



Datawhale发布
联合发布:Dexmal原力灵机、Huggingface
随着机器人技术的快速发展,越来越多的机器人开始走出实验室,进入到复杂、动态的现实世界。如何确保机器人算法在真实环境中的表现能够得到公平、精准的评估,成了一个亟待解决的问题。
长期以来,具身智能的评测通常依赖于仿真环境和合成数据。虽然这些方法能在开发初期降低成本、加快迭代,但它们也有一个固有的缺点——仿真到现实的差距(Sim2Real Gap)。即便算法在虚拟世界中表现得非常出色,部署到真实世界后,面对光照、材质、物理交互等不可预测的因素,往往会遭遇显著的性能下降。
所以,打造一个能够在真实物理环境中直接检验机器人综合能力的评测平台就很重要。黑猫白猫,抓到耗子就是好猫——只有算法能在真实环境中解决问题,才算真正好用。
在这样的背景下,RoboChallenge —— 由 Dexmal 原力灵机 和 Huggingface 联合发起的全球首个大规模、多任务真机评测平台应运而生。
官网:https://robochallenge.ai
论文:https://robochallenge.ai/robochallenge_techreport.pdf
GitHub:https://github.com/RoboChallenge/RoboChallengeInference
HuggingFace:https://huggingface.co/RoboChallengeAI
凭借创新的任务设计和平台架构,RoboChallenge 成功突破了传统评测的限制,推动机器人算法在真实世界中的应用。通过测试视频和实际评测数据,我们可以看到,平台如何通过多样的任务和评测方法,揭示算法在实际环境中的优势与不足。
根据现实场景,打造全新的「机器人考试」
在传统的机器人评测平台中,机器人的考试题通常集中在一些基础操作任务上,比如物体抓取和放置等,这些任务往往无法全面反映机器人在复杂、动态环境中的能力。
以 RoboArena 为例,虽然它为机器人算法提供了初步的评测,但其任务和机器人类型有限,评测场景高度受限。早期的 RoboArena 仅支持 DROID平台 上的几类操作任务,无法全面衡量算法在不同任务条件下的泛化能力。
相比之下,RoboChallenge 在首套考题上就进行了创新,推出了行业内最大规模的真机测试集——Table30。
从简单到复杂,让考题有理有据
