 Agentic RAG:增强RAG系统处理能力
Agentic RAG:增强RAG系统处理能力




Agentic RAG 是一种基于 AI Agent的 RAG 实现。
具体而言,它将AI Agent纳入 RAG 流程中,以协调其组件并执行超越简单信息检索和生成的额外操作,以克服RAG基本流程的局限性。
这种从“工具”到“智能体”的转变,提升了RAG系统的处理能力
-
\1. 基本概念
-
- 1.1 什么是Retrieval-Augmented Generation (RAG)
- 1.2 什么是Agent
- 1.3 什么是Agentic RAG
- 1.4 Agentic RAG 和 RAG 区别
-
\2. 核心架构
-
- 2.1 Agentic RAG 架构
- 2.2 Agentic RAG的实现思路
-
\3. 技术实现
-
- 3.1 规划模块
- 3.2 执行模块
-
\4. Agentic RAG 的局限性
在生成式AI的应用中,大语言模型(LLM)的“幻觉问题”始终是制约其落地的核心障碍。
传统检索增强生成(RAG)通过引入外部知识库缓解了这一矛盾,但其线性流程(检索→生成)在面对复杂任务时仍显不足。
例如,当用户提问“如何选择一款适合家庭使用的空气净化器?”时,传统RAG往往只能返回零散的产品选购建议,而无法系统性整合“核心性能指标”、“用户评价与口碑”、“不同品牌的性价比”等细节。
Agentic RAG与传统RAG的被动响应不同,Agentic RAG更像一个“项目经理”,能够自主优化问题、动态规划检索路径,并通过多轮验证优化输出结果。这种从“工具”到“智能体”的转变,大大提升了系统的处理能力。
1. 基本概念
1.1 什么是Retrieval-Augmented Generation (RAG)
一个简单的 RAG 由一个检索组件(通常由嵌入模型和向量数据库组成)和一个生成组件(一个LLM)构成。
在推理时,用户查询的问题在索引文档中进行相似性搜索,检索出与问题最相似的文档,并为LLM提供额外的上下文。
它通过整合外部知识源来增强传统的大语言模型 (LLM),使LLM能够访问和利用除初始训练数据之外的其他大量信息。
可以将 RAG 想象为一位学者,除了拥有自己的知识外,还可以即时访问到一座全面的图书馆。
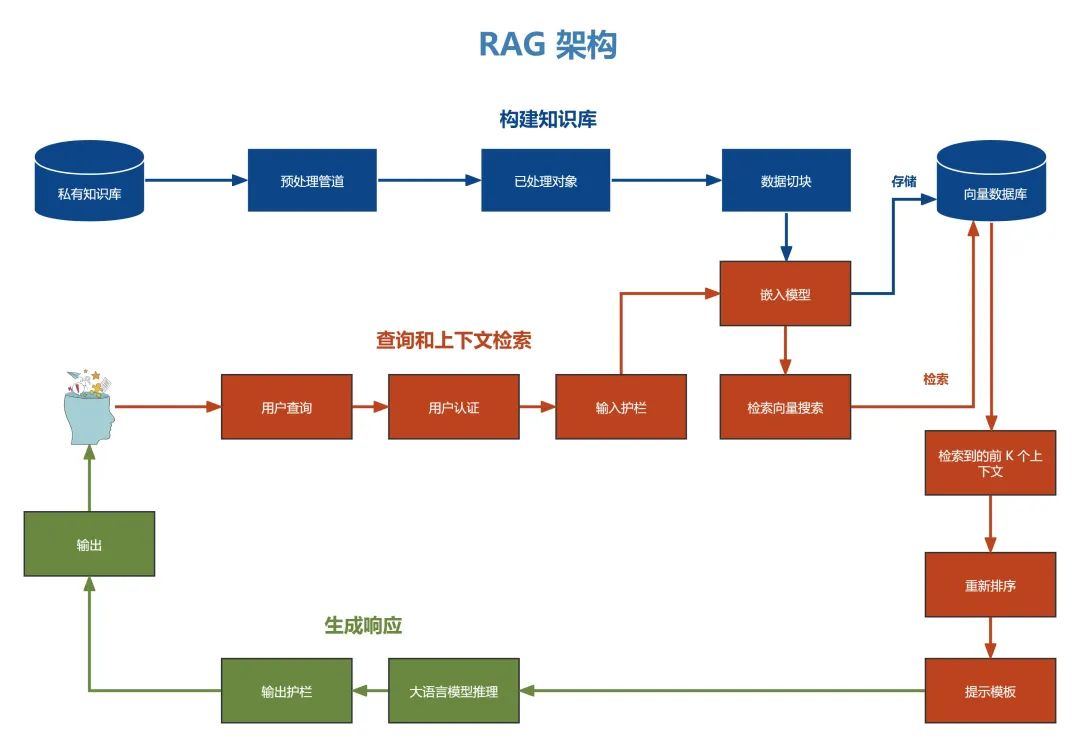 RAG架构
RAG架构
典型的 RAG 应用有两个显著的局限性
- 简单的 RAG 仅考虑一个外部知识源。然而,一些场景可能需要多个外部知识源,而另一些场景可能需要外部工具和 API,例如网络搜索。
- 上下文只被检索一次。对于检索到的上下文的质量没有推理或验证。
1.2 什么是Agent
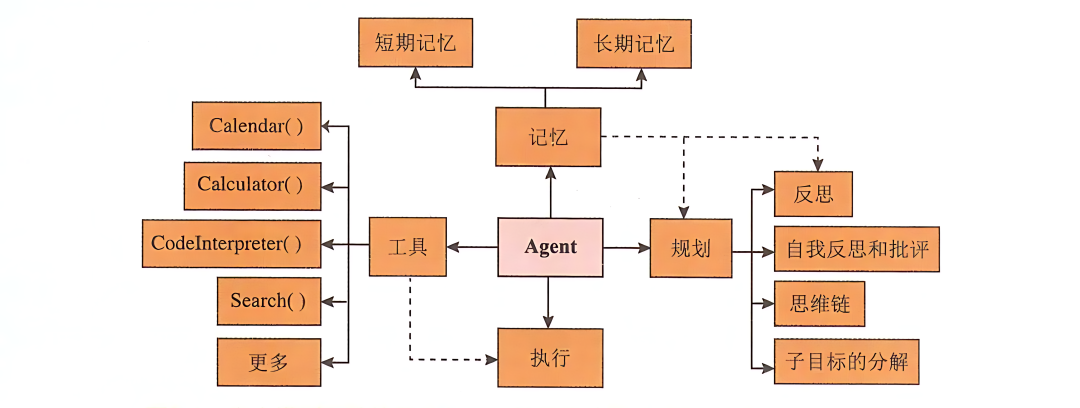
AI Agent,即人工智能代理,一般直接叫做智能体。在是一种能够感知环境、做出决策并采取行动的系统。
