




RAG从静态到具有理解、推理、决策的Agentic RAG
最近在做大模型应用落地的项目时,深刻感受到传统RAG系统的局限性。虽然RAG技术已经成为增强LLM能力的标配方案,但面对复杂的多步推理任务时,静态的检索流程往往力不从心。今天想和大家分享一下RAG技术的演进历程,特别是最新的Agentic RAG如何通过引入智能代理来突破这些限制。
引言:为什么需要更智能的RAG
大语言模型虽然强大,但有个致命弱点:它们的知识是静态的,局限于训练时的数据。想象一下,如果你的AI助手还在用2023年的知识回答2025年的问题,那会有多尴尬。这就是为什么我们需要RAG(Retrieval-Augmented Generation)技术。
根据的定义,RAG是一种通过在运行时向模型的提示中注入外部上下文来改进模型响应的技术。它不依赖于模型的预训练知识,而是从连接的数据源中检索相关信息,用于生成更准确和上下文感知的响应。
但传统RAG也有自己的问题。它就像一个只会按部就班查资料的助手,缺乏灵活性和主动思考能力。这时候,Agentic RAG应运而生。
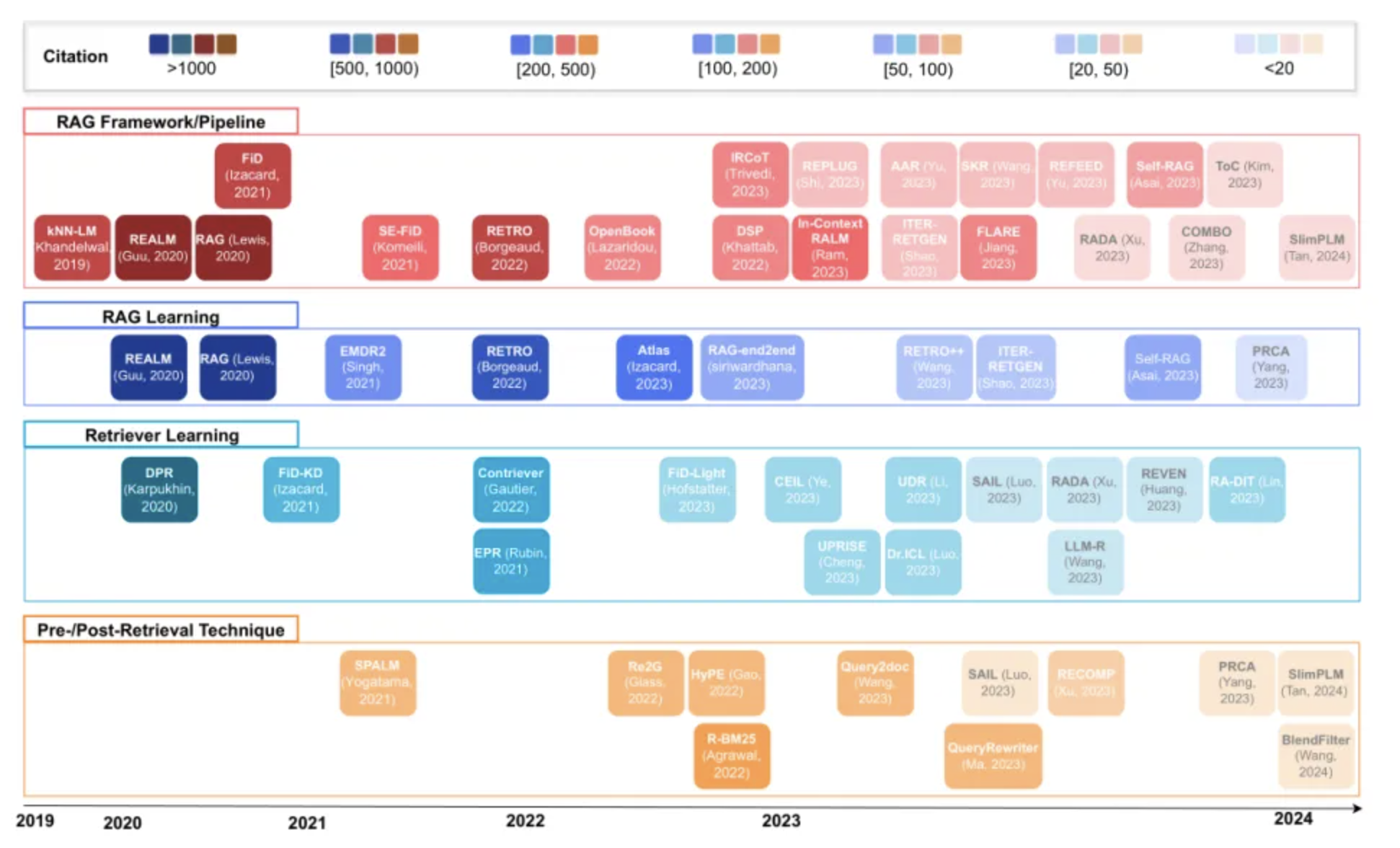
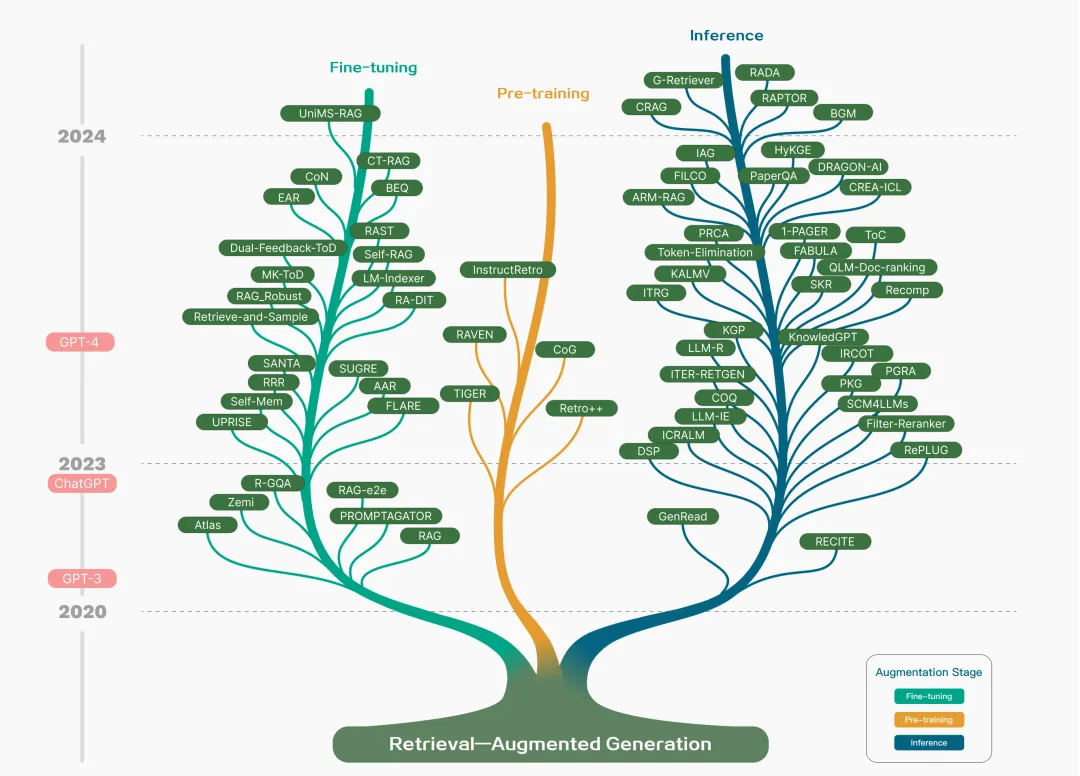
RAG技术概述及其演变历程
RAG的核心组件架构
让我先来解释一下RAG系统的基本架构。
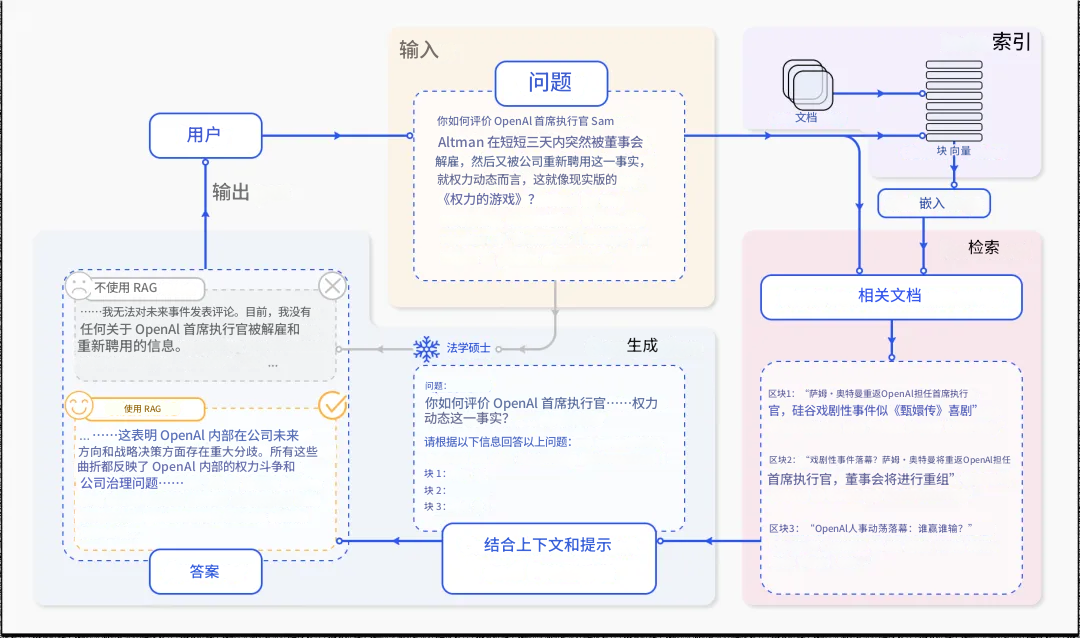
