







大模型分布式训练(DP、TP、PP、CP、EP、SP)六大并行策略深度解析-从原理到实践
前言
最近几个月在做大模型训练优化的时候,经常有同学问我关于分布式并行策略的问题。说实话,刚开始接触这块的时候,虽然看过不少文档和调研过不少工具,但也被各种并行方式搞得云里雾里。数据并行、张量并行、流水线并行,还有什么序列并行、上下文并行、专家并行,光是名字就让人头大。
今天就来好好捋一捋这六种主流的分布式并行策略。这些内容都是我在实际训练千亿参数模型时踩过的坑和积累的经验,希望能帮大家少走些弯路。
一、为什么必须要用分布式并行?
先说个实际的例子。前段时间我们要训练一个70B参数的模型,光是模型权重就需要140GB的存储空间(FP16精度),而我们的A100显存只有80GB,根本装不下。更别提训练时还需要存储优化器状态、梯度和中间激活值,内存需求直接飙到TB级别。
这就是现实:单张GPU或TPU的算力和显存已经远远无法满足大模型的需求了。根据的调研,分布式训练已经不是可选项,而是必经之路。
我把这六种并行策略分成三个大类来讲解:
- 基础并行策略:数据并行(DP)、张量并行(TP)、流水线并行(PP)
- 长序列并行策略:序列并行(SP)、上下文并行(CP)
- 稀疏化并行策略:专家并行(EP)
二、基础并行策略详解
2.1 数据并行(Data Parallelism, DP)
数据并行是最容易理解的一种方式。简单来说就是"模型复制,数据分片"。
核心原理
数据并行的核心思想是在每张计算卡上都放置一份完整的模型副本,然后将训练数据的批次分割成多个更小的微批次,每个设备独立处理一个微批次。
让我用代码来说明整个工作流程:
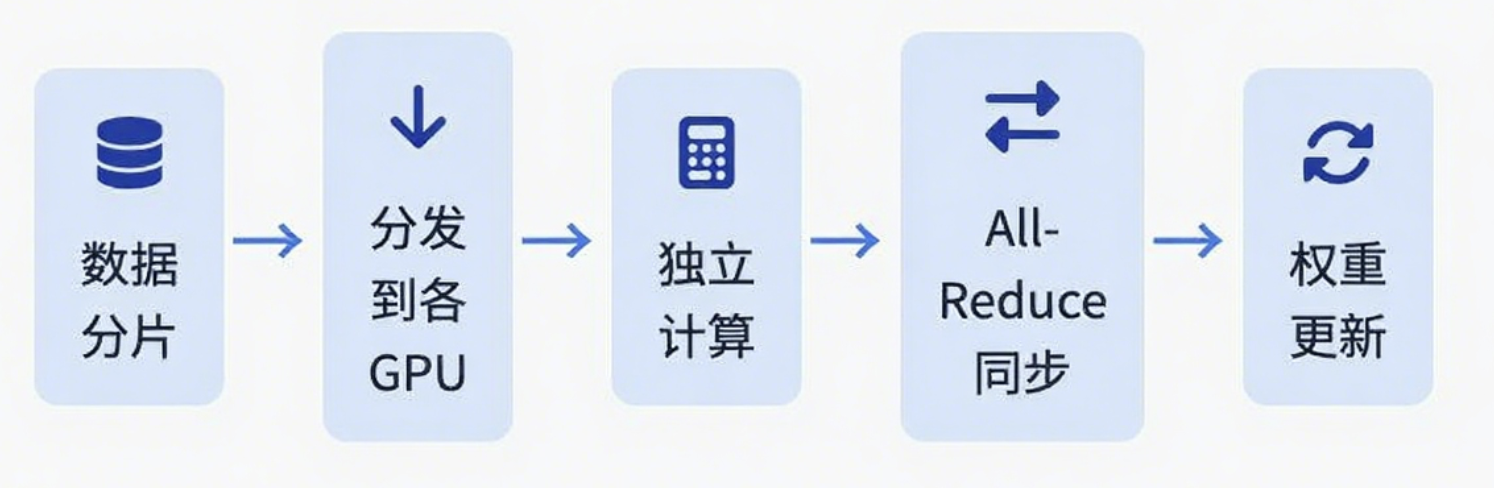
# 伪代码展示数据并行的核心流程
class DataParallelTraining:
def __init__(self, model, num_gpus):
self.num_gpus = num_gpus
# 每个GPU上都有完整的模型副本
self.model_replicas = [copy.deepcopy(model) for _ in range(num_gpus)]
def train_step(self, global_batch):
# 1. 数据分发:将批次切分
micro_batches = split_batch(global_batch, self.num_gpus)
# 2. 并行计算前向和反向传播
gradients = []
for gpu_id, micro_batch in enumerate(micro_batches):
with device(gpu_id):
loss = self.model_replicas[gpu_id].forward(micro_batch)
grad = self.model_replicas[gpu_id].backward(loss)
gradients.append(grad)
# 3. 梯度同步(All-Reduce操作)
synchronized_grad = all_reduce(gradients) # 关键步骤!
