




全面解析Block RAM、Distributed RAM、Shift Register和Built-in FIFO的技术特点与选择策略
1 引言
在Xilinx FPGA设计中,FIFO(先进先出)队列是数据流处理的核心组件。FIFO IP核提供了四种不同的实现方式,每种都有其独特的资源特性和适用场景。本文将深入探讨这四种实现方式的差异,帮助您做出最佳选择。
2 四种实现方式概览
| 实现方式 | 存储资源 | 逻辑资源 | 最大频率 | 功耗 | 典型应用场景 |
|---|---|---|---|---|---|
| Block RAM | 专用BRAM | 少 | 高 | 低 | 大数据量缓冲 |
| Distributed RAM | LUT | 多 | 中 | 中 | 小容量、灵活配置 |
| Shift Register | SRL32E | 少 | 高 | 低 | 固定延迟线、小深度 |
| Built-in FIFO | 专用硬件 | 极少 | 最高 | 最低 | 高速接口、硬核功能 |
3 深入解析各实现方式
3.1 Block RAM (BRAM) FIFO
3.1.1 资源特性
// 典型的BRAM FIFO配置
// 资源消耗示例:深度512,宽度32位
// - 消耗1个36Kb BRAM块
// - 少量控制逻辑(~50 LUTs + ~30 FFs)
3.1.2 资源消耗特点:
-
存储资源:使用专用Block RAM块
-
每个BRAM块36Kb(或18Kb模式)
-
-
逻辑资源:消耗较少LUT和寄存器
-
主要用于地址生成、状态标志等控制逻辑
-
-
布线资源:中等,BRAM有专用布线通道
3.1.3 性能指标
-
最大频率:通常可达450-550MHz(UltraScale+)
-
** latency**:2-3个时钟周期
-
吞吐量:每个时钟周期可完成一次读写操作
3.1.4 应用场景
// 大数据量缓冲示例
module large_buffer_fifo (
input wire clk,
input wire [63:0] data_in,
input wire wr_en,
output wire [63:0] data_out,
input wire rd_en
);
// 适合使用BRAM FIFO的场景:
// - 大数据包处理(以太网、视频帧)
// - 跨时钟域数据缓冲
// - 需要较大深度(>64)的FIFO
endmodule
3.1.5 典型应用:
-
视频帧缓冲区(1920x1080图像数据)
-
网络数据包缓冲
-
处理器与外围设备的数据交换
-
大数据量的跨时钟域传输
module block_ram_fifo_scenarios;
// 场景1:通用数据缓冲
// 比如:图像处理流水线
fifo_generator_0 image_fifo (
.clk(video_clk),
.din(pixel_data),
.wr_en(pixel_valid),
.dout(processed_pixel)
);
// 配置:Block RAM, 深度2048, 宽度24
// 场景2:需要灵活配置
// 比如:可配置的数据包缓冲
fifo_generator_1 packet_fifo (
.clk(sys_clk),
.din(network_packet),
.wr_en(packet_valid)
);
// 配置:支持FWFT模式,非对称端口
endmodule
3.2 Distributed RAM (分布式RAM) FIFO
3.2.1 资源特性
// 分布式RAM FIFO资源消耗
// 深度32,宽度16位配置:
// - 消耗约16个LUTs(作为RAM使用)
// - 额外控制逻辑(~30 LUTs + ~25 FFs)
3.2.2 资源消耗特点:
-
存储资源:使用可配置逻辑块(CLB)中的LUT