一个完整的RAG系统包含三个核心组件:
检索(Retrieval)组件:这是系统的"搜索引擎",负责从外部数据源(知识库、API、向量数据库等)查询相关信息。现代的检索器已经从简单的关键词匹配进化到使用密集向量搜索和transformer模型,大大提升了语义理解能力。
增强(Augmentation)组件:这部分像个"信息提炼器",处理检索到的原始数据,提取最关键的信息,去除冗余内容,确保传给生成模型的是高质量的上下文。
生成(Generation)组件:最后这个环节将检索到的信息与LLM的预训练知识融合,生成最终的响应。这里的关键是如何巧妙地将外部知识整合到生成过程中。
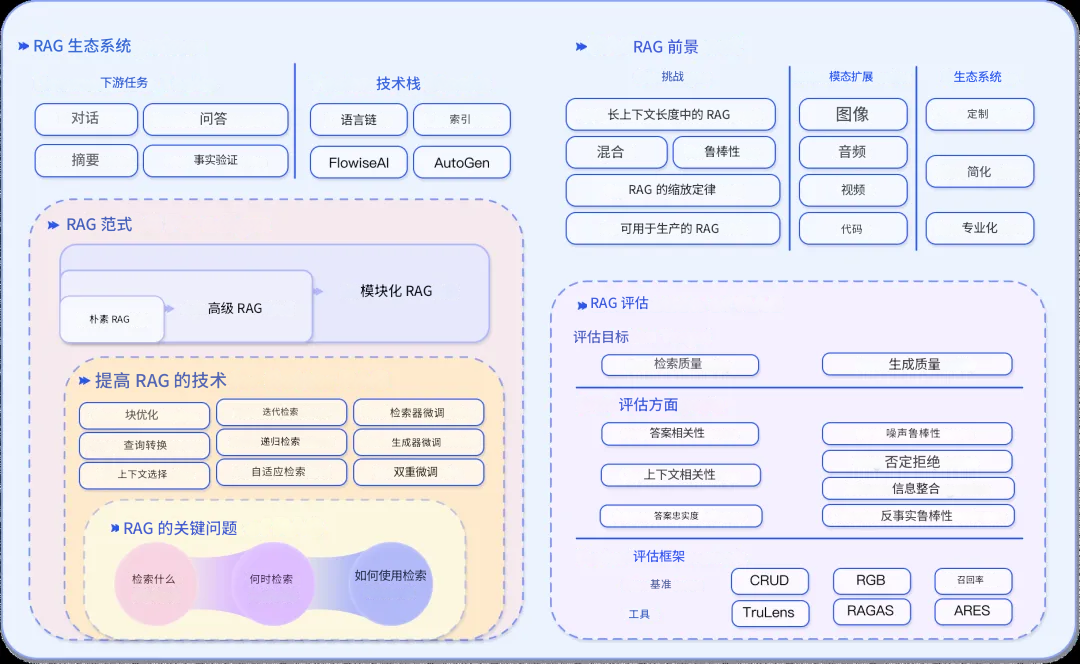
RAG范式的五个发展阶段
根据最新的研究综述,RAG技术经历了五个重要的发展阶段,每个阶段都在解决前一阶段的局限性。
1. 基础 RAG
这是RAG的最初形态,采用简单的"检索->阅读"工作流程。系统使用TF-IDF或BM25等传统方法进行关键词检索,然后将检索到的文档直接喂给大语言模型。
基础 RAG的问题:
- 缺乏语义理解,只能做表面的关键词匹配
- 生成的回答常常不连贯,因为缺少上下文整合
- 面对大规模数据集时性能下降严重
举个例子,当用户问"如何提升模型的推理速度"时,系统可能检索到包含"模型"和"速度"的文档,但这些文档可能在讲模型训练速度,而非推理速度。
