YingVideo-MV在包含复杂运镜的全画面生成任务中,依然保持了极高的画质和连贯性,这在技术难度上是完全不同的量级。
在摄像机控制精度上,YingVideo-MV的平移误差仅为4.85,显著优于CameraCtrl(9.02)和Uni3C(7.26),证明了其对摄像机轨迹的还原更为精准自然。
同时,Sync-C(6.07)和Sync-D(8.67)的优异成绩,也验证了模型在多模态时间对齐上的强大能力。
用户研究的结果进一步佐证了客观数据的结论。

20名参与者对15个生成视频进行了盲测评分,结果显示YingVideo-MV在摄像机运动的流畅性、口型同步准确性、角色动作自然度以及整体视频质量上,均取得了统计学意义上的显著优势。
目前的框架面对非人类实体,例如多肢体或非生物结构的奇幻生物,由于几何和纹理的极端复杂性,模型在合成新颖形状时仍显吃力。
此外,对于多角色互动的复杂场景,模型在处理人际空间推理和行为协调方面还有待提升。
这也指明了未来的进化方向:支持多角色交互式音乐视频(MC-MV),让AI不仅能导演独角戏,也能调度群像剧。
YingVideo-MV通过将导演思维注入AI,用严谨的数学模型量化艺术的运镜与剪辑,为自动化音乐内容创作开辟了一条兼具工业标准与艺术表现力的新路径。
参考资料:
https://giantailab.github.io/YingVideo-MV/
https://github.com/GiantAILab/YingVideo-MV
END


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