-
每个LUT可实现32x1位或64x1位存储器
-
资源消耗与深度、宽度成线性关系
-
-
逻辑资源:消耗较多LUT和寄存器
-
LUT既用于存储又用于控制逻辑
-
-
布线资源:较多,需要通用布线资源
3.2.3 性能指标
-
最大频率:通常300-400MHz
-
Latency:1-2个时钟周期
-
吞吐量:受LUTRAM结构限制
3.2.4 应用场景
// 小容量灵活FIFO示例
module small_flexible_fifo (
input wire clk,
input wire [7:0] data_in,
input wire wr_en,
output wire [7:0] data_out,
input wire rd_en
);
// 适合使用Distributed RAM FIFO的场景:
// - 小深度FIFO(通常≤64)
// - 需要极低延迟
// - BRAM资源紧张但逻辑资源充足
// - 深度/宽度需要非标准配置
endmodule
3.2.5 典型应用:
-
小数据包临时缓冲
-
协议转换的中间缓冲
-
状态机中的数据暂存
-
深度/宽度为非2的幂次方的特殊配置
3.3 Shift Register (移位寄存器) FIFO
Shift Register FIFO基于Xilinx FPGA中的SRL32E原语实现。SRL32E(Shift Register Look-up Table 32-bit with Enable)是LUT的一种特殊配置模式,可以将一个LUT配置成32位的移位寄存器。
// SRL32E原语示例
SRL32E #(
.INIT(32'h00000000) // 初始值
) SRL32E_inst (
.Q(Q), // 移位寄存器输出
.A(A), // 地址选择(0-31)
.CE(CE), // 时钟使能
.CLK(CLK), // 时钟
.D(D) // 数据输入
);
3.3.1 时序特性
基本时序行为
module shift_register_fifo_timing (
input wire clk,
input wire [7:0] data_in,
input wire wr_en,
output wire [7:0] data_out
);
// 假设深度=4的移位寄存器FIFO时序
// 时钟周期0: 写入数据A
// 时钟周期1: 数据移动到stage1,写入数据B
// 时钟周期2: A->stage2, B->stage1, 写入C
// 时钟周期3: A->stage3, B->stage2, C->stage1, 写入D
// 时钟周期4: A出现在输出,B->stage3, C->stage2, D->stage1, 写入E
// 关键特性:固定延迟!数据A在写入后第4个周期出现在输出
endmodule
实际时序波形
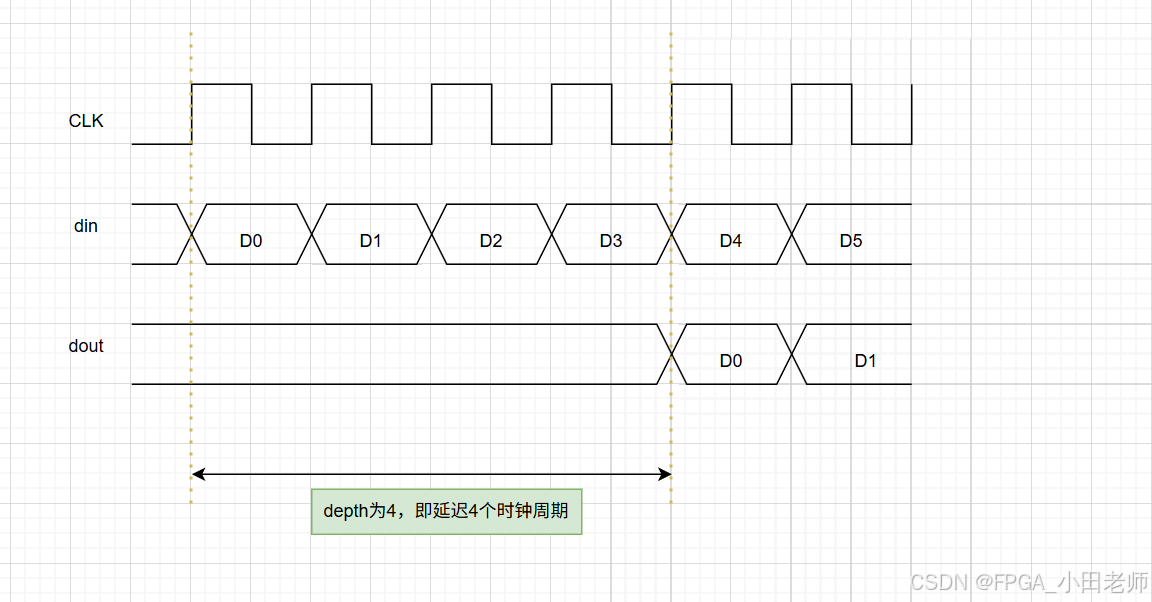
3.3.2 资源特性
// SRL32E为基础的移位寄存器FIFO
// 深度32,宽度8位配置:
// - 消耗8个SRL32E(每个处理1位)
// - 少量控制逻辑(~15 LUTs + ~10 FFs)
3.3.3 资源消耗特点:
-
存储资源:使用SRL32E(基于LUT的移位寄存器)
-
单个LUT可实现32位移位寄存器
-
级联多个SRL32E实现更大深度
-
-
逻辑资源:消耗极少
-
主要控制逻辑用于地址管理和状态标志
-
-
布线资源:较少,局部布线即可满足
3.3.4 性能指标
-
最大频率:通常可达500-600MHz
-
Latency:固定延迟,等于移位深度
-
吞吐量:每个时钟周期可处理一次数据移动
3.3.5 应用场景
场景1:固定延迟线
module fixed_delay_line_example (
input wire clk,
input wire [15:0] adc_data,