# 4. 更新所有模型副本
for gpu_id in range(self.num_gpus):
self.model_replicas[gpu_id].update_weights(synchronized_grad)
这里最关键的是All-Reduce操作。什么是All-Reduce呢?就是每个GPU把自己的梯度发送给其他所有GPU,然后每个GPU对接收到的梯度进行求和或平均。这样保证了所有GPU上的模型副本保持一致。
优缺点分析
我在实际使用中发现数据并行有这些特点:
优点:
- 实现简单,大部分框架都原生支持
- 适用于各种模型架构
- 扩展相对容易
缺点:
- 内存瓶颈明显,每个GPU都要存完整模型
- GPU数量增加后,通信开销会成为瓶颈
- 对于超大模型,单卡放不下就没法用了
ZeRO优化技术
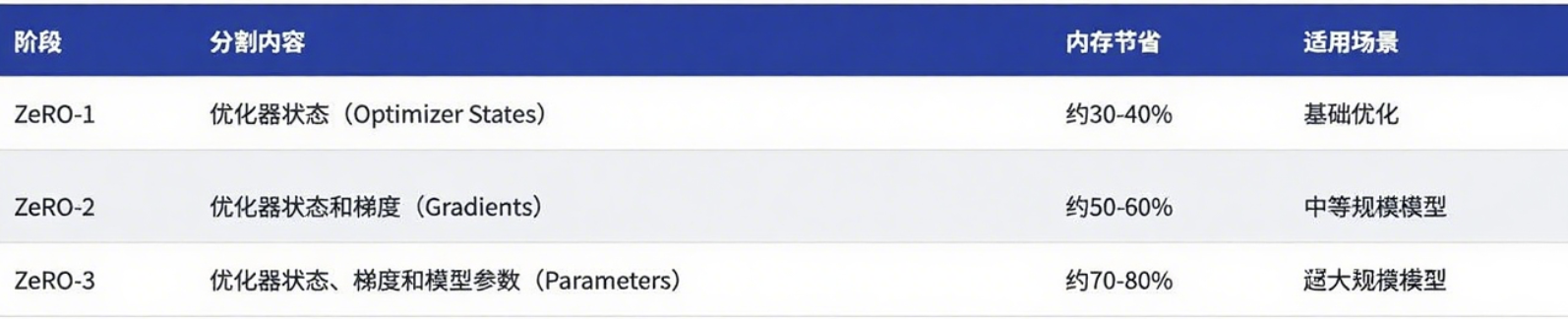
为了解决内存冗余问题,微软提出了ZeRO(Zero Redundancy Optimizer)技术。ZeRO通过在不同设备间分割模型状态来优化内存使用:
# ZeRO的三个优化级别
class ZeROOptimization:
def __init__(self, level):
self.level = level
def partition_model_states(self):
if self.level == 1:
# ZeRO-1: 只分割优化器状态
return partition_optimizer_states()
elif self.level == 2:
# ZeRO-2: 分割优化器状态 + 梯度
return partition_optimizer_and_gradients()
elif self.level == 3:
# ZeRO-3: 分割优化器状态 + 梯度 + 模型参数
return partition_all_model_states()
使用ZeRO-3后,即使是单卡装不下的模型也能通过数据并行来训练了。
2.2 张量并行(Tensor Parallelism, TP)
当激活内存超过显存预算时,数据并行就不够用了。这时候就需要张量并行。
核心原理
张量并行的核心是利用矩阵乘法的数学特性。一个矩阵乘法A×B可以通过分别计算B的每一列或A的每一行,然后组合结果来完成。
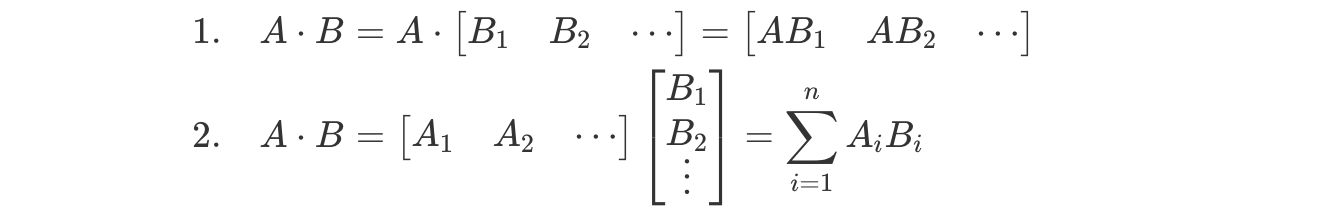
Transformer中的张量并行实现
在Transformer的MLP层中,张量并行的实现特别优雅。以两个线性变换为例:
class ParallelMLP:
def __init__(self, hidden_size, num_gpus):
self.num_gpus = num_gpus
# 第一个线性层:列并行
self.W1_columns = split_column_wise(W1, num_gpus)
# 第二个线性层:行并行
self.W2_rows = split_row_wise(W2, num_gpus)
def forward(self, x):
# 1. 输入x被广播到所有GPU
x_replicated = broadcast(x, self.num_gpus)
# 2. 第一个线性层(列并行)
y_parts = []
for gpu_id in range(self.num_gpus):
y_part = x_replicated @ self.W1_columns[gpu_id]
y_parts.append(activation(y_part))
# 3. All-Gather操作,收集所有部分
y_full = all_gather(y_parts)
# 4. 第二个线性层(行并行)
z_parts = []
for gpu_id in range(self.num_gpus):
z_part = y_full @ self.W2_rows[gpu_id]
z_parts.append(z_part)
# 5. Reduce-Scatter,求和并分散结果
output = reduce_scatter(z_parts)
return output
这里涉及几个重要的通信原语:
- Broadcast(广播):将一个GPU的数据发送到所有GPU
- All-Gather(全聚合):每个GPU把数据发送到所有GPU,然后拼接
- Reduce-Scatter(散播归约):先求和再分散到各GPU
