







 本文介绍了单调栈在编程中的应用,主要用于快速找到数组元素右侧或左侧第一个较大或较小的元素,通过空间换时间的方式优化时间复杂度。文章详细解释了单调栈的工作原理,注意事项,以及如何在LeetCode问题中使用单调栈解决实例。
本文介绍了单调栈在编程中的应用,主要用于快速找到数组元素右侧或左侧第一个较大或较小的元素,通过空间换时间的方式优化时间复杂度。文章详细解释了单调栈的工作原理,注意事项,以及如何在LeetCode问题中使用单调栈解决实例。
单调栈的介绍
用途:主要求当前元素左面或者右面第一个比当前元素大或小的元素。
时间复杂度为O(n)(求当前数组所有元素)如果是暴力就是n^2
本质是空间换时间,因为在遍历的过程中需要用一个栈来记录右边第一个比当前元素高的元素,优点是整个数组只需要遍历一次。
更直白来说,就是用一个栈来记录我们遍历过的元素,因为我们遍历数组的时候,我们不知道之前都遍历了哪些元素,以至于遍历一个元素找不到是不是之前遍历过一个更小的,所以我们需要用一个容器(这里用单调栈)来记录我们遍历过的元素。
使用注意事项
单调栈里存放的元素
单调栈里只需要* 存放元素的下标i *就可以了,如果需要使用对应的元素,直接T[i]就可以获取。
单调栈里元素是递增还是递减(这里指栈头到栈底的顺序)
如果求一个元素右边第一个更大元素,单调栈就是递增的,如果求一个元素右边第一个更小元素,单调栈就是递减的
应用
求右边元素(顺序遍历)
右侧第一个更大 单调第增(从栈顶到栈底)
右侧第一个更小 单调递减
求左边元素(逆序遍历)
其实通过逆序的遍历,就将求左边的元素 转化成 求右边的元素 这样求左侧第一个大就变成了求右侧第一个大
左侧第一个更大 单调递增
左侧第一个更小 单调递减
使用单调栈主要有三个判断条件。
当前遍历的元素T[i]小于栈顶元素T[st.top()]的情况
当前遍历的元素T[i]等于栈顶元素T[st.top()]的情况
当前遍历的元素T[i]大于栈顶元素T[st.top()]的情况
很多简洁的代码将小于和等于的情况合并了。
板子和理解
求右边第一个比自己大的数,这里是leetcode的风格,封装进函数了
大致的思路,将当前的元素与栈顶的元素作比较,如果前者大于后者,那么栈顶的元素找到了右边第一个比自己大的数,所以就要出栈,栈里面可能还有之前遍历数组只进栈没出栈的元素(这也就意味着,他们没有找到那个比自己大的数)所以当前元素要和栈内所有元素都比较一遍,能出栈的就出栈了。都比较完,当前元素进栈。其实栈里面存放的就是没有找到所求的元素的下标。当然如果当前元素小于等于栈顶的元素直接进栈。(所以说这个栈从栈顶到栈底是递增的,毕竟要是栈底上面有比栈底元素大的数,栈底的元素早出栈了)。
至于为啥是第一个,这也很好理解,因为你的元素在遇到第一个大于自己的数的时候就已经出栈了,也就不再参与与后面数的比较。这个元素的结果就定了。很妙的小结构。
// 版本一
class Solution {