output wire [15:0] delayed_data
);
// 在ADC采样和DSP处理之间插入固定延迟
// 用于时序对齐
shift_register_fifo #(
.WIDTH(16),
.DEPTH(8) // 固定8周期延迟
) delay_fifo (
.clk(clk),
.din(adc_data),
.wr_en(1'b1), // 持续写入
.rd_en(1'b1), // 持续读取
.dout(delayed_data)
);
endmodule
场景2:数据同步
module data_sync_example (
input wire clk_dsp,
input wire clk_adc,
input wire [31:0] dsp_data,
output wire [31:0] synced_data
);
// 将DSP处理后的数据与ADC时钟域同步
shift_register_fifo #(
.WIDTH(32),
.DEPTH(2) // 2级同步,避免亚稳态
) sync_fifo (
.clk(clk_adc),
.din(dsp_data),
.wr_en(1'b1),
.rd_en(1'b1),
.dout(synced_data)
);
endmodule
3.3.6 典型应用:
-
DSP算法中的流水线对齐
-
数据同步延迟线
-
数字滤波器中的延迟单元
-
时钟域交叉的简单同步
3.4 Built-in FIFO (内置FIFO)
3.4.1 资源特性
// Built-in FIFO通常是硬核实现
// 资源消耗极低,但配置灵活性受限
3.4.2 资源消耗特点:
-
存储资源:使用专用硬件存储单元
-
不占用可编程逻辑资源
-
固定容量和配置
-
-
逻辑资源:几乎不消耗
-
所有控制逻辑都是硬连线
-
-
布线资源:专用布线通道
3.4.3 性能指标
-
最大频率:可达器件I/O的最高频率
-
Latency:硬核优化,极低延迟
-
吞吐量:最高,支持背靠背操作
3.4.4 应用场景
// 高速接口应用示例
module high_speed_interface (
input wire gt_tx_clk,
input wire [63:0] tx_data,
output wire [63:0] rx_data
);
// 适合使用Built-in FIFO的场景:
// - 高速串行接口(如GTX/GTH)
// - 硬核IP配套的FIFO
// - 对性能要求极高的应用
// - 需要确定性的时序行为
endmodule
3.4.5 典型应用:
-
高速串行收发器配套FIFO
-
PCIe、以太网等硬核IP的数据缓冲
-
对时序要求极其严格的应用
-
需要最高性能的数据通路
module builtin_fifo_scenarios;
// 场景1:高速串行接口
// 比如:PCIe端点
pcie_ep pcie_instance (
.user_clk(user_clk),
.tx_data(tx_fifo_dout), // Built-in FIFO输出
.rx_data(rx_fifo_din) // Built-in FIFO输入
);
// 场景2:硬核IP配套FIFO
// 比如:以太网MAC
eth_mac mac_instance (
.tx_fifo_full(tx_builtin_full),
.rx_fifo_empty(rx_builtin_empty)
);
endmodule
4 详细对比分析
4.1 资源消耗深度对比
Block RAM FIFO
# 资源消耗估算公式
# 对于深度D,宽度W的BRAM FIFO:
set bram_count [expr int(ceil(double($D * $W) / 32768.0))] ;# 36Kb BRAMs
