







仅用1.6万张医学影像,我们让大模型学会了“看片子”。
患者提问:“请使用中文详细描述这张图像并给出你的诊断结果。”
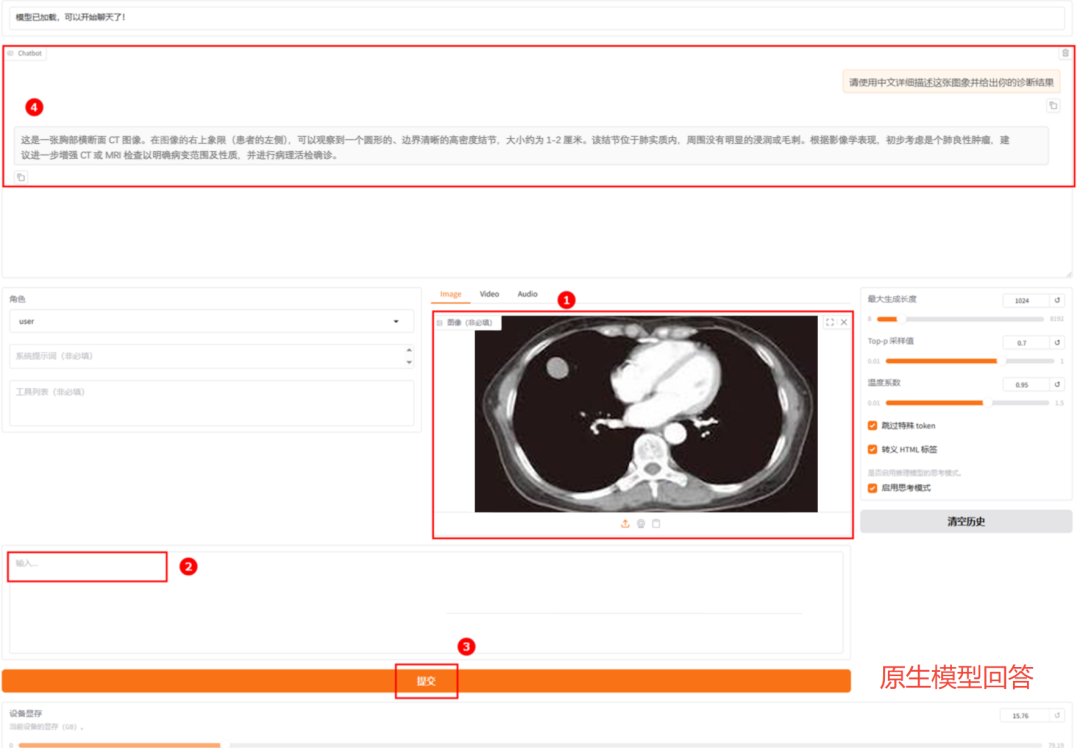
这是微调前模型的回答。虽然能够识别出基本病变,但其分析存在明显不足,描述过于简略,仅关注单一病灶而忽略了图像中实际存在的双肺多发性结节,且诊断结论过于武断,直接定性为"良性肿瘤",缺乏严谨的鉴别诊断思路,临床参考价值有限。
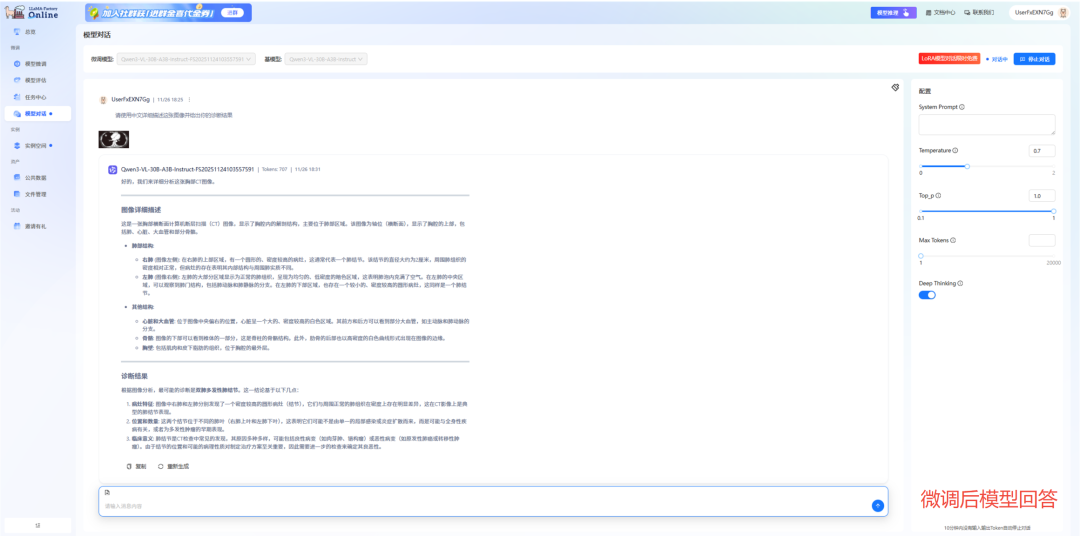
这是微调后模型的回答。它成功化身为“严谨的放射科医生”,不仅准确定位双肺病灶,系统分析肺部结构、心脏大血管和骨骼关系,更能从病灶特征、位置分布和临床意义多个维度进行专业解读,提供完整的鉴别诊断思路,其描述精准、逻辑严密、术语规范,已达到辅助医生进行临床决策的实用水平。
通过以上对比可以直观地看到,经过高质量数据微调后的模型,成功地从一位“门外汉”进化为了可靠的“AI放射科医生”。
