




 本文总结了处理不平衡数据的几种算法:有序加权平均(OWA)通过权重加权平均;SMOTE通过合成新样本平衡数据;Borderline-SMOTE专注于边界样本过采样;Easy Ensemble使用集成学习,每个子集保持多数类与少数类样本均衡。这些方法能有效改善分类器性能。
本文总结了处理不平衡数据的几种算法:有序加权平均(OWA)通过权重加权平均;SMOTE通过合成新样本平衡数据;Borderline-SMOTE专注于边界样本过采样;Easy Ensemble使用集成学习,每个子集保持多数类与少数类样本均衡。这些方法能有效改善分类器性能。
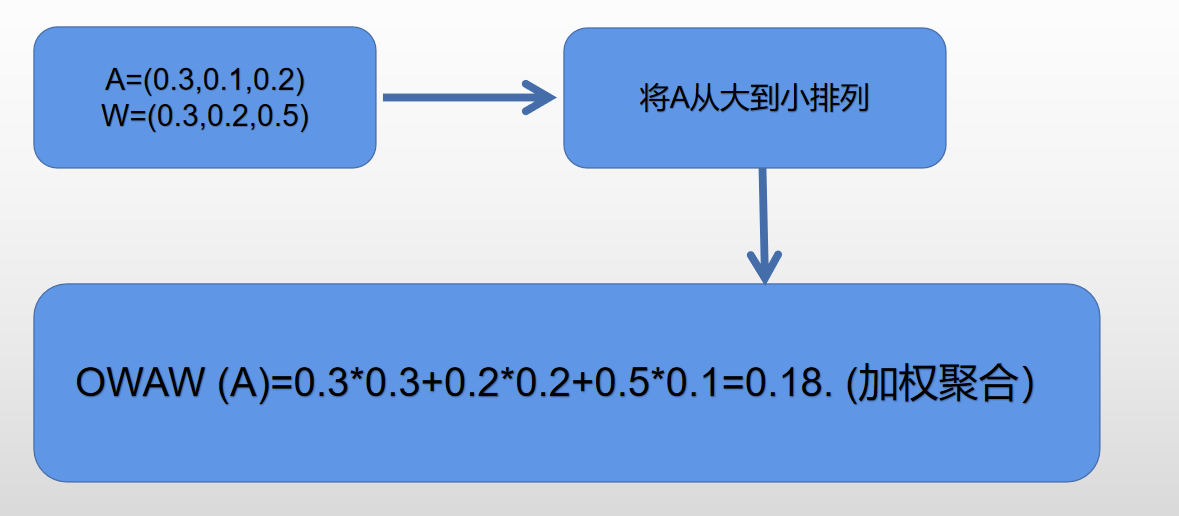
方法一:有序加权平均: OWA有序加权平均算法是一种用于处理不平衡数据的算法。在OWA中,不同的数据被赋予不同的权重,然后根据这些权重进行加权平均计算。这种方法可以有效地处理不平衡数据,并且可以为不同的数据类型提供不同的重要性。详情可参考IFROWANN文章。(调节效果主要取决于权向量的选择)

方法二:SMOTE:
SMOTE算法相对于传统的随机过采样算法有哪些进步?
答:与传统的随机过采样算法相比,SMOTE算法通过更好的合成少数类样本来解决类别不平衡问题,而不是简单地复制样本。因此,它可以提高分类器的性能,同时减少过拟合问题。这使得SMOTE算法在解决类别不平衡问题上更加有效和可靠。传统随机采样容易产生过拟合问题。
SMOTE算法是一种用于解决数据不平衡问题的机器学习算法。所谓数据不平衡,指的是数据集中不同类别的样本数量不平衡,导致训练出的模型在预测时偏向数量较多的类别。SMOTE算法的全称为Synthetic Minority Over-sampling Technique,即合成少数类过采样技术。它通过生成一些合成样本来增加少数类的样本数量,从而平衡数据集。
SMOTE算法在合成样本时,采用了对少数类样本进行随机插值的方法,即在少数类样本之间随机选取一些样本,对它们进行线性插值,得到新的合成样本。该算法的基本思想是在少数类样本中找出一个样本,然后在它的近邻中随机选取一个样本,计算两个样本之间的距离(一般采用欧氏距离),然后在两个样本之间进行
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1204
1204

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