set lut_estimate [expr 50 + $W / 2] ;# 控制逻辑LUTs
set ff_estimate [expr 30 + $W] ;# 控制逻辑FFs
Distributed RAM FIFO
# 资源消耗估算
set lutram_count [expr $D * $W / 32] ;# 基于32x1 LUTRAM
set control_luts [expr 30 + $W] ;# 控制逻辑
set total_luts [expr $lutram_count + $control_luts]
4.2 性能特性对比
| 特性 | Block RAM | Distributed RAM | Shift Register | Built-in |
|---|---|---|---|---|
| 最大深度 | 大(36Kb) | 小(受LUT限制) | 中小(32×级联) | 固定 |
| 可配置性 | 高 | 最高 | 中 | 低 |
| 时钟域交叉 | 支持 | 支持 | 有限支持 | 硬件支持 |
| 功耗 | 低 | 中 | 低 | 最低 |
| 初始化 | 支持 | 支持 | 不支持 | 硬件管理 |
5 选择策略与设计指南
5.1 基于容量的选择
// 容量选择指南
module fifo_selection_guide;
// 选择策略:
// 情况1:深度 > 256,使用Block RAM
// 理由:BRAM效率高,节省逻辑资源
// 情况2:深度 ≤ 64,考虑Distributed RAM
// 理由:避免BRAM资源浪费,配置灵活
// 情况3:固定延迟需求,使用Shift Register
// 理由:资源效率最高,性能好
// 情况4:高速硬核接口,使用Built-in FIFO
// 理由:性能最优,资源占用最少
endmodule
5.2 基于应用场景的选择流程
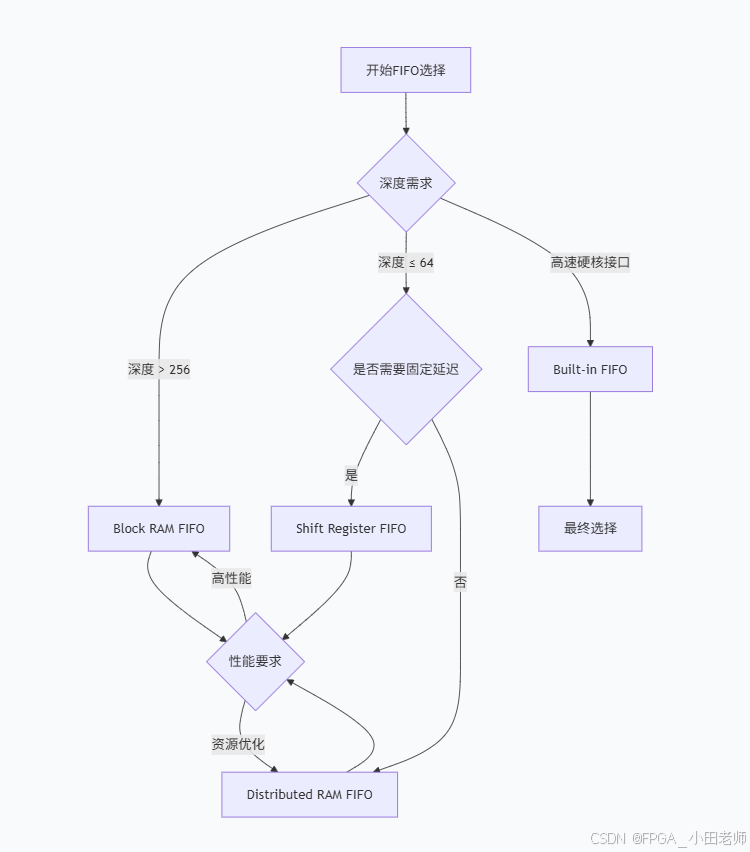
5.3 时序收敛考虑
# 时序约束建议
# Block RAM FIFO:通常时序较好,约束简单
create_clock -period 2.0 -name fifo_clk [get_ports clk]
# Distributed RAM FIFO:可能需要额外约束
set_max_delay -from [get_pins fifo_ctrl/*] -to [get_pins fifo_mem/*] 1.5
5.4 功耗考虑
// 功耗优化选择
module power_optimized_fifo;
// 低功耗优先级:
// 1. Built-in FIFO (硬核功耗最低)
// 2. Shift Register (动态功耗低)
// 3. Block RAM (静态功耗低)
// 4. Distributed RAM (功耗相对较高)
endmodule
6 总结
选择适当的FIFO实现方式需要综合考虑多个因素:
6.1 关键决策因素
-
容量需求:深度和宽度决定基本选择
-
性能要求:频率、吞吐量、延迟需求
-
资源状况:当前设计的BRAM/LUT/FF使用情况
-
功耗预算:不同实现的功耗特性差异
-
设计阶段:原型阶段可灵活,量产阶段需优化
6.2 推荐选择策略
-
默认选择:Block RAM FIFO(平衡性能与资源)
-
小容量灵活需求:Distributed RAM FIFO
-
固定延迟应用:Shift Register FIFO
-
最高性能场景:Built-in FIFO
-
资源紧张时:根据实际剩余资源调整选择
通过深入理解每种实现方式的特性和适用场景,您可以在FPGA设计中做出最优的FIFO实现选择,从而在性能、资源和功耗之间达到最佳平衡


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