过去两三年,大模型已经从“新鲜事”变成了许多人工作与生活的一部分。从ChatGPT到Qwen、DeepSeek,模型的通用能力不断突破,但在真实业务场景中,许多团队和开发者却面临这样的窘境:模型“什么都能聊”,却总在专业问题上“答不到点子上”。
要让大模型真正理解行业、服务业务,微调已成为必经之路。然而,传统微调路径依然被高门槛重重封锁——环境配置复杂、GPU算力成本高昂、调参过程晦涩难懂,让许多团队望而却步。
现在,这一切有了更简单的答案。LLaMA-Factory Online将微调门槛降至新低,定制一个专属模型就和打开浏览器一样简单。
1、LLaMA-Factory Online
打破医疗AI的“不可能三角”
当前,通用视觉大模型在医疗影像场景中存在三大瓶颈
● 细节捕捉弱:难以看懂高分辨率(CT/MR)影像中的微小病灶
● 显存占用高:动辄数十GB的显存需求,边缘设备跑不动,难以临床部署;
● 专业表述差:生成内容缺乏临床术语,可信度低,难以支撑临床实时分析需求。
今天,我们将完整揭秘:如何基于LLaMA-Factory Online,仅用 1.6万条数据,在Qwen3-VL-30B-A3B模型上,训练出一个真正的“医疗影像专家”。我们不仅会讲“怎么练”,更会用实测数据告诉你怎么用!