Table30测试集 包含了30个由易到难的桌面任务,涵盖了单臂操作、双臂协作、刚性物体与软体物体操作等多种任务,同时包括 时序依赖 和 空间推理 等挑战。
那么这30个考题怎么设计出来的,RoboChallenge公布了它们的理念——四维评估框架:VLA解决方案的技术难点、机器人类型、任务环境特征和目标物体属性。简单理解下,它们分别对应了考试的不同题型、不同的考试工具、不同的考试场地以及考试用的各种材料。
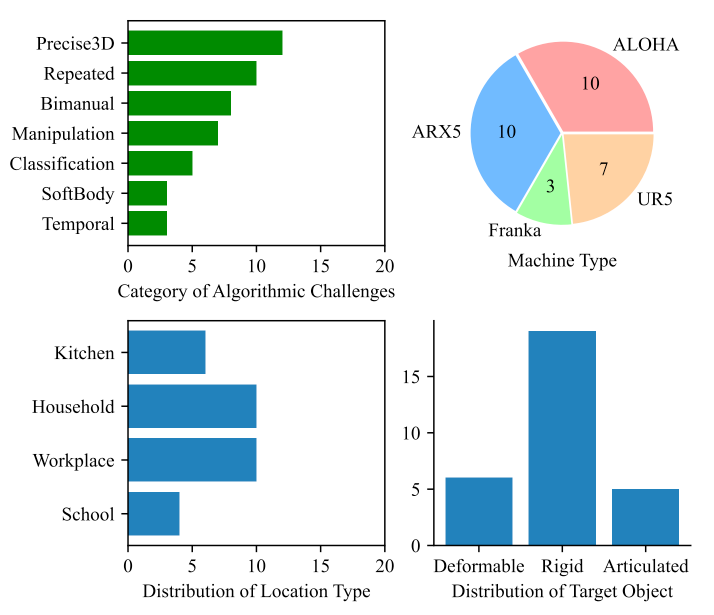
四维框架指导下的Table30任务分布呈现明显的梯度特征:基础能力层(简单抓取、单臂操作)进阶挑战层(多视角融合、物体分类)高阶能力层(时序依赖、软体操作、双臂协作)这种分布通过四维框架的交叉组合实现。
举个例子,商店里真实的条形码扫描场景:机器人右手拿起物体→左手拿起扫码枪→找到物体上的条形码→将扫码枪对准物体二维码→进行扫描→等待扫描完→放下物体和扫码枪。
在这个考题里,要求机器人主动寻找二维码的位置,还要找到合适的角度和距离进行扫描,其实就协同了完整的四维评估框架:
技术难点:需要精准定位+多步骤规划(时空推理)
机器人类型:使用双臂机器人完成(工具选择)
环境特征:商店环境下的实际操作(场景适配)
物体属性:处理各种形状的商品(材料适应)
这样的一套考题用科学的方法确保了考试结果的公平性和全面性,让不同类型的算法能够在多层次、多难度的任务中得到全面评估。有效避免了机器人的偏科,还能精准找到是哪里存在不足,指导后续的改进。
从「结果评分」到「过程评分」,更科学的评分标准
传统的机器人任务评估就像考试中的"判断题"——只关心最终答案是对是错。而Table30的进度评分系统则升级为"综合应用题评分",不仅看最终结果,更重视解题过程的每一个步骤。
这种变革的意义在于:机器人算法在实际应用中,往往会出现"虽然任务失败了,但前期表现很棒"或者"虽然任务成功了,但过程磕磕绊绊"的情况。传统的二值评分无法捕捉这些重要信息,而进度评分系统正是为此而生。
简单来说,分为阶段分解和重试惩罚。
在阶段分解时的核心逻辑是把大题拆成小题,就像老师批改综合应用题时,会把题目分解为多个步骤分别给分,Table30的进度评分系统也将每个任务细分为多个阶段。
针对长时程任务——会按照严格的顺序依赖性拆分阶段;