实际应用
张量并行在单节点内效果最好,因为节点内的NVLink带宽高。跨节点使用张量并行会导致严重的通信瓶颈。
我的经验是:
- TP度数一般设为2、4或8
- 优先在单机内使用TP
- 配合PP使用效果更好
2.3 流水线并行(Pipeline Parallelism, PP)
流水线并行是另一种解决"模型太大"问题的方法,它将模型按层切分到不同GPU上。

核心原理
想象一下工厂的流水线:第一个工人负责零件A,第二个工人负责零件B,以此类推。流水线并行就是这个思路。
class PipelineParallel:
def __init__(self, model, num_stages):
self.num_stages = num_stages
# 将模型切分成多个阶段
self.stages = split_model_into_stages(model, num_stages)
def forward_with_microbatches(self, batch, num_microbatches):
# 将批次切分成微批次
microbatches = split(batch, num_microbatches)
# 流水线调度
schedule = []
for mb_idx, microbatch in enumerate(microbatches):
for stage_idx in range(self.num_stages):
# 计算这个微批次在这个阶段的执行时间
time_slot = mb_idx + stage_idx
schedule.append((time_slot, stage_idx, mb_idx))
# 按时间顺序执行
for time_slot in range(max_time_slots):
parallel_execute_stages(schedule, time_slot)
气泡问题及优化
朴素的流水线会产生严重的"气泡"(bubble)问题,就是GPU空闲等待。GPipe通过微批次技术缓解了这个问题:
时间 →
GPU0: [MB1-F][MB2-F][MB3-F][idle ][MB1-B][MB2-B][MB3-B]
GPU1: [idle ][MB1-F][MB2-F][MB3-F][MB1-B][MB2-B][MB3-B]
GPU2: [idle ][idle ][MB1-F][MB2-F][MB3-F][MB1-B][MB2-B]
F=前向传播, B=反向传播, MB=微批次
可以看到,通过微批次,我们让多个GPU能够同时工作,减少了空闲时间。
优缺点总结
优点:
- 通信开销相对较低,只在相邻阶段间通信
- 实现相对简单
- 内存占用显著降低
缺点:
- 气泡问题无法完全消除
- 需要合理切分模型保证负载均衡
- 存在木桶效应,最慢的阶段决定整体速度
三、长序列并行策略
随着应用需求的发展,处理长文本成为新的挑战。传统的并行策略主要解决参数存储问题,而序列并行和上下文并行专门解决长序列导致的激活值内存爆炸。
3.1 序列并行(Sequence Parallelism, SP)
核心思想
Transformer的自注意力机制需要在序列维度上进行全局计算,这让序列并行变得困难。序列并行的巧妙之处在于,它选择性地对那些在序列维度上计算独立的模块进行切分。
class SequenceParallel:
def __init__(self, seq_parallel_size):
self.sp_size = seq_parallel_size
def forward(self, x, module_type):
if module_type in ['LayerNorm', 'Dropout', 'MLP_pointwise']:
# 这些操作在序列维度上是独立的,可以切分
x_chunks = split_sequence(x, self.sp_size)
outputs = parallel_compute(x_chunks)
return outputs
elif module_type == 'SelfAttention':
# 注意力需要全局信息,先聚合
x_full = all_gather(x, dim='sequence')
attn_output = compute_attention(x_full)
# 计算完后可以再切分
return scatter(attn_output, dim='sequence')