2、LLaMA-Factory Online
稀疏激活 + 高效微调
在医疗场景下,我们面临着“既要马儿跑,又要马儿少吃草”的悖论
● 要精度: 必须看懂高分辨率CT/MR,参数量不能小(30B级别)
● 要成本: 医院边缘设备显存有限,跑不动庞然大物
我们在LLaMA-Factory Online上选择了Qwen3-VL-30B-A3B-Instruct,正是因为它采用了“稀疏激活(Active 3B)”架构。它拥有300亿参数的知识储备,但推理时仅激活30亿参数——这为低成本落地埋下了伏笔。

3、LLaMA-Factory Online
从数据到可对话的医疗专家
01 数据加工:把“医学教材”喂给AI
高质量、格式规范的数据集是成功的关键。我们通过以下流程将原始医学数据转化为模型可理解的“教材”:
● 下载数据:从MedTrinity-25M数据集中精选1.6万条高质量影像-文本对
● 格式转换:使用定制Python脚本,将原始数据转换为LLaMA-Factory Online支持的 ShareGPT多模态对话格式
● 质量验证:通过随机抽样与基线模型测试验证数据有效性。
核心代码详解:我们提供了完整的数据格式转换脚本,将原始Parquet数据转换为模型可训练的格式。
<!--p.MsoNormal{
mso-style-name: 正文;
mso-style-parent: "";
margin: 0pt;
margin-bottom: .0001pt;
mso-pagination: none;
text-justify: inter-ideograph;
mso-font-kerning: 1.0000pt;
font-size: 11pt;
}
p.paragraph{
mso-style-noshow: yes;
margin-top: 5.0000pt;
margin-right: 0.0000pt;
margin-bottom: 5.0000pt;
margin-left: 0.0000pt;
mso-margin-top-alt: auto;
mso-margin-bottom-alt: auto;
text-align: left;
font-family: 等线;
mso-bidi-font-family: 'Times New Roman';
font-size: 12.0000pt;
}
-->
#多模态数据格式转换代码
import os
import json
import random
from tqdm import tqdm
import datasets
def save_images_and_json(ds, ratio=0.1, output_dir="mllm_data"):
"""
保存数据集中的图像,并且构建多模态训练集和验证集。
参数:
ds: 数据集对象,包含图像和描述。
ratio: 验证集比例,默认为 0.1。
output_dir: 输出目录,默认为 "mllm_data"。
"""
# 创建输出目录
os.makedirs(output_dir, exist_ok=True)
all_train_data = [] # 多模态训练数据
all_val_data = [] # 多模态验证数据
total_samples = len(ds)
val_index = set(random.sample(range(total_samples), int(ratio * total_samples)))
# 遍历数据集中的每个项目
for idx, item in tqdm(enumerate(ds), total=total_samples, desc="Processing"):
img_path = os.path.join(output_dir, f"{item['id']}.jpg")
image = item["image"]
# 保存图像
image.save(img_path)
sample = {
"messages": [
{
"role": "user",
"content": "<image>图片中的诊断结果是怎样?"
},
{
"role": "assistant",
"content": item["caption"] # 从数据集中获取的描述
}
],
"images": [img_path] # 图像文件路径
}
if idx in val_index:
all_val_data.append(sample)
else:
all_train_data.append(sample)
# 将数据保存到 JSON 文件
train_json_path = os.path.join(output_dir, "mllm_train_data.json")
val_json_path = os.path.join(output_dir, "mllm_val_data.json")
with open(train_json_path, "w", encoding="utf-8") as f:
json.dump(all_train_data, f, ensure_ascii=False, indent=2)
with open(val_json_path, "w", encoding="utf-8") as f:
json.dump(all_val_data, f, ensure_ascii=False, indent=2)
if __name__ == "__main__":
# 加载数据集
ds = datasets.load_dataset("parquet", data_files="../dataset/data_sft/train-00000-of-00010.parquet")["train"]
# 保存图像并构建多模态训练/验证集
save_images_and_json(
ds,
ratio=0.2,
output_dir="/workspace/user-data/codelab/Qwen3-VL/dataset/mllm_data"
)
转换后的数据示例如下:
<!--p.MsoNormal{
mso-style-name: 正文;
mso-style-parent: "";
margin: 0pt;
margin-bottom: .0001pt;
mso-pagination: none;
text-justify: inter-ideograph;
mso-font-kerning: 1.0000pt;
font-size: 11pt;
}
p.paragraph{
mso-style-noshow: yes;
margin-top: 5.0000pt;
margin-right: 0.0000pt;
margin-bottom: 5.0000pt;
margin-left: 0.0000pt;
mso-margin-top-alt: auto;
mso-margin-bottom-alt: auto;
text-align: left;
font-family: 等线;
mso-bidi-font-family: 'Times New Roman';
font-size: 12.0000pt;
}
-->
[
{
"messages": [
{
"role": "user",
"content": "<image>图片中的诊断结果是怎样?"