针对重复技能任务——每次重复就是独立的评分阶段,重复的一致性就成为了重要的评分指标
拆分出来的阶段会分成关键阶段和非关键阶段,并分配特定的进度点数(progress points)。而如果一个机器人在非关键阶段失败了,仍然可以被计为任务成功。下面就是一个长时程任务分解的案例:

同时,考试鼓励"一次做对",对重试会有惩罚。系统引入巧妙的重试识别机制,每次不必要的重试会被扣除0.5分。这就好比考试中——如果一道题反复涂改,即使最终答案正确,卷面分也会受影响。
有了这个机制,算法开发者需要优化一次性成功率,而不是依赖"多次尝试碰运气"的策略。在实际应用中,这种优化直接提升了机器人的工作效率和可靠性。
远程真机评测,打破硬件限制
在刚刚的四维评估框架中其实就提到机器人类型,硬件本身的差异就会带来评估的偏差。
在传统的机器人研究中,不同实验室使用各异的硬件平台,难以统一且部署复杂,极大限制了评测的灵活性和规模性,导致算法性能对比缺乏公平性。RoboChallenge通过创新的「远程机器人测试范式」,解决了这一问题,尤其是在远程机器人控制与数据采集方面。
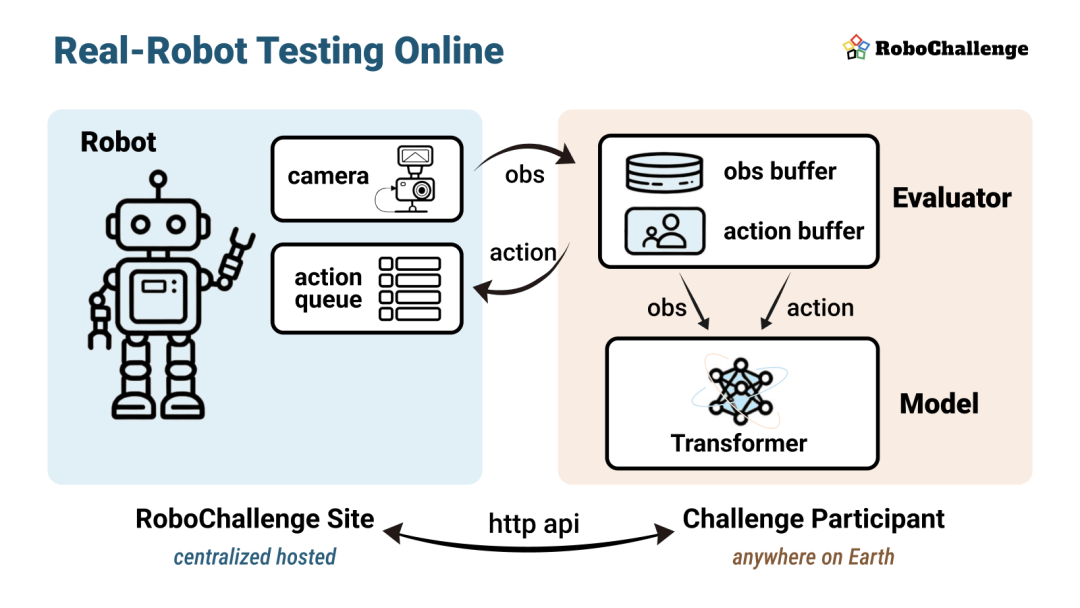
远程机器人测试范式
数据统一,消除硬件和人为偏差
简单来说,RoboChallenge通过硬件统一、视角统一以及初始条件统一实现了数据的统一。
RoboChallenge 通过统一设备让所有参与评测的算法在相同条件下运行。比如,平台集成了以下四类机器人:
UR5:提供工业级精度和重复性,担任基础评测平台
Franka Panda:展现7自由度的灵活性,适合复杂操作任务
Cobot Magic Aloha:支持双臂协同操作,模拟真实作业场景
ARX-5:代表低成本解决方案,确保评测的可扩展性
每种机型经过严格的性能验证和标准化校准,消除了设备差异的影响。
此外,为了进一步保证数据的一致性,RoboChallenge还采用了统一的感知系统。通过多视角RGB-D相机,平台可以在主视角、腕部视角和侧视角捕捉数据,避免了不同数据源间的偏差。
硬件统一解决了设备差异的问题,但 RoboChallenge 还考虑到了人为因素的影响。研究团队发现,即便是完全相同的模型和任务配置,不同测试者操作时也会导致成功率出现极大波动,有时甚至从0%到100%不等。这种人为因素严重影响了评测的公平性。