与张量并行的协同
序列并行通常与张量并行配合使用。根据研究,SP+TP的组合可以显著降低激活值内存:
# 激活值内存计算
def calculate_activation_memory(seq_len, hidden_size, batch_size):
# 不使用SP
memory_without_sp = seq_len * hidden_size * batch_size
# 使用SP(假设SP度=4)
memory_with_sp = (seq_len / 4) * hidden_size * batch_size
reduction_ratio = 1 - (memory_with_sp / memory_without_sp)
print(f"内存减少: {reduction_ratio * 100:.1f}%")
3.2 上下文并行(Context Parallelism, CP)
上下文并行是处理超长序列的更激进策略。
工作原理
CP将输入序列和所有中间激活都沿序列维度划分。关键在于注意力机制的处理:
class ContextParallel:
def __init__(self, context_parallel_size):
self.cp_size = context_parallel_size
def attention_with_cp(self, input_seq):
# 1. 输入序列切分
seq_chunks = split(input_seq, self.cp_size)
# 2. 每个GPU计算局部Q、K、V
local_qkv = []
for chunk in seq_chunks:
q, k, v = compute_qkv(chunk)
local_qkv.append((q, k, v))
# 3. 关键步骤:All-Gather K和V
global_k = all_gather([kv[1] for kv in local_qkv])
global_v = all_gather([kv[2] for kv in local_qkv])
# 4. 每个GPU用局部Q和全局K、V计算注意力
outputs = []
for local_q, _, _ in local_qkv:
attn_out = compute_attention(local_q, global_k, global_v)
outputs.append(attn_out)
return outputs
应用场景
CP在处理超长上下文(如128K、256K tokens)时效果显著。我在实际项目中的经验:
- 序列长度超过32K时考虑使用CP
- CP的通信开销大,需要高带宽互联
- 与其他并行策略组合使用效果更好
使用工具

四、稀疏化并行策略:专家并行
当模型参数达到万亿级别,传统的密集模型已经无法训练了。混合专家(MoE)架构提供了新思路。
4.1 MoE架构原理
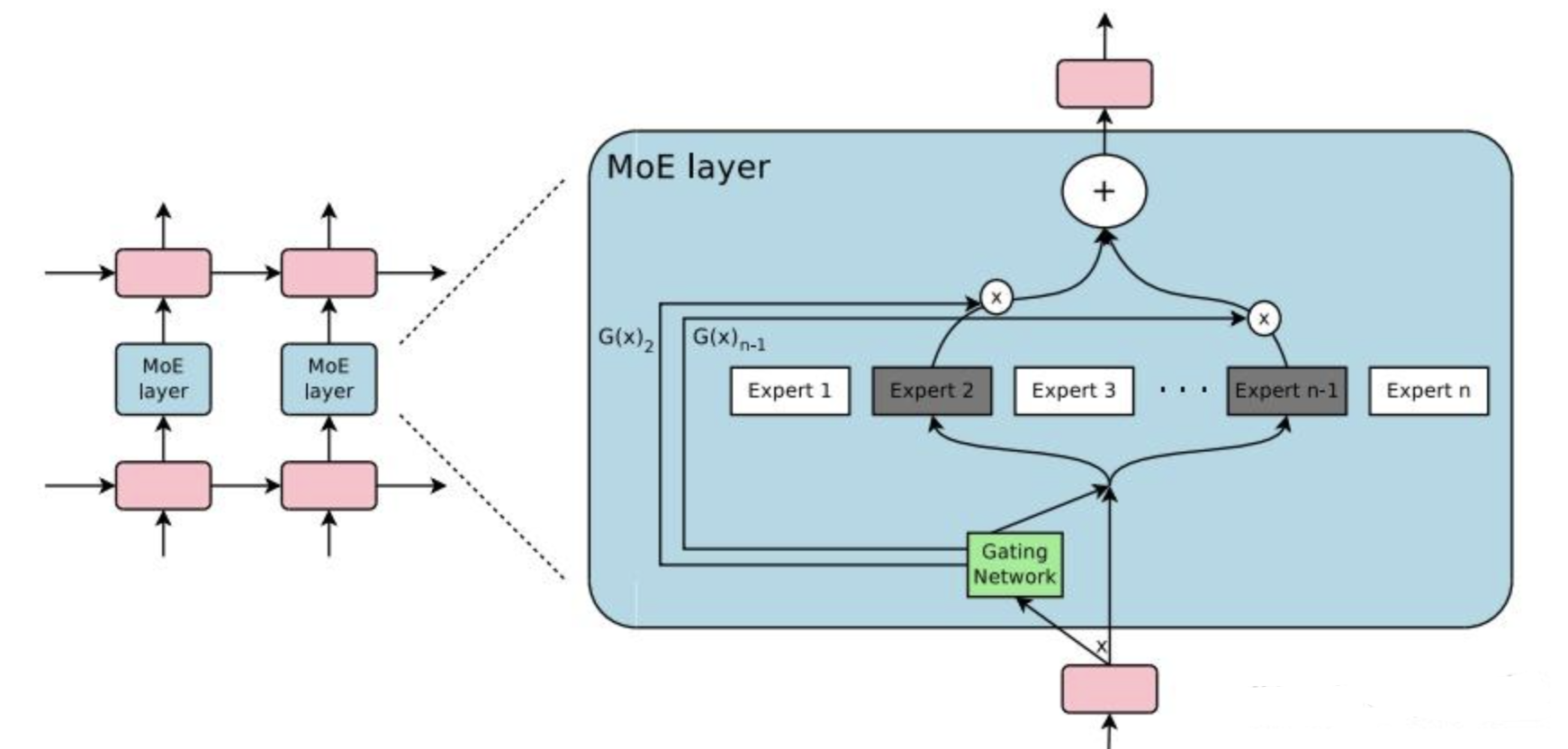
MoE用一组稀疏激活的专家网络替换传统的FFN层:
class MoELayer:
def __init__(self, num_experts, expert_capacity, top_k=2):
self.num_experts = num_experts
self.experts = [FFN() for _ in range(num_experts)]
self.router = Router() # 门控网络
self.top_k = top_k
def forward(self, x):
# 1. 路由器决定每个token去哪些专家
routing_weights = self.router(x)
expert_indices = top_k_indices(routing_weights, self.top_k)
# 2. 将token分发到对应专家
expert_inputs = dispatch_tokens(x, expert_indices)
# 3. 专家计算
expert_outputs = []
for expert_id, inputs in expert_inputs.items():
if inputs is not None:
output = self.experts[expert_id](inputs)
expert_outputs.append(output)