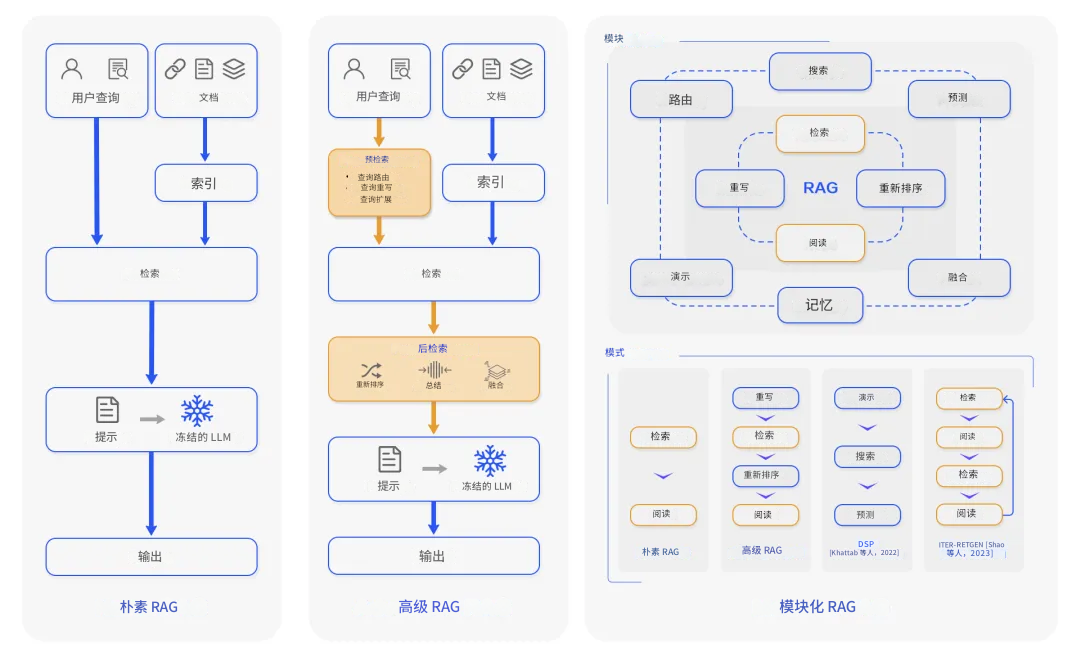
2. Advanced RAG(高级RAG)
Advanced RAG引入了语义理解能力,这是个质的飞跃。系统开始使用密集向量检索(如DPR),将查询和文档都编码成高维向量,在语义空间中进行匹配。
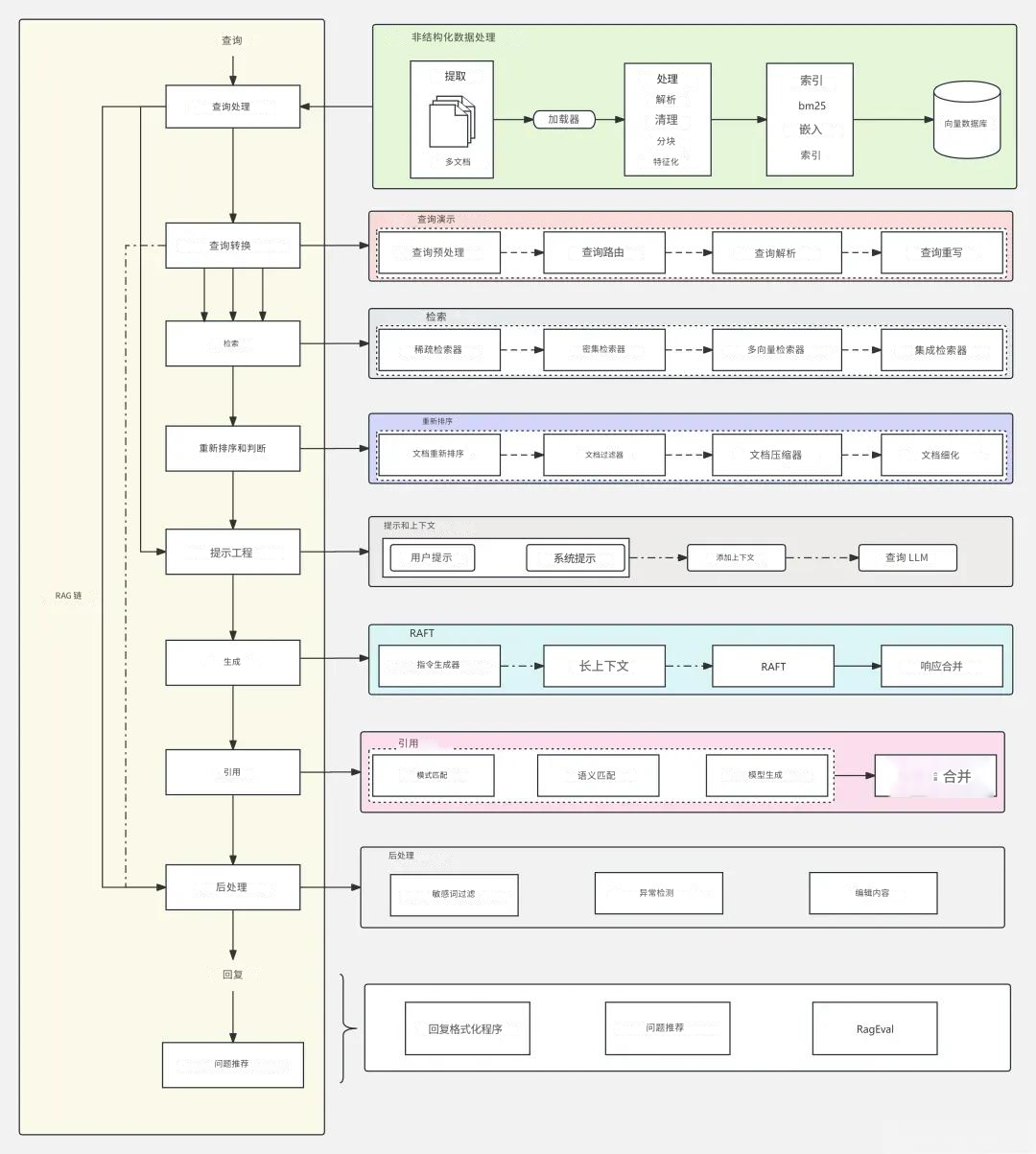
关键改进包括:
- 密集向量搜索:用户查询和文档在同一个向量空间中表示,实现真正的语义匹配
- 上下文感知重排序:使用神经网络对检索结果重新排序,确保最相关的内容排在前面
- 迭代检索机制:支持多跳推理,可以在多个文档间进行复杂推理