},
{
"role": "assistant",
"content": "这是一张非增强脑部计算机断层扫描(CT)图像,图中未见任何医疗设备。位于图像中央的兴趣区域可见密度改变,提示脑内出血。该异常区域与周围脑组织分界清晰,可能为脑实质内血肿或出血。其位置及表现可能与邻近脑组织存在关联,进而产生占位效应或导致颅内压升高。"
}
],
"images": [
"/workspace/user-data/codelab/Qwen3-VL/dataset/mllm_data/8031efe0-1b5c-11ef-8929-000066532cad.jpg"
]
},
{
"messages": [
{
"role": "user",
"content": "<image>图片中的诊断结果是怎样?"
},
{
"role": "assistant",
"content": "这是一张脑部非增强计算机断层扫描(CT)图像,显示双侧大脑半球,图中无医疗器械。感兴趣区域位于脑中央偏下方,约占图像面积的 1.1%,表现异常,提示可能存在病变:其密度或纹理改变符合颅内出血特征。该区域与周围脑结构紧邻,可能对邻近组织产生压迫,或受邻近组织影响,提示病变可能正在扩展,并可能影响周边组织功能。"
}
],
"images": [
"/workspace/user-data/codelab/Qwen3-VL/dataset/mllm_data/803201d1-1b5c-11ef-bba0-000066532cad.jpg"
]
},
]
02 模型训练:找到医疗影像的“学习密码”