public:
vector<int> dailyTemperatures(vector<int>& T) {
// 递增栈
stack<int> st;
vector<int> result(T.size(), 0);
st.push(0);
for (int i = 1; i < T.size(); i++) {
if (T[i] < T[st.top()]) { // 情况一
st.push(i);
} else if (T[i] == T[st.top()]) { // 情况二
st.push(i);
} else {
while (!st.empty() && T[i] > T[st.top()]) { // 情况三
result[st.top()] = i - st.top();
st.pop();
}
st.push(i);
}
}
return result;
}
};
// 版本二
class Solution {
public:
vector<int> dailyTemperatures(vector<int>& T) {
stack<int> st; // 递增栈
vector<int> result(T.size(), 0);
for (int i = 0; i < T.size(); i++) {
while (!st.empty() && T[i] > T[st.top()]) { // 注意栈不能为空
result[st.top()] = i - st.top();
st.pop();
}
st.push(i);
}
return result;
}
};
例题
503.下一个更大元素II
这道题比起纯纯的板子题,多了一个细微的差别,循环数组。
我把题放在例题里,也是想提醒我自己,环状数组的处理方式。
数组成环可以
开两倍的空间,例如将 1234 存成12341234
下标进行去模,mod数组大小
其实后者原理和前者一样,只不过处理起来更加方便和优美
class Solution {
public:
vector<int> nextGreaterElements(vector<int>& nums) {
vector<int>result(nums.size(),-1);
//存的是下标
stack <int>st;
for (int i=0;i<nums.size()*2;i++)
{
int ii=i%nums.size();
while(!st.empty()&&nums[ii]>nums[st.top()])
{
result[st.top()]=nums[ii];
st.pop();
}
st.push(ii);
}
return result;
}
};
其实这道题还有一个小细节,就是reasult会不会被覆盖的问题。(这个问题指的是当我的ii重复的时候,原先result中正确的数据会不会被脏数据覆盖掉)
