







 本文深入探讨Floyd算法解决多源最短路径问题的核心原理。通过动态规划思想,利用递推公式逐步更新各点间的最短路径,确保算法的正确性和高效性。
本文深入探讨Floyd算法解决多源最短路径问题的核心原理。通过动态规划思想,利用递推公式逐步更新各点间的最短路径,确保算法的正确性和高效性。
转自:https://blog.youkuaiyun.com/ljhandlwt/article/details/52096932
图论里一个很重要的问题是最短路径问题.
这个问题,在离散数学课上会考,数据结构与算法课上会考,图论课上会考,计算机网络里会考…
解决最短路径问题有几个出名的算法:
1.dijkstra算法,最经典的单源最短路径算法
2.bellman-ford算法,允许负权边的单源最短路径算法
3.spfa,其实是bellman-ford+队列优化,其实和bfs的关系更密一点
4.floyd算法,经典的多源最短路径算法
今天我们讨论的是floyd算法,它用于解决多源最短路径问题,算法时间复杂度是O(n3).
floyd算法为什么经典,因为它只有5行(或者4行)!!!
是的,没有特意的写成一行的代码.

这个算法短的离谱,以致于我们通常直接将它背了下来当模板使用,而不像学dijkstra那时候一步步理解它是如何贪心的.
那么,为什么floyd算法是这个样子的呢?或者说,为什么这样就能求出所有点到所有点的最短路径?
谈起floyd算法,一般我们会说这是一个动态规划算法.(怪不得如此优美)
为什么是个动态规划算法?因为它有递推公式:d[i][j]=min(d[i][j],d[i][k]+d[k][j])
还有一点就是三重循环,k要写外面,里面的i,j是对称的,随便嵌套没所谓.
这大概就是我们大部分人对floyd算法的了解.
那么,我们其实没有解决核心问题,为什么这样就能解决问题,为什么是这个递推公式,是这个嵌套顺序?
这一切都不像学长所说的那么显然…
事实上,如果你明白了bellman-ford的正确性,你就会明白为什么floyd是可行的了.
在这里我们不讨论floyd以外的算法,我们正面刚floyd.
floyd的最关键的地方是它的递推公式,它的递推公式写得抽象一点就是下图:

简单来说,这个i到j的最短路径,我们可以找一个中间点k,然后变成子问题,i到k的最短路径和k到j的最短路径.
也就是说,我们可以枚举中间点k,找到最小的d[i][k]+d[k][j],作为d[i][j]的最小值.
这好像很合理啊,假如所有d[i][k]和d[k][j]都取了最小值的话,这个dp很dp.
但是,d[i][k]和d[k][j]一开始都不一定取了最小值的啊!它们和d[i][j]一样,会不断变小.
那么,会不会存在这种情况,d[i][j]取最小值时的k是某个x.
而在最外循环k=x的时候,d[i][x]或者d[x][j]并没有取到最小值,但这个时候会执行d[i][j]=min(d[i][j],d[i][x]+d[x][j]),造成了d[i][j]并不能取到真正的最小值.
答案当然是,并不会出现这种情况.我们今天的重点就是来讨论为什么不会出现这种情况.
我们需要证明一个很致命的结论:
假设i和j之间的最短路径上的结点集里(不包含i,j),编号最大的一个是x.那么在外循环k=x时,d[i][j]肯定得到了最小值.
怎么证明,可以用强归纳法.
设i到x中间编号最大的是x1,x到j中间编号最大的是x2.
由于x是i到j中间编号最大的,那么显然x1<x,x2<x.
根据结论,k=x1的时候d[i][x]已经取得最小值,k=x2的时候d[x][j]已经取得最小值.
那么就是k=x的时候,d[i][x]和d[x][j]肯定都已经取得了最小值.
因此k=x的时候,执行d[i][j]=min(d[i][j],d[i][x]+d[x][j])肯定会取得d[i][j]的最小值.
证毕.
用强归纳法证明固然优美,但是显得有点抽象,并且我们忽略了一些初始情况和特殊情况(比如i和j之间没有结点).
现在,我们举一个实际的例子,去说明它的正确性.
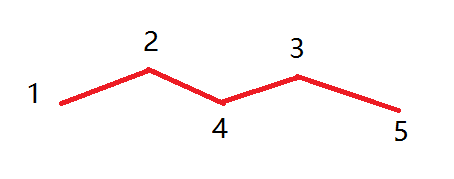
上图是1到5的最短路径,这意味着d[1][2],d[2][4],d[4][3],d[3][5]在一开始就是最小值了.
这在某种程度上证明了我们那个结论,因为中间无结点,相当于最大编号是-∞,就是k=-∞,即一开始的时候就取了最小值了.
首先第一轮k=1,不难知道,1到5这些点之间原本没能取得最短距离的,更新后也没能保证取得最短距离.
第二轮k=2,我们发现d[1][4]肯定取得了最小值,因为会执行d[1][4]=min(d[1][4],d[1][2]+d[2][4]),而d[1][2]和d[2][4]已经是最小值.
第三轮k=3,我们发现d[4][5]肯定取得了最小值.
第四轮k=4最关键,我们发现d[2][3],d[1][3],d[2][5],d[1][5]都肯定取得了最小值.
d[2][3]=d[2][4]+d[4][3]
d[1][3]=d[1][4]+d[4][3]
d[2][5]=d[2][4]+d[4][5]
d[1][5]=d[1][4]+d[4][5]
我们可以看到,等号右边的几个值,都在k=4之前取得了最小值.
这意味着d[1][3]的更新就是最小的了,不会存在d[1][4]未取最小值导致d[1][3]未取得最小的情况发生.
并且,我们看到1到4之间的最大编号是2,而d[1][4]在k=2时肯定取得了最小值,后面的也是同理.
这在感性上证明了我们那个致命的结论.
有了这个致命的结论,根据一开始的推理,其实已经可以显然地理解为什么floyd是正确的了.
事实上,假如在执行d[i][j]=min(d[i][j],d[i][k]+d[k][j])前,对于所有的k,d[i][k]和d[k][j]都是最小值,那么上面例子里d[1][5]之间的k可以选择2,3,4.
但是,我们没法做到对于所有的k,执行那个语句前d[i][k]和d[k][j]都是最小值.
但是,我们保证了能存在一个k=x,在执行那个语句前d[i][x]和d[x][j]都是最小值.
而这个x,是i和j最短路径的点集里最大的编号.
这也说明了为什么k一定要是在最外层的原因,
因为假如k在最里层,那么d[i][j]=min(d[i][j],d[i][k]+d[k][j])是一次性执行完.
那么我们就要保证,在这时候,至少存在一个k=x,使得d[i][x]和d[x][j]都是取得了最小值.
然而在这种情况下我们并不能保证,但如果k在最外层就可以保证了.
总结:
首先,它是运用了动态规划的思想来进行问题求解。动态规划解题的关键在于找好子结构。Floyd构造的结构非常巧妙:找i和j之间通过编号不超过k(k从1到n)的节点的最短路径(一定要注意,这里是当前最短路径,当k=n时达到最终最短路径)。为了便于说明,我们可以弄一个三维数组f[k][i][j]表示i和j之间可以通过编号不超过k的节点的“最短路径”。对于k-1到k,只有两种可能,经过编号为k的点,要么不能找到一条从i到j的更短路,此时有f[k][i][j] = f[k-1][i][j] ;要么能找到,那这个最短路径一定是d[i][k]+d[k][j],那么就用这个较小的距离去更新d[i][j]。综合以上两种情况,f[k][i][j] = min(f[k-1][i][j] , f[k-1][i][k]+f[k-1][k][j])。

















 1257
1257

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