训练一个专业模型,不仅是“跑起来”,更要“学得好”。参数调优就是寻找最佳“学习方案”的过程。我们通过严谨的对比实验,揭示了影响医疗影像学习效果的关键因素。
(1)DeepSpeed Stage选择是性能关键
在微调30B级别大模型时,很多人的第一反应是无脑开DeepSpeed Stage 3以节省显存。但在医疗影像这种需要极高精度的任务中,我们通过实战验证了一个残酷的真相:
● 误区(DeepSpeed Stage 3): 虽然显存占用低,但在医疗细粒度特征上,Loss 下降缓慢。原因在于Stage 3的“参数延迟+梯度噪声”机制,干扰了模型对微小病灶的学习
● 正解(DeepSpeed Stage 2): 虽然显存占用稍高,但loss曲线如丝般顺滑,收敛更彻底
独家心法:在LLaMA-Factory Online配置时,若显存允许(如使用 H800),请果断选择Stage 2。如果必须用Stage 3,请务必配合“放大Global Batch Size+拉长Warmup”的组合拳来弥补性能损失。
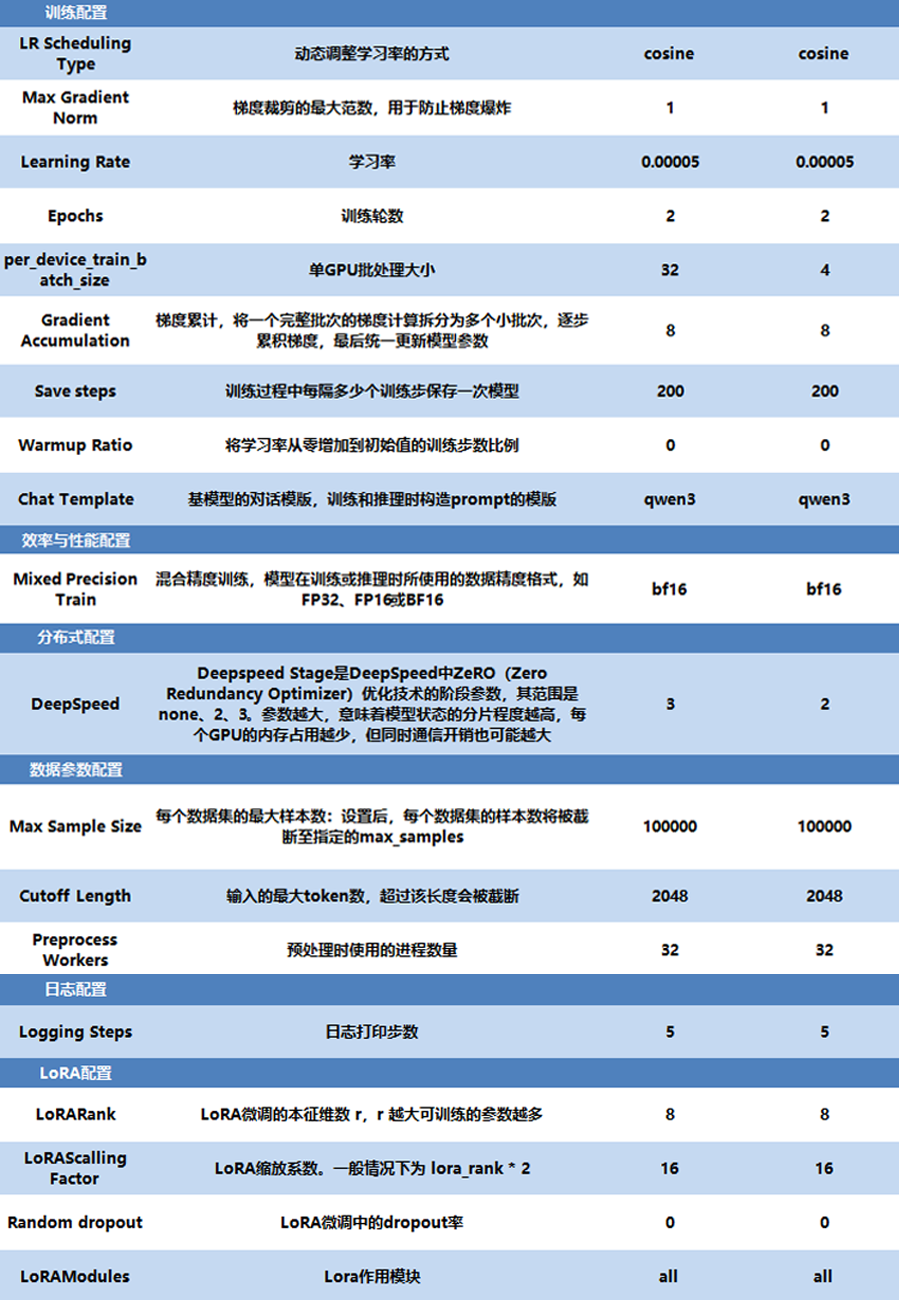
(2)参数配置对比实验与分析
为验证上述发现,在任务模式下,我们对模型进行了两组微调实验(参数一和参数二),以评估不同配置的效果。两组实验的变量仅为 per_device_train_batch_size(32,4)和DeepSpeed(3,2)参数,其他条件完全相同。具体参数差异如下表所示:
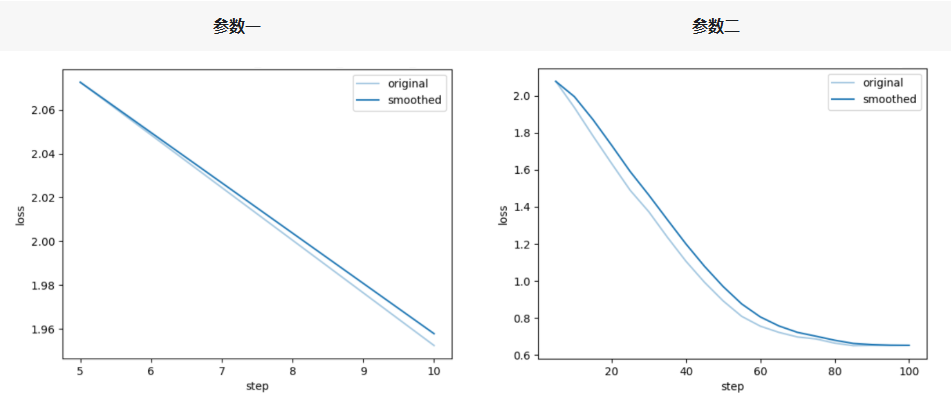
