







使用的书是 统计学习方法 +机器学习实战;
参考博客 http://blog.youkuaiyun.com/c406495762,感谢;
自己写一下,方便以后理解; 使用决策树做预测需要以下过程:
收集数据:可以使用任何方法。比如想构建一个相亲系统,我们可以从媒婆那里,或者通过参访相亲对象获取数据。根据他们考虑的因素和最终的选择结果,就可以得到一些供我们利用的数据了。
准备数据:收集完的数据,我们要进行整理,将这些所有收集的信息按照一定规则整理出来,并排版,方便我们进行后续处理。
分析数据:可以使用任何方法,决策树构造完成之后,我们可以检查决策树图形是否符合预期。
训练算法:这个过程也就是构造决策树,同样也可以说是决策树学习,就是构造一个决策树的数据结构。
测试算法:使用经验树计算错误率。当错误率达到了可接收范围,这个决策树就可以投放使用了。
使用算法:此步骤可以使用适用于任何监督学习算法,而使用决策树可以更好地理解数据的内在含义。
在决策树搭建的过程中,我们要选择节点,那么选择节点的依据是什么?
介绍两个概念 信息熵和信息熵增益(选择的依据)。
简单理解 信息熵就是 代表信息量的多少、 不确定性的大小、事物的简单复杂;
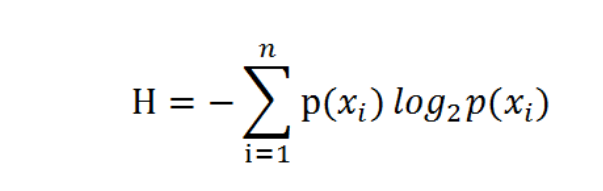
信息熵的计算对象 通常是某个特征(1列)或者分类对象(1列);通常是一个已知数。
那么信息熵增益又是什么?
简单说 信息熵增益既然是衡量节点的东西 ,那么它必然是 特征对最后的分类的影响的体现;
具体就是 特征对分类的信息熵约束能力的大小。(信息熵增益大,代表特征对分类的信息熵约束能力的大,代表
特征会使得原来分类的信息熵变得非常小,不确定性变小)。
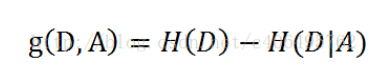
信息熵增益公式


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