这些系统能够执行被动的任务,也能够主动寻找解决问题的方法,适应环境的变化,并在没有人类直接干预的情况下做出决策。
Agent的核心组成部分是:
-
模型
在Agent的范畴内,模型指的是Agent流程中集中决策者的语言模型(LLM)。
-
记忆
包含短期记忆和长期记忆两部分。短期记忆与上下文学习有关,属于提示工程的一部分,而长期记忆涉及信息的长时间保留和检索,通常利用外部向量存储和快速检索。
-
规划
Agent需要具备规划(同时也包含决策)能力,以有效地执行复杂任务。这涉及子目标的分解(Subgoal Decomposition)、连续的思考(即思维链)、自我反思和批评(Self-critics),以及对过去行动的反思(Reflection)
-
工具
Agent 可能调用的各种工具,如日历、计算器、代码解释器和搜索功能等
相关阅读:
从0到1开发AI Agent(智能体)(一)| 基于大模型的AI Agent技术框架
1.3 什么是Agentic RAG
Agentic RAG 是一种基于 AI Agent的 RAG 实现。
具体而言,它将AI Agent纳入 RAG 流程中,以协调其组件并执行超越简单信息检索和生成的额外操作,以克服RAG基本流程的局限性。
RAG Agent可以在以下示例检索场景中进行推理和行动:
- 决定是否检索信息
- 决定使用哪个工具来检索相关信息
- 优化查询问题
- 评估检索到的上下文,并决定是否需要重新检索。
1.4 Agentic RAG 和 RAG 区别
尽管 RAG(发送查询、检索信息和生成响应)的基本概念保持不变,但工具的使用使其更加通用,从而变得更加灵活和强大。
1.4.1 传统RAG的核心机制
- 流程固定:用户提问 → 单次检索外部数据 → 生成回答。
- 被动响应:基于当前查询直接检索,生成一次性结果。
- 适用场景:简单问答、事实性查询(如“太阳系有多少行星?”)。
1.4.2 Agentic RAG的创新点
自主决策与动态流程:
- 任务优化和分解:对用户问题进行优化或将复杂问题拆解为子任务(如“比较A和B”分解为检索A、检索B、对比分析)。
- 多步交互:多次检索与生成循环,逐步优化结果(如先查定义,再查应用,最后整合)。
- 动态调整:根据生成内容或用户反馈调整检索策略(如补充遗漏的信息源)。
主动性与智能体特性:
- 规划模块:决定何时检索、如何分解问题。
- 自我评估:检查答案完整性,触发二次检索或修正(如发现数据冲突时重新验证)。
交互与反馈:
- 多轮对话:支持上下文感知的持续交互(如追问、澄清需求)。
- 用户反馈利用:根据用户修正(如“我需要更多细节”)优化后续步骤。
| 特征 | 传统RAG | Agentic RAG |
|---|---|---|
| 流程灵活性 | 固定单次检索生成 | 动态多步骤,自主调整流程 |
| 任务处理能力 | 适合简单、明确的问题 | 处理复杂、多层次的查询 |