# 4. 组合专家输出
final_output = combine_expert_outputs(expert_outputs, routing_weights)
return final_output
4.2 专家并行实现
专家并行将不同的专家分配到不同GPU:
class ExpertParallel:
def __init__(self, num_experts, num_gpus):
self.num_experts = num_experts
self.num_gpus = num_gpus
self.experts_per_gpu = num_experts // num_gpus
def forward_with_all_to_all(self, tokens, routing_decisions):
# 1. 第一次All-to-All:将token发送到目标专家所在GPU
dispatched_tokens = all_to_all_dispatch(tokens, routing_decisions)
# 2. 本地专家计算
local_outputs = []
for gpu_id in range(self.num_gpus):
expert_range = self.get_expert_range(gpu_id)
for expert_id in expert_range:
tokens_for_expert = dispatched_tokens[expert_id]
output = compute_expert(expert_id, tokens_for_expert)
local_outputs.append(output)
# 3. 第二次All-to-All:将结果返回原GPU
final_outputs = all_to_all_combine(local_outputs)
return final_outputs
4.3 最新进展与优化
从2025年2月Deepseek的发布后,MoE技术有了重大突破:
负载均衡优化:
# 辅助损失函数保证负载均衡
def load_balancing_loss(routing_weights, expert_loads):
# 确保每个专家处理的token数量相近
target_load = 1.0 / num_experts
load_variance = sum((load - target_load)**2 for load in expert_loads)
return alpha * load_variance
动态专家加载:
# 推理时只加载需要的专家
class DynamicExpertLoading:
def __init__(self):
self.cached_experts = {}
self.cache_size = 4 # 只在显存中保留4个专家
def get_expert(self, expert_id):
if expert_id not in self.cached_experts:
# 从CPU或磁盘加载
self.load_expert(expert_id)
# LRU淘汰策略
if len(self.cached_experts) > self.cache_size:
self.evict_least_used()
return self.cached_experts[expert_id]
DeepSeek-V3、Qwen、GPT5、Mixtral等模型的成功证明了MoE是通向万亿参数的必经之路。
五、混合并行策略与最佳实践
实际训练大模型时,我们需要组合多种并行策略。
5.1 典型的4D并行配置
根据我的经验和业界实践,一个典型的配置是这样的:
class HybridParallelConfig:
def __init__(self, total_gpus=512):
# 假设有64个节点,每个节点8张GPU
self.num_nodes = 64
self.gpus_per_node = 8
# 并行度配置
self.tensor_parallel_size = 8 # 节点内TP
self.pipeline_parallel_size = 8 # 跨节点PP
self.data_parallel_size = 8 # 剩余做DP
# 对于MoE模型,可能还需要EP
self.expert_parallel_size = 4
# 验证配置
assert (self.tensor_parallel_size *