通过任务模式完成两组参数配置的模型微调后,从loss对比结果来看,相同硬件与数据集条件下,deepseed 3(参数一)方案训练速度更快,但微调阶段loss显著上升;deepseed 2(参数二)方案虽训练速度略有下降,却能更有效地压低loss。具体来看:
● deepseed 3训练速度的提升,核心得益于 “小块通讯 + 微批次自动放大” 带来的带宽优化;
● deepseed 3微调loss上涨的本质,是 “参数延迟 + 梯度噪声” 导致模型收敛效果变差;
选型建议:若显存充足,优先选择deepseed 2方案以追求更优指标;若显存不足需使用deepseed 3,则需同步通过放大global batch、拉长 warmup时长、降低学习率(lr)的方式弥补收敛性能。
通过反复实验,我们总结出了一套适用于Qwen3-VL医疗微调的参数心法:
● LR Scheduler(学习率调度): 放弃Linear!在多模态图文对齐任务中,Linear衰减表现平平。请选择 Cosine + Warmup,它能更好地适配视觉特征的学习节奏
● Epoch(训练轮数):在16k数据场景下,3个Epoch是性能拐点;第4个Epoch起训练Loss仍降,但验证指标不再上升,属于典型过拟合;5k 小数据场景下可拉到6~8Epoch
● LoRARank:医疗影像细节极多(如微小结节、毛刺征),低Rank(如8以下)表达能力不足。Rank 32是效果与成本的性价比拐点
● Alpha值: 死磕公式Alpha = Rank×2,稳定性最佳
● dropout:数据量 ≤ 10k时,设置dropout=0.05 可有效防过拟合;数据 > 10k:可直接设为0
03 效果验证:从“业余”到“专业”的飞跃