| 交互性 | 单轮响应 | 支持多轮对话与上下文跟踪 |
| 决策自主性 | 被动执行 | 主动规划、分解任务并优化路径 |
| 反馈机制 | 无或有限 | 内置自我评估与用户反馈整合 |
| 适用场景 | 事实问答、文档摘要 | 深度分析、对比研究、开放域复杂任务 |
2. 核心架构
2.1 Agentic RAG 架构
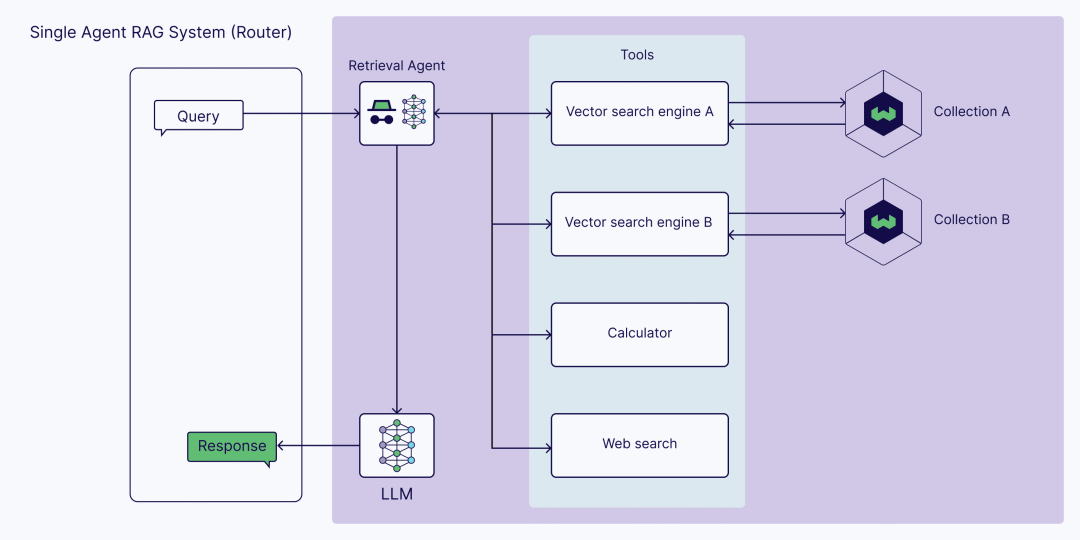
在最基本的形式中,Agent是一个路由的作用。Agent决定从哪个来源检索额外的上下文。外部知识来源于(向量)数据库或其他渠道。
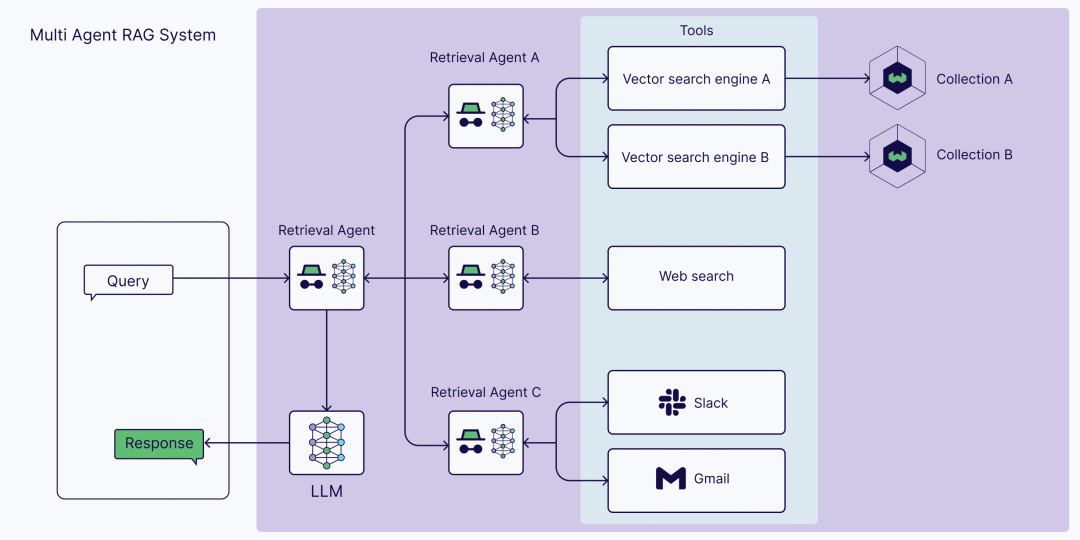
在更复杂的场景中,多智能体系统发挥作用。这些架构涉及多个智能体协同工作,每个智能体专注于特定的任务或数据源。
2.2 Agentic RAG的实现思路
基本的Agentic RAG的核心架构主要由规划模块、执行模块两个基本模块组成。
这些模块通过动态协作,实现了从任务优化到结果生成的全流程自动化。
2.2.1 规划模块:任务优化与决策
规划模块是Agentic RAG的“大脑”,负责将用户查询的问题进行优化,或将复杂的问题拆解为可执行的子任务。其核心功能包括意图识别和任务优化。
例如,当用户提问“如何选择一款适合家庭使用的空气净化器?”时,规划模块会首先识别问题的核心需求(如“产品选购建议”),然后生成一系列子任务,如“检索空气净化器的核心性能指标”、“查找用户评价与口碑”、“分析不同品牌的性价比”等。
2.2.2 执行模块:知识检索与生成优化
执行模块是Agentic RAG的“双手”,负责完成具体的检索与生成任务。
其中生成优化是执行模块的关键功能。传统RAG的生成过程往往是一次性的,而Agentic RAG则引入了多轮生成与修正机制。
例如,当系统检测到生成内容中存在低可信度声明时,会自动触发修正检索,补充缺失信息或修正错误内容。
3. 技术实现
完整代码 langgraph_agentic_rag.py 已放入学习资料大礼包
完整的状态图:
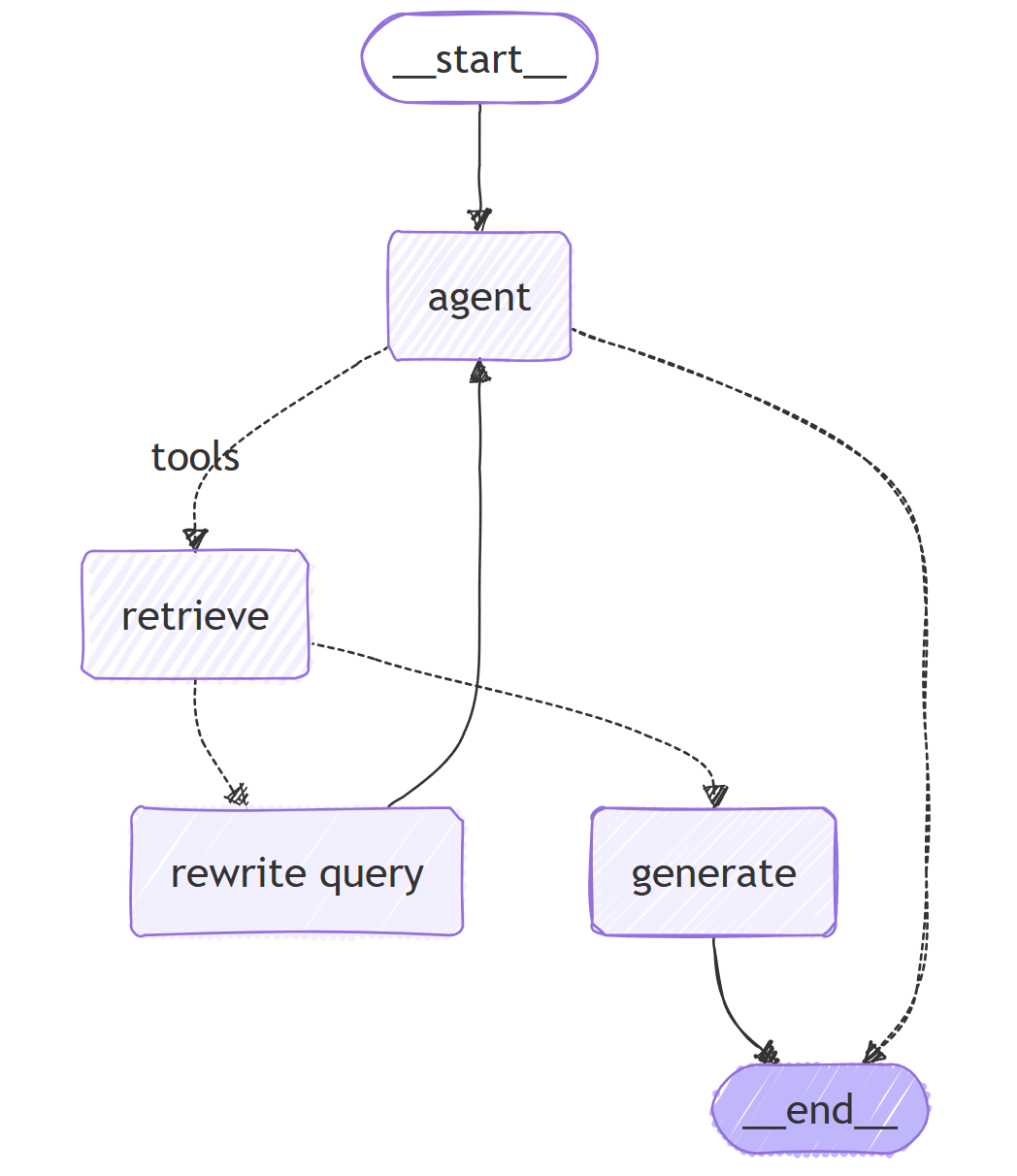
# 定义新的工作流
workflow = StateGraph(AgentState) # 使用AgentState作为状态类型
# 定义工作流中的节点
workflow.add_node("agent", agent) # 添加智能体节点
retrieve = ToolNode([retriever_tool]) # 创建检索工具节点
workflow.add_node("retrieve", retrieve) # 添加检索节点
workflow.add_node("rewrite", rewrite) # 添加问题重写节点
workflow.add_node("generate", generate) # 添加答案生成节点(在确认文档相关后使用)
