




研究背景:
传统机器人抓取技术多依赖物体几何特征,仅关注抓取稳定性,却忽视了任务具体需求。例如,同一把刀在“切菜”与“安全传递”任务中需要完全不同的抓取位置。
现有面向任务的抓取(TOG)方法因受限于小规模数据集、简化语言描述及整洁场景假设,难以泛化至新任务和未见过的物体,导致在真实复杂环境中灵活性不足。
为解决这一难题,研究团队以Franka Research 3七自由度机械臂为实验平台,提出了GraspMolmo——一种可泛化的开放词汇任务导向抓取模型。
其核心目标是:通过结合自然语言指令与单帧RGB-D图像,精准预测符合任务需求的抓取方式,真正实现“机器人不仅能抓,还懂为何抓、如何抓”。
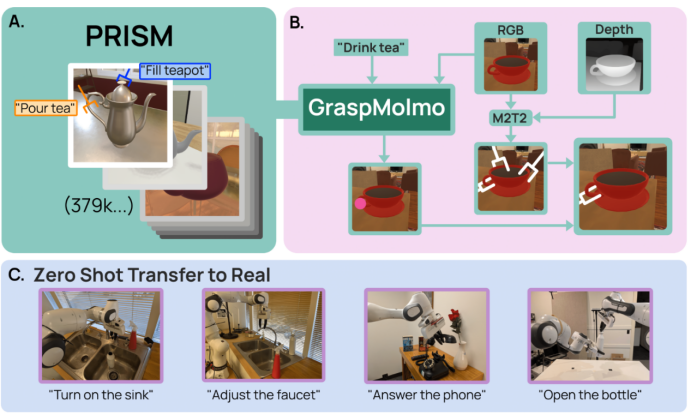
GraspMolmo是一种可泛化的开放词汇面向任务的抓取模型,它在给定自然语言指令的情况下预测语义上合适的抓取
核心方法:GraspMolmo与PRISM数据集
GraspMolmo的突破离不开两大关键支撑:大规模合成数据集PRISM的构建,以及基于视觉语言模型的高效训练。
1.PRISM:大规模任务语义抓取数据集
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4490
4490

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