经过精心的微调,模型的性能实现了质的飞跃。我们通过量化指标和定性分析,全方位评估其提升效果。
(1)指标对比:数十倍至上千倍的提升
下面的数据清晰地展示了模型在微调前后的巨大变化。其中,参数二(DeepSpeed Z2方案)在各项文本生成质量指标上达到了最优水平。
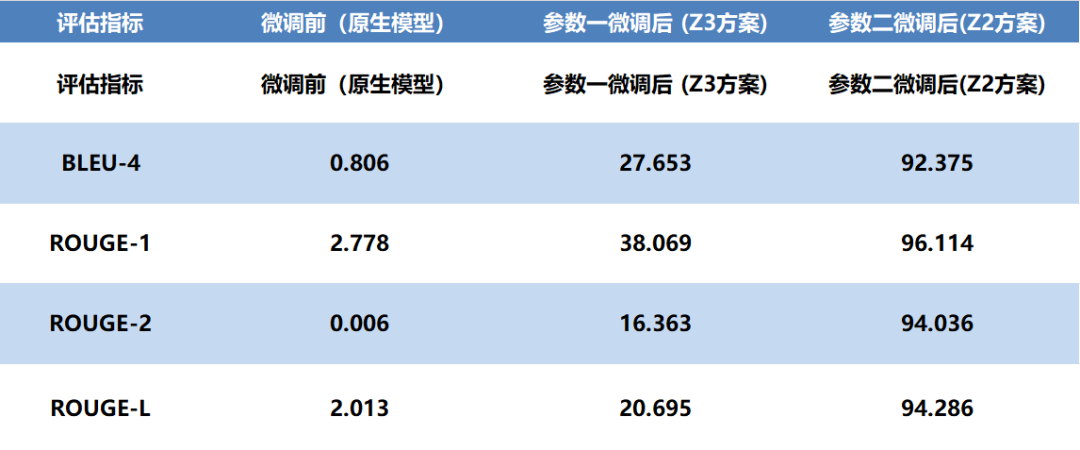
指标解读:
● BLEU-4衡量生成文本与专业参考答案在词组和表达上的匹配度
● ROUGE-1/2/L综合评估生成内容的关键词覆盖、短语搭配和句法连贯性
结论一目了然:采用Z2方案微调的模型(参数二),其生成质量远超原生模型和Z3方案,在专业术语、句式结构和临床逻辑上都与标准医学描述高度一致。
(2)生成质量:从“无法使用”到“专业优秀”
● 微调前(原生模型):各项指标极低,生成内容与参考答案关联性微弱,逻辑混乱,完全无法满足专业场景需求
● 微调后(参数二模型):
○ BLEU-4高达92.37,意味着模型能精准复现医学报告中的专业词汇与表达
○ ROUGE系列指标均超过94,代表其在关键词捕捉、专业短语运用和长篇报告的连贯性上表现出色
○ 生成文本的质量已达到优秀级别,具备临床应用的潜力
(3)效率提升:速度与精度的双重胜利
除了生成质量,推理效率也得到显著优化。
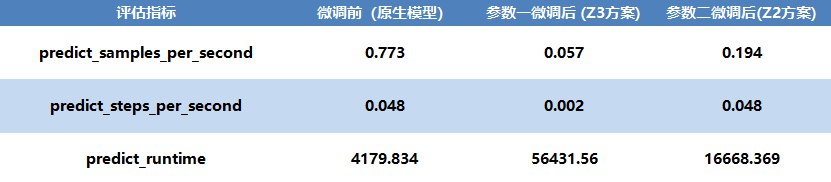
微调不仅解决了原生模型生成质量“不可用”的核心问题,更在效率上实现了超越。最终得到的模型在专业性、准确性和响应速度上取得了完美平衡,可立即投入医学影像报告生成、辅助诊断等严肃多模态场景。
4、LLaMA-Factory Online