# 设置初始边:从START到agent节点
workflow.add_edge(START, "agent")
# 设置条件边:根据智能体决策决定是否检索
workflow.add_conditional_edges(
"agent",
tools_condition,
{
# 将条件输出映射到图中的节点
"tools": "retrieve", # 如果需要工具,则转到retrieve节点
END: END, # 否则结束流程
},
)
# 设置检索后的条件边
workflow.add_conditional_edges(
"retrieve",
# 评估文档相关性
grade_documents,
)
# 设置固定边
workflow.add_edge("generate", END) # 生成答案后结束
workflow.add_edge("rewrite", "agent") # 重写问题后回到智能体节点
3.1 规划模块
规划模块由agent、查询优化(rewrite query)和文档相关性评估(grade_documents)共同组成
# 文档相关性评估函数
def grade_documents(state) -> Literal["generate", "rewrite"]:
"""
评估检索到的文档是否与问题相关
Args:
state (messages): 当前状态
Returns:
str: 文档是否相关的决策结果
"""
print("---检查文档相关性---")
# 数据model
class grade(BaseModel):
"""用于相关性检查的二元评分"""
binary_score: str = Field(description="相关性评分 'yes' 或 'no'")
# 初始化LLM模型
model = ChatOpenAI(temperature=0, model="gpt-4o-mini", base_url="https://api.openai-hk.com/v1",streaming=True)
# 为LLM添加结构化输出功能
llm_with_tool = model.with_structured_output(grade)
# 提示词模板
prompt = PromptTemplate(
template="""你是一个评估检索文档与用户问题相关性的评分器。\n
这是检索到的文档: \n\n {context} \n\n
这是用户的问题: {question} \n
如果文档包含与用户问题相关的关键词或语义含义,则将其评为相关。\n
给出二元评分 'yes' 或 'no' 来表示文档是否与问题相关。""",
input_variables=["context", "question"],
)
# 构建处理链
chain = prompt | llm_with_tool
