



近日,一则关于华为昇腾或从 NPU 转向 GPGPU 架构的消息引发了广泛关注,也让不少人感到意外。
今天我们就来聊聊,国产AI芯片技术架构这个话题。
看到很多报道都在说“国产AI芯片取得了重大突破"、“性能接近国际先进水平"之类的套话,很少有人真正深入分析一个根本性问题:
国产AI芯片到底该走什么技术路线?
是跟随NVIDIA的GPGPU路线,还是走谷歌TPU那样的ASIC路线?这个问题看似技术性很强,但实际上关系到整个中国AI产业的未来命运。
回到开头,华为昇腾从NPU转向GPGPU架构这个消息如果属实,那将是一个重大转折。因为这意味着华为这个国内AI芯片的头部厂商,可能要放弃自己坚持多年的技术路线,转向一个全新的方向。
为什么这个消息如此重要?因为这就好比在汽车行业,一家坚持电动汽车路线的公司突然宣布要转向燃油车——这不是简单的技术调整,而是战略方向的根本性改变。
但更让我困惑的是,当我深入了解后发现,国产AI芯片厂商在这个问题上已经分裂成了两个截然不同的阵营:
一边是以海光、摩尔线程、沐曦为代表的GPGPU阵营,另一边是以寒武纪、华为昇腾、燧原科技为代表的ASIC阵营。
这场技术路线之争,不仅仅是技术层面的选择,更是对中国AI未来发展路径的根本性抉择。
GPGPU vs ASIC:两种截然不同的技术哲学
要理解这场争论的本质,我们首先要搞清楚什么是GPGPU,什么是ASIC。
GPGPU(通用图形处理器),说白了就是把原本用于游戏画图的GPU,拿来干通用计算的活。NVIDIA就是这个路线的绝对王者,其CUDA生态已经成为了AI领域的“普通话"。
GPGPU的优势是什么?通用性强、生态成熟。就像一把瑞士军刀,什么活都能干,而且有大量的现成工具和教程。但劣势也很明显:功耗高、成本昂贵。就像开着法拉利去送快递,虽然能送到,但成本太高。
ASIC(专用集成电路)则是完全不同的思路。它不为通用性设计,而是为特定任务量身定制。就像专门用来送快递的电动车,虽然干不了别的活,但送快递的效率极高。
ASIC在AI领域的典型代表就是谷歌的TPU,以及国内的华为昇腾、寒武纪等。它们的优势是峰值算力极致、功耗低、成本低,但劣势是灵活性差。一旦AI模型架构发生重大变化,芯片可能就无法充分适配。
以下是一个更直观的对比:
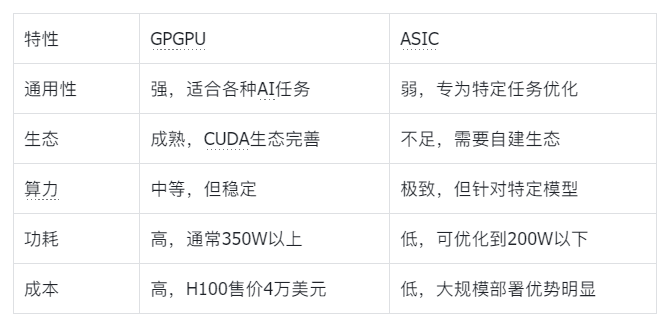
看到这个对比,你们可能会问:既然GPGPU这么好,为什么还有人选择ASIC?
答案很简单:成本和效率。
在大规模AI推理场景中,ASIC的成本优势是压倒性的。据业内人士透露,同样算力的ASIC芯片,成本可能只有GPGPU的三分之一,功耗更是只有五分之一。
这就是为什么谷歌、亚马逊、微软这些科技巨头都在自研ASIC芯片的原因。它们每天要处理数以亿计的AI推理请求,如果都用NVIDIA的GPU,成本将是天文数字。
国产AI芯片厂商的“站队”之谜
理解了GPGPU和ASIC的区别,我们再来看看国内厂商是如何“站队”的。
GPGPU阵营主要包括:
-
海光信息(DCU系列):背靠中科院,技术来源AMD,算是国内GPGPU的"正规军"
-
摩尔线程:成立于2020年,创始人来自NVIDIA,号称要做"中国的NVIDIA"
-
沐曦(C系列):相对低调,但产品已经在部分国有银行投入使用
ASIC阵营则更加庞大:
-
寒武纪(思元系列):AI芯片"第一股",头部厂商,技术实力雄厚
-
华为昇腾:国内AI芯片的大哥,从昇腾910到最新的910D,性能不断提升
-
燧原科技:专注于云端AI训练和推理,产品性能不俗
-
百度昆仑:百度自研,主要用于自家搜索和AI业务
-
阿里平头哥:阿里巴巴旗下,主打端侧AI芯片
-
腾讯紫霄:腾讯与燧原合作,用于腾讯云AI服务
看到这个名单,你们可能会发现一个有趣的现象:互联网巨头几乎都选择了ASIC路线,而专业芯片厂商则更倾向于GPGPU路线。
为什么会这样?