self.pipeline_parallel_size *
self.data_parallel_size == total_gpus)
5.2 性能优化建议
基于实际项目经验,我总结了这些优化建议:
通信优化:
# 1. 重叠通信与计算
def overlap_communication():
# 在计算当前层时,预先发起下一层的通信
future_comm = async_send(next_layer_data)
current_output = compute_current_layer()
wait(future_comm)
return current_output
# 2. 梯度累积减少通信频率
def gradient_accumulation(accumulation_steps=4):
for step in range(accumulation_steps):
loss = forward_backward(batch[step])
accumulate_gradients()
# 只在累积完成后同步一次
all_reduce_gradients()
optimizer.step()
内存优化:
# 1. 激活重计算(Activation Checkpointing)
def checkpoint_forward(module, inputs):
# 前向传播时不保存中间激活
with no_grad():
outputs = module(inputs)
# 反向传播时重新计算
def custom_backward():
with enable_grad():
return module(inputs)
return outputs, custom_backward
# 2. CPU卸载(Offloading)
def offload_optimizer_states():
# 将优化器状态移到CPU
for param_group in optimizer.param_groups:
for param in param_group['params']:
param.grad.cpu()
# 更新时再移回GPU
def update_step():
move_to_gpu(optimizer_states)
optimizer.step()
move_to_cpu(optimizer_states)
5.3 实战案例分析
分享一个实际的70B模型训练配置:
# 硬件配置:8个节点,每节点8张A100 80GB
class Training70BModel:
def __init__(self):
self.model_size = 70_000_000_000 # 70B参数
self.hidden_size = 8192
self.num_layers = 80
self.sequence_length = 4096
# 并行配置
self.parallel_config = {
'tensor_parallel': 4, # 单节点内4张卡做TP
'pipeline_parallel': 4, # 4个节点做PP
'data_parallel': 4, # 剩余做DP
'sequence_parallel': True, # 开启SP降低激活内存
'zero_stage': 2 # 使用ZeRO-2
}
def calculate_memory_usage(self):
# 模型参数内存(FP16)
param_memory = self.model_size * 2 / (1024**3) # GB
# 考虑并行后的内存
param_per_gpu = param_memory / self.parallel_config['tensor_parallel']
param_per_gpu /= self.parallel_config['pipeline_parallel']
# 激活值内存(简化计算)
activation_memory = (self.sequence_length * self.hidden_size *
self.batch_size * 4) / (1024**3)
if self.parallel_config['sequence_parallel']:
activation_memory /= self.parallel_config['tensor_parallel']