# 获取消息和文档
messages = state["messages"]
last_message = messages[-1]
question = messages[0].content
docs = last_message.content
# 执行评估
scored_result = chain.invoke({"question": question, "context": docs})
score = scored_result.binary_score
# 根据评分返回决策
if score == "yes":
print("---决策: 文档相关---")
return"generate"
else:
print("---决策: 文档不相关---")
print(score)
return"rewrite"
### Nodes
def agent(state):
"""
调用智能体模型根据当前状态生成响应。根据问题决定是否使用检索器工具或直接结束。
Args:
state (messages): 当前状态
Returns:
dict: 更新后的状态,包含附加到消息中的智能体响应
"""
print("---调用智能体---")
messages = state["messages"] # 获取当前消息
model = ChatOpenAI(temperature=0, streaming=True, base_url="https://api.openai-hk.com/v1",model="gpt-4o-mini") # 初始化LLM模型
model = model.bind_tools(tools) # 绑定工具
response = model.invoke(messages) # 调用模型生成响应
return {"messages": [response]} # 返回更新后的消息列表
def rewrite(state):
"""
转换查询以生成更好的问题。
Args:
state (messages): 当前状态
Returns:
dict: 更新后的状态,包含重新表述的问题
"""
print("---转换查询---")
messages = state["messages"] # 获取当前消息
question = messages[0].content # 获取原始问题
# 构建改进问题的提示
msg = [
HumanMessage(
content=f""" \n
查看输入并尝试理解其潜在的语义意图/含义。\n
这是初始问题:
\n ------- \n
{question}
\n ------- \n
请提出一个改进后的问题: """,
)
]
# 初始化LLM模型
model = ChatOpenAI(temperature=0, base_url="https://api.openai-hk.com/v1",model="gpt-4o-mini", streaming=True)