举个例子,假如这个数组是1 2 3 4 3 ,那么通过这个取模的操作,我们实际遍历的数是这样的 1 2 3 4 3 我是可爱的分界线 1 2 3 4 3.
当i还小于nums.size()的时候(为了方便叙述 称为 第一轮)
result数组里面为 2 3 4 -1 -1
第二轮之后为
2 3 4 -1 4
显然的原先正确数据不会被更改,因为你后面遍历的数和前面的是一样的,那么即使ii因为取模而重复了,但是他所获得的结果和前面是一样的。
举个例子 当你遍历到第一个1的时候答案是2,当你遍历到第二个1时结果还是后面的2.也就是说在第一轮有答案的元素,到第二轮时答案不会变。当然第一轮结束 4 3还在栈里面。
例题
鲁迅曾说过 只做板子题是不会进步的!**
聪明的你快来思考这道题吧!
42. 接雨水
这道题就是求凹槽的面积。我们先来想最简单的凹槽。
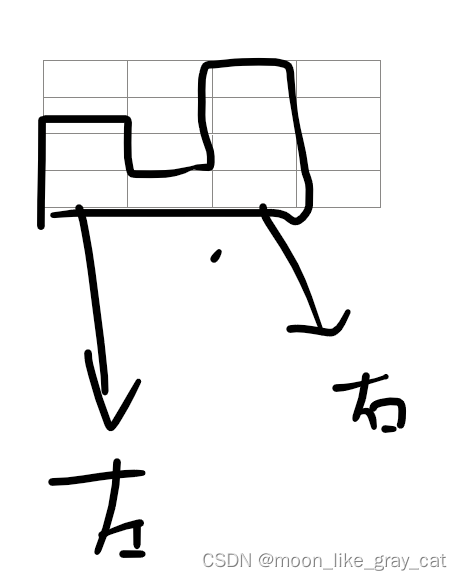
一个凹槽左边是高,右边是高的,这样不就是中间这个元素的左边的第一个大的数,右边的第一个大的数。这不正是单调栈的业务范围吗!想到这,也许我们可以用单调栈来尝试一下。
右边第一个大的元素不必多说了,上文就是。左边第一个大的数其实就是这个元素在栈中的下一个元素(靠近栈底)。画张图。
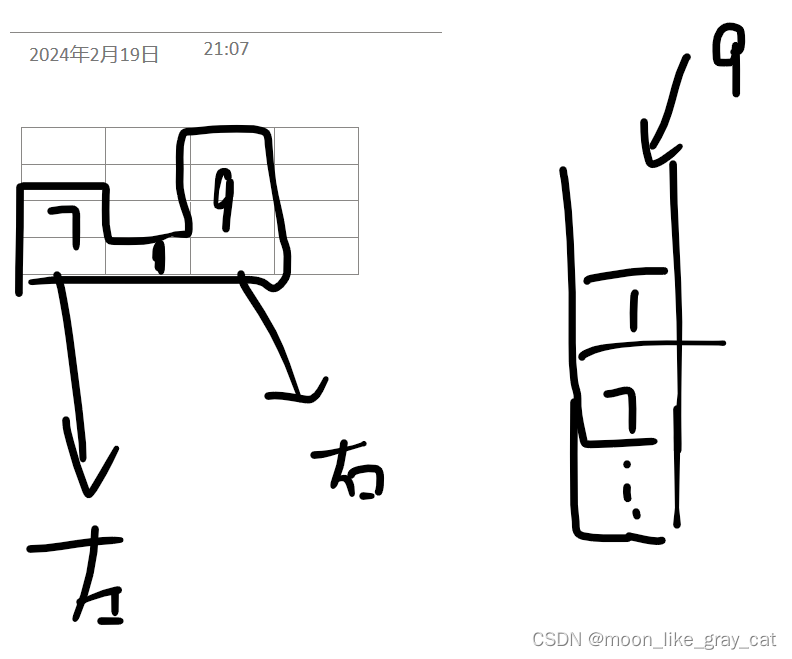
在图中可以形象的看出来,也可以抽象的思考一下。不赘述了。
这个凹槽的面积也是好求的。
h=min(左边的高,右边的高)-中间的高
宽度是1。
那么能不能从这个最简单的凹槽推广到复杂一点的凹槽。
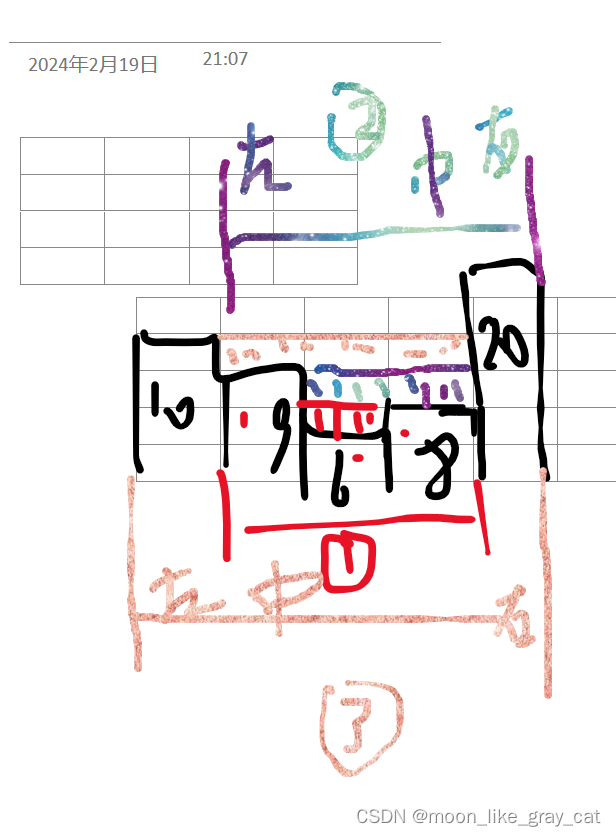
上图中我给了一组数据,序号代表了你遍历这个数组的时候这个凹槽是第几个凹槽。
当你找完了一个凹槽,将这个凹槽 中 (图中 左中右的中)的元素pop,不知道怎么描述。想说的话都在图里了。我们这里是一层一层的计算的。
以上证明了可行性。
代码
class Solution {
public:
int trap(vector<int>& height) {
stack<int>st;
long long ans=0;
for (int i=0;i<height.size();i++)
{
while (!st.empty()&&height[i]>height[st.top()])
{
int mid=st.top();
st.pop();
if (!st.empty())
{int h=min(height[st.top()],height[i])-height[mid];
int w=i-st.top()-1;
ans+=h*w;
}
}
st.push(i);
}
return ans;
}
};
参考了B站上代码随想录的视频

















 180
180

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