total_memory = param_per_gpu + activation_memory
print(f"每张GPU内存需求: {total_memory:.2f} GB")
return total_memory < 80 # A100有80GB显存
六、调试技巧
在调研学习训练大模型过程中,调研到几个典型的案例:
6.1 通信瓶颈诊断
# 诊断工具
class CommunicationProfiler:
def __init__(self):
self.comm_times = {}
def profile_all_reduce(self, data_size):
start = time.time()
all_reduce(dummy_data(data_size))
elapsed = time.time() - start
bandwidth = data_size / elapsed / (1024**3) # GB/s
print(f"All-Reduce带宽: {bandwidth:.2f} GB/s")
if bandwidth < 10: # 低于10GB/s可能有问题
print("警告:通信带宽过低,检查网络配置")
6.2 负载不均衡问题
# 监控各GPU利用率
def monitor_gpu_utilization():
utilizations = []
for gpu_id in range(num_gpus):
util = get_gpu_utilization(gpu_id)
utilizations.append(util)
avg_util = sum(utilizations) / len(utilizations)
variance = sum((u - avg_util)**2 for u in utilizations)
if variance > 0.1: # 方差过大说明负载不均
print("检测到负载不均衡")
print(f"GPU利用率: {utilizations}")
# 可能需要调整PP的层划分
6.3 常见错误与解决方案
# 1. OOM错误处理
def handle_oom():
try:
train_step()
except RuntimeError as e:
if "out of memory" in str(e):
print("内存不足,尝试以下方案:")
print("1. 减小batch size")
print("2. 开启gradient checkpointing")
print("3. 增加tensor parallel度")
print("4. 使用更高level的ZeRO")
# 2. 死锁检测
def detect_deadlock():
timeout = 300 # 5分钟超时
with timeout_context(timeout):
try:
collective_operation()
except TimeoutError:
print("可能发生死锁,检查:")
print("1. 所有rank是否执行相同的collective操作")
print("2. 操作顺序是否一致")
七、未来展望
站在2025年下半年开始的这个时间点,我觉得分布式并行技术还会有这些发展方向:
自动并行化:框架会越来越智能,自动选择最优的并行策略组合。现在已经有一些自动并行的工具,但还不够成熟。
硬件协同设计:新的硬件架构会专门为大模型并行训练优化。比如更高带宽的互联、专门的通信加速器等。
稀疏化技术:MoE只是开始,未来会有更多稀疏化技术出现,让模型参数继续增长的同时保持计算效率。
推理优化:现在大部分并行技术都是为训练设计的,推理阶段的并行优化还有很大空间。
总结
写了这么多,其实核心就是:没有固定的方式,需要根据具体情况选择和组合不同的并行策略。
对于刚接触大模型训练的同学,我的建议是:
- 先从数据并行开始,这是最简单的
- 模型放不下时考虑张量并行或流水线并行
- 长序列场景使用序列并行或上下文并行
- 超大规模模型考虑MoE架构和专家并行
记住一点:优化是个系统工程,需要综合考虑模型架构、硬件资源、通信带宽等多个因素。多实践、多测试、多调优,慢慢就会找到感觉了。
希望这篇文章对大家有帮助。如果有什么问题,欢迎在评论区交流讨论!


















 1681
1681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