response = model.invoke(msg) # 生成改进后的问题
return {"messages": [response]} # 返回更新后的消息
3.2 执行模块
执行模块由retrieve、generate组成
# 定义要处理的网页URL列表
urls = [
"https://lilianweng.github.io/posts/2023-06-23-agent/",
"https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/",
"https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/",
]
# 加载所有网页文档
docs = [WebBaseLoader(url).load() for url in urls]
# 将嵌套列表展平为一维列表
docs_list = [item for sublist in docs for item in sublist]
# 创建文本分割器实例
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=100, chunk_overlap=50
)
# 执行文档分割操作
doc_splits = text_splitter.split_documents(docs_list)
# 初始化嵌入模型
embedding_llm = OpenAIEmbeddings(
base_url="https://api.openai-hk.com/v1"
)
# 创建向量数据库实例
vectorstore = Chroma.from_documents(
documents=doc_splits, # 分割后的文档
collection_name="rag-chroma", # 集合名称
persist_directory="./chroma_db", # 持久化存储目录
embedding=embedding_llm, # 使用的嵌入模型
)
# 创建检索器实例
retriever = vectorstore.as_retriever() # 将向量数据库转换为检索器
########################################################################################################################
# 导入检索器工具创建函数
from langchain.tools.retriever import create_retriever_tool
# 创建检索器工具实例
retriever_tool = create_retriever_tool(
retriever, # 检索器实例