答案其实很简单:需求不同。
互联网巨头们有大量的、特定的AI应用场景,比如百度的搜索、阿里的电商推荐、腾讯的游戏AI等。这些场景相对固定,用ASIC进行专门优化,可以大幅降低成本。
而专业芯片厂商则需要面对更广泛的市场,不可能为每个客户都定制芯片,所以GPGPU的通用性优势就体现出来了。
但这里有一个悖论:既然互联网巨头都选择了ASIC,为什么它们还要大量采购NVIDIA的GPU?
答案更是耐人寻味:因为AI技术发展太快了。
今天的AI模型,可能明天就被淘汰了。如果投入巨资研发ASIC芯片,结果模型基础架构一变,芯片就可能变成一堆废铁。而NVIDIA的GPU则不同,无论AI模型怎么变,它都能用。
这就是为什么即使谷歌有了TPU,微软有了Athena,亚马逊有了Inferentia,它们依然要大量采购NVIDIA的GPU。
生态之战:CUDA的“霸权”与国产芯片的困境
说到这里,我们不得不提到一个绕不开的话题:CUDA生态。
CUDA是NVIDIA推出的并行计算平台,经过十多年的发展,已经成为了AI领域的"事实标准"。几乎所有的AI框架、工具、应用都基于CUDA开发。
这就造成了一个尴尬的局面:即使国产AI芯片在硬件性能上达到了NVIDIA的水平,但在生态上依然被远远甩在后面。
为什么生态这么重要?
因为AI不是简单的硬件比拼,而是一个完整的系统工程。从模型训练、优化到部署,每一个环节都需要大量的软件工具支持。没有这些工具,再好的硬件也只是摆设。
举个例子,假设你是一家AI公司,开发了一个新的AI模型。用NVIDIA的GPU,你可以直接调用CUDA的各种优化库,轻松实现性能最大化。但如果用国产芯片,你可能需要自己编写大量的底层代码,甚至需要修改模型架构来适应芯片。
这种成本差异,是大多数企业无法承受的。
但更让人担忧的是,CUDA生态还在不断强化。NVIDIA通过收购、投资、合作等方式,已经构建了一个涵盖芯片、软件、框架、应用的完整生态系统。这个生态系统就像一个巨大的漩涡,把越来越多的AI公司和开发者卷入其中。
国产芯片厂商想要打破这个局面,只有两条路:
第一:兼容CUDA。也就是让国产芯片能够运行CUDA程序。但这在技术上极其困难,因为CUDA紧密结合了NVIDIA的GPU架构。而且即使技术上可行,也会面临专利诉讼的风险。
第二:自建生态。也就是打造自己的编程平台和工具链。这条路更艰难,因为需要巨大的投入和长期的积累。华为的CANN、寒武纪的CNML都是这方面的尝试,但与CUDA相比还有很大差距。
这就是为什么最近有消息称华为昇腾可能转向GPGPU架构。如果这个消息属实,那可能意味着华为在自建生态的道路上遇到了难以逾越的障碍,不得不选择“曲线救国"的策略。
国际视角:全球AI芯片格局的变化
把视野放到全球,我们会发现GPGPU与ASIC之争不仅仅是中国的现象,而是全球性的趋势。
根据McKinsey的最新报告,到2030年,采用ASIC芯片的AI加速器将处理大部分工作负载,因为它们在特定AI任务中表现更优。
这个预测与当前的市场格局形成了鲜明对比。目前,GPU在全球AI芯片市场占据主导地位,2024年市场规模达到1000亿美元。但ASIC正在快速增长,预计到2030年将实现大幅增长。
这种变化背后,是大型科技公司对成本和效率的极致追求。
以谷歌为例,其TPU在处理特定AI任务时,性能比NVIDIA的GPU高出3-5倍,成本却只有三分之一。这就是为什么谷歌宁愿投入巨资自研TPU,也要减少对NVIDIA的依赖。
同样,微软、亚马逊、Meta等公司也在加紧自研ASIC芯片。据业内消息,Meta正在研发一款代号为“Artemis”的ASIC芯片,旨在减少对NVIDIA GPU的依赖。
但有趣的是,这些公司在自研ASIC的同时,依然在大量采购NVIDIA的GPU。这说明它们也意识到,在AI技术快速迭代的背景下,完全依赖专用芯片是有风险的。
这种“两条腿走路”的策略,可能也是国产AI芯片厂商需要学习的。
分歧与共识
在这场技术路线之争中,国内的专家学者们也有着不同的见解。
尹首一教授:技术路线多元化是中国的优势