为了消除这一问题,RoboChallenge 引入了 视觉任务再现方法,通过强制标准化初始状态,彻底消除了人为操纵结果的空间。
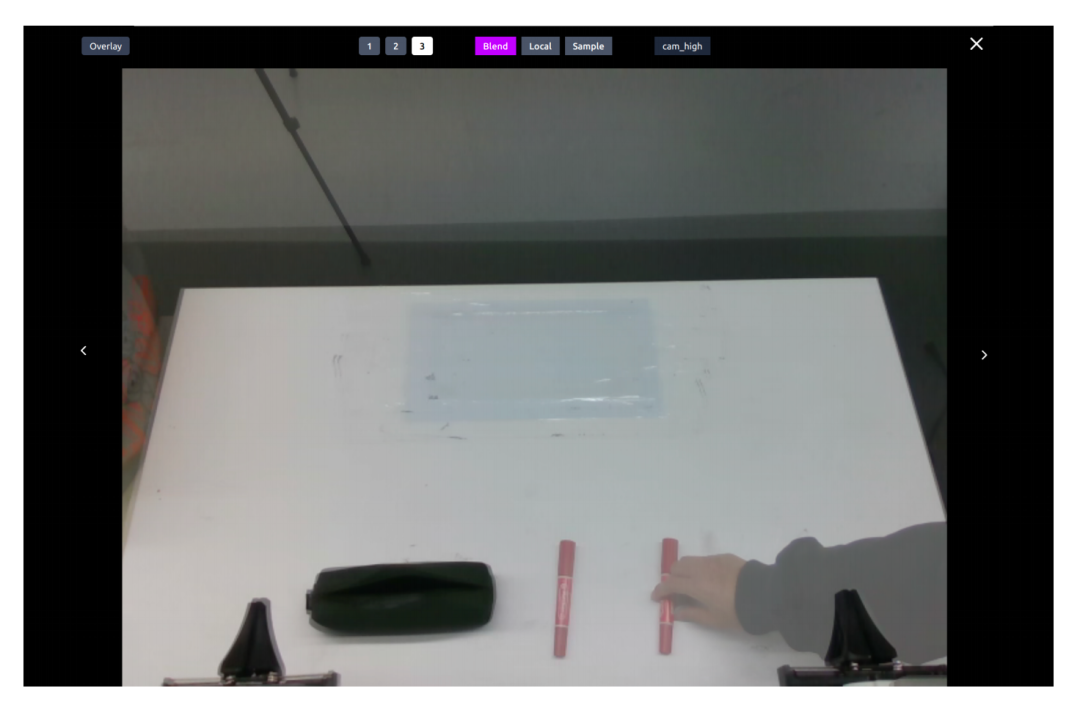
如上图所示,测试时,系统将参考图像叠加到实时相机画面上。测试人员只需要按照画面上的图像,调整物体位置,直到实时场景与参考图像完全吻合。这样,操作者差异对测试结果的影响就被降到了最低。
没有机器人,也能做实验
想象一下,你不需要亲自拥有机器人,甚至不需要提交模型的权重或者 Docker 镜像,通过简单的 API 调用就可以远程控制机器人。
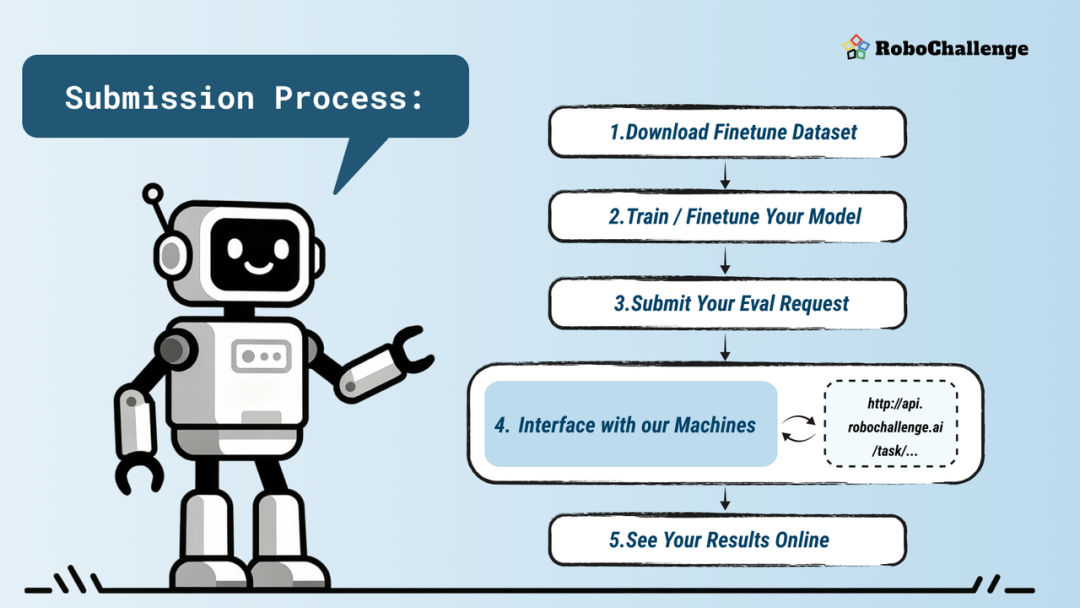
RoboChallenge 就是提供了这样一种方式。研究人员只需通过异步 API 远程访问机器人,提交动作指令,这些指令将通过 FIFO 队列分块执行,并能够实时反馈给你。观测请求返回的不是简单的反馈,而是带有时间戳的多模态数据——包括 RGB、深度和本体感知等,这些数据都高度对齐,确保你能精准评估机器人执行任务的每个细节。
云端化服务的最大优势是,不管你是否拥有物理机器人,都能在网络连接的支持下进行高精度的实验。即便网络存在延迟,机器人也会根据队列精确执行任务,观测数据与动作之间的偏差几乎为零。这样一来,算法评估的精度和可复现性得到了大大提升。
通过这种方式,学术界和产业界的研究者不再受限于昂贵的硬件设施,也能享受到高精度、易用且免费的在线机器人测试环境。甚至可以在没有机器人在身边的情况下,就能进行各种复杂的测试。再也不需要担心缺乏硬件资源,或者被繁杂的设备部署过程所困扰——有了 RoboChallenge,机器人实验变得如此简单。
评测结果分析:真机数据为算法优化指明方向
基于整个创新系统,各个算法的表现差异变得非常明显。例如,在“精确三维定位”任务中,Pi05模型的成功率为43.7%,而Pi0模型只有28.3%。这个差距显示了Pi05模型在空间推理和适应复杂环境方面的优势,而Pi0模型则在处理复杂三维空间时显得有些力不从心。
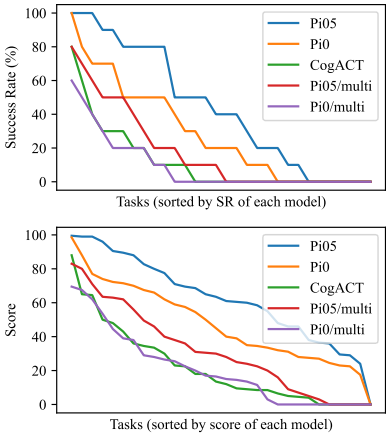
通过RoboChallenge的评测,我们可以清楚地看到,Pi05在精度和推理能力上更强,但也反映出当前算法在应对高精度任务时,特别是在长时间执行复杂任务时,仍然面临不少挑战。