真正的“AI放射科医生”
模型性能的最终检验标准在于实战。我们对比了参数一(Z3方案)与参数二(Z2方案)微调后的模型对同一张胸部CT影像的分析,结果显示两者均达到专业水准,但在分析的全面性、细致程度和诊断深度上存在显著差异。
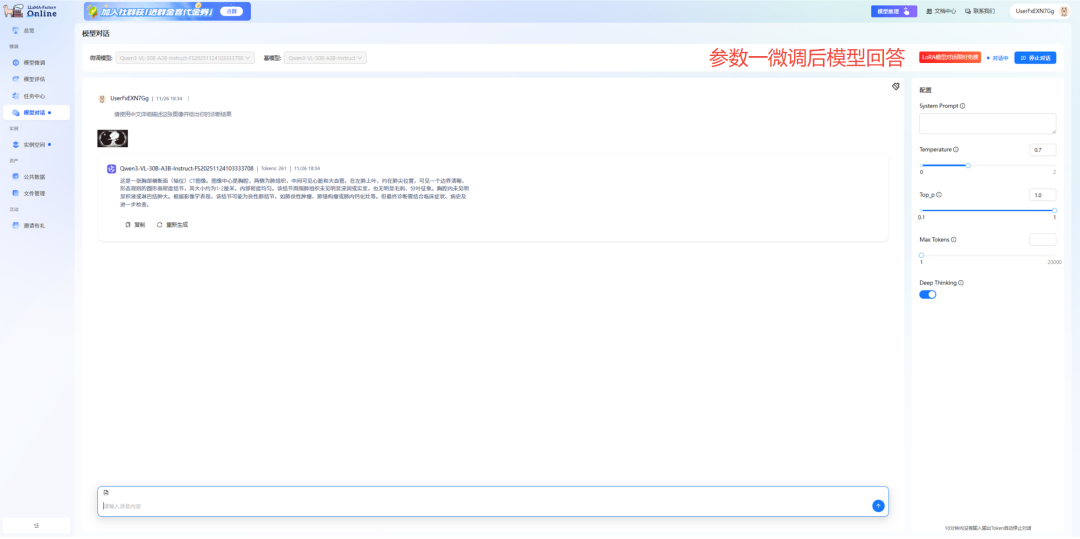
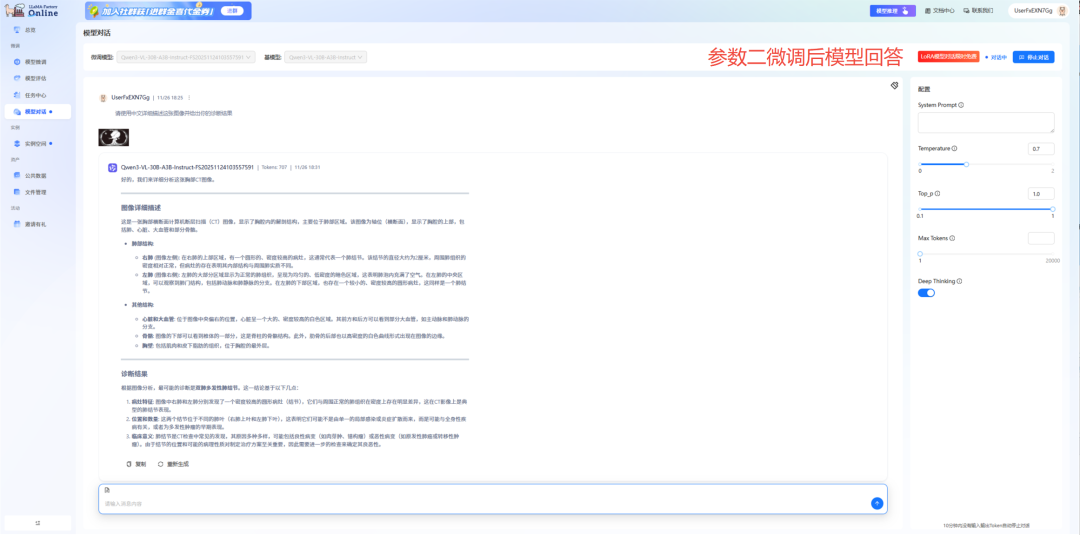
通过对比分析,我们验证了一个重要结论,参数二(Z2方案)在以下方面表现显著更优:
● 观察敏锐度:能够发现图像中的多个病灶,避免漏诊
● 分析系统性:提供从解剖结构到病变特征的完整分析框架
● 诊断严谨性:基于医学证据进行推理,给出合理的鉴别诊断
● 临床实用性:回答具有直接临床参考价值
这一结果与我们之前的实验数据高度吻合——Z3方案虽然在训练速度上稍慢,但能够学习到更丰富的医学知识结构和诊断逻辑,最终生成的影像报告更接近资深放射科医生的专业水准。
通过Qwen3-VL-30B-A3B-Instruct与LLaMA-Factory Online,我们再次验证了:即使是顶尖的通用大模型,在经过高质量的领域数据微调后,也能在高度专业的场景(如医疗影像分析)中展现出卓越性能。
技术的价值在于落地。无论是医疗、金融、法律还是教育,LLaMA-Factory Online致力于将大模型微调的技术复杂性封装起来,让每一位开发者和企业都能轻松打造属于自己的、安全可靠的“行业专家”。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