清华大学微电子学研究所副所长尹首一教授是国内AI芯片领域的权威专家。他将AI芯片分成了两大类:深度神经网络处理器和神经形态处理器。其中深度神经网络处理器又细分为四种典型架构:
-
指令集架构处理器:以寒武纪的DianNao为代表,通过专门设计的神经网络指令集实现加速
-
数据流处理器:优化数据复用和计算并行度,如谷歌的TPU
-
存内计算处理器:解决传统计算架构的"存储墙"问题,通过在存储器内部进行计算减少数据搬移
-
可重构处理器:具有空间阵列结构,支持动态重构,适应不同算法需求
尹首一教授认为,中国AI芯片最大的优势在于技术路线的全面性。与国外相比,中国几乎在所有技术路线上都有布局,这为应对不同应用需求提供了更多选择。
陈天石博士:ASIC需要技术和资本的双重密集支撑
寒武纪创始人陈天石博士被誉为"中国AI芯片第一人",他对ASIC路线有着深刻的理解。陈天石表示:“AI芯片需要技术和资本的双重密集支撑。专属设计优化满足深度学习模型高运算需求。未来AI芯片将迎来异构计算和物联网发展,为智能世界提供支持。”
陈天石的观点揭示了ASIC路线的一个重要特点:高投入、高壁垒。寒武纪作为国内AI芯片的领军企业,选择了ASIC路线,但这条路并不好走。
中科院计算所:AI设计AI芯片的新探索
中国科学院计算技术研究所的专家们则走了一条更加前沿的道路——用AI来设计AI芯片。
他们推出的“启蒙”系统,实现了处理器芯片和相关基础软件的全自动设计。据中科院计算所的专家介绍:启蒙可全自动实现芯片软硬件设计各步骤,达到或部分超越人类设计师水平。
这种探索虽然不直接回答GPGPU与ASIC之争,但提供了一个全新的思路:或许未来的芯片架构不是由人来选择,而是由AI根据具体需求自动优化生成。
如果这条路走通,那么GPGPU与ASIC之争可能就变得没有意义了——AI会根据具体的应用场景,自动设计出最优的芯片架构。
融合还是分化?
站在2025年的时间节点,我们该如何看待GPGPU与ASIC之争?
未来的趋势不是非此即彼,而是融合发展。
一方面,GPGPU会越来越多地吸收ASIC的优点,比如针对特定AI任务进行硬件优化。NVIDIA的最新GPU就已经集成了专门的张量核心,用于加速AI计算。
另一方面,ASIC也会增强一定的通用性,以适应快速变化的AI模型。谷歌的TPU就是一个例子,它虽然专用,但也能处理多种类型的AI任务。
对于中国来说,最理想的状态是形成GPGPU和ASIC双轮驱动的格局:
-
在需要通用性和灵活性的场景,使用国产GPGPU
-
在需要极致性能和效率的场景,使用专用ASIC
-
两者之间通过统一的软件平台实现无缝切换
但要实现这个目标,需要在以下几个方面取得突破:
第一,软件生态建设。无论选择哪种硬件路线,没有好的软件生态都是空谈。国产AI芯片厂商必须加大在软件工具链上的投入。
第二,架构创新。不能简单模仿国外的设计,而要根据中国的实际需求,进行架构创新。比如,针对中文AI模型的特点,设计专门的硬件加速单元。
第三,产业链协同。芯片设计、制造、封测、应用等各环节需要紧密配合,形成完整的产业链生态。
一场关乎未来的技术路线之争
写到这里,想起了一个有趣的比喻:
GPGPU就像是一把瑞士军刀,什么都能干,但什么都不精通;ASIC则像是手术刀,专门针对特定任务,效率极高但用途单一。
在AI发展的早期阶段,瑞士军刀式的GPGPU确实更实用,因为技术路线还不明确,需要不断尝试。但随着AI技术的成熟,手术刀式的ASIC可能会在特定领域占据主导。
但无论选择哪种路线,最重要的还是生态。没有强大的软件生态支持,再好的硬件也只是摆设。
对于中国来说,这场技术路线之争不仅仅是一个技术选择,更是一个关乎国家AI产业未来的战略抉择。
我们既不能盲目跟随国外的技术路线,也不能闭门造车。而是要根据自己的实际需求,走出一条具有中国特色的AI芯片发展道路。
这条路注定不会平坦,但正如那句老话所说:艰难困苦,玉汝于成。
在AI这个关乎未来的战略领域,中国没有退路,只能迎难而上。


















 2665
2665

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