"retrieve_blog_posts", # 工具名称
"搜索并返回有关 Lilian Weng 博文的信息,内容涉及 LLM agents、提示工程和对 LLMs 的对抗性攻击。", # 工具描述
)
def generate(state):
"""
生成答案
Args:
state (messages): 当前状态
Returns:
dict: 更新后的状态,包含生成的答案
"""
print("---生成答案---")
messages = state["messages"] # 获取当前消息
question = messages[0].content # 获取问题
last_message = messages[-1] # 获取最后一条消息
docs = last_message.content # 获取检索到的文档
# 获取RAG提示词模板
prompt = hub.pull("rlm/rag-prompt")
# 初始化LLM模型
llm = ChatOpenAI(base_url="https://api.openai-hk.com/v1",model_name="gpt-4o-mini", temperature=0, streaming=True)
# 文档格式化函数
def format_docs(docs):
return"\n\n".join(doc.page_content for doc in docs) # 将多个文档内容合并
# 构建RAG处理链
rag_chain = prompt | llm | StrOutputParser()
# 执行RAG链生成答案
response = rag_chain.invoke({"context": docs, "question": question})
return {"messages": [response]} # 返回包含答案的更新后消息
prompt = hub.pull("rlm/rag-prompt").pretty_print()
4. Agentic RAG 的局限性
尽管Agentic RAG展现了巨大的潜力,但其发展仍面临诸多局限:
计算延迟:
多轮检索与修正机制显著增加了计算开销。
计算成本激增:
多轮检索与评估使API调用次数大幅度增长。
责任归属困境:
当自主生成的医疗建议导致误诊时,责任归属不明确
Agentic RAG不仅代表着技术的迭代,更预示着人机协作模式的根本变革。当系统能够自主完成需求分析→知识检索→逻辑推理→结果验证的全流程时,人类专家得以从信息过载中解放,专注于更高阶的创造性工作。
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 490
490

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