在实践中,我发现Advanced RAG特别适合研究综述和个性化推荐场景。不过计算开销比较大,处理大规模数据集时还是有压力。
3. Modular RAG(模块化RAG)
模块化RAG是目前工业界比较青睐的架构,它把整个系统拆分成独立的、可替换的组件。这种设计理念类似于微服务架构,每个模块专注于自己的任务。
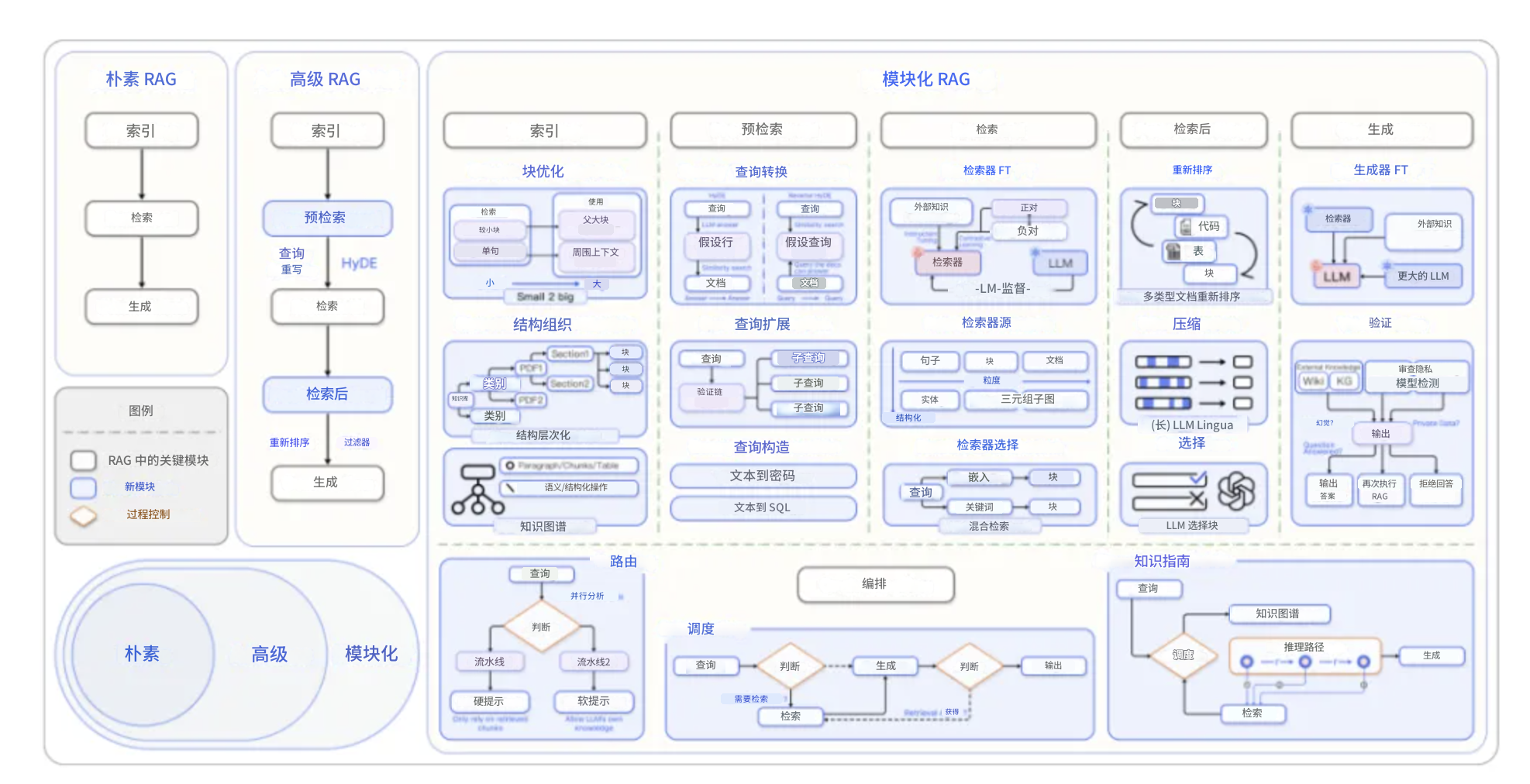
核心创新点:
- 混合检索策略</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 538
538

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