研究人员还发现,在带有“时序依赖”标签的任务中,大部分模型表现较差,暴露出目前许多VLA模型在处理长时程任务时的固有局限。虽然这些模型能够处理单一时刻的任务,但在涉及多个动作协调和时序推理的复杂任务中,性能明显下降。这一发现促使研究人员认识到,现有的模型在处理连续决策和动态调整时需要进行优化,尤其是在实际应用中的灵活性和稳定性。
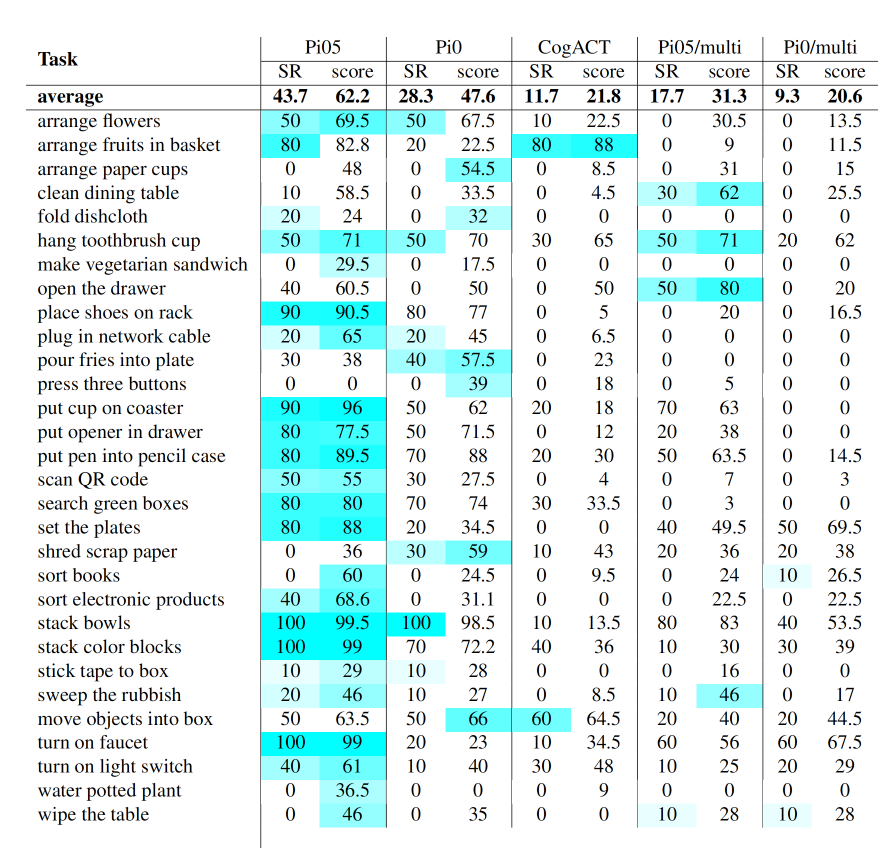
此外,“软体操作”任务的低成功率揭示了当前算法在处理非刚性物体时的不足。传统的VLA模型主要针对刚性物体的操作进行了优化,但在面对软体或形变物体时,表现就不是很好了。这一挑战为后续算法研发指明了方向,要求模型不仅要在刚性物体操作上表现优异,还需要具备处理柔性物体和应对物体形变的能力。
看到这些研究结果,Table30的精心设计和远程机器人测试的优势就显现出来了。它不仅考察了算法的最终执行结果,还深入挖掘了任务执行中的各个环节,真正系统地揭示了每个算法在不同方面的优缺点,为后续算法优化提供了更加针对性的反馈。
结语
RoboChallenge不仅是大规模、多任务的真机评测平台,更像一个公开的「实验室」,让研究者不用实体机器人,也能观察、测试和优化算法的表现。它把原本分散在不同实验室里的资源,集中在一个统一的、可复现的环境里。
这个平台的背后,离不开Dexmal 原力灵机的技术积累,旨在为全球研究者提供开放、可扩展的评测工具。
未来,RoboChallenge还会引入更多硬件平台,从移动机器人到灵巧手臂,测试维度也会从视觉-动作扩展到多模态感知、人机协作、动态环境适应等复杂任务。研究者可基于公开演示数据微调策略并参与评测,推动更加透明、公平的算法对比。
在Dexmal原力灵机和Hugging Face的共同推动下,RoboChallenge正逐步将具身智能从「实验室」带入「现实世界」,为研究者探索、验证和优化新一代机器人算法提供可靠平台,助力具身智能在真实物理环境中创造更大价值。
Join RoboChallenge, This Is Your Opportunity To Shine!
RoboChallenge 全球首发同时还有两场相关主题的重磅直播,欢迎预约观看!
10.16晚19:00:

10.17晚19:00:



一起“点赞”三连↓


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









