



一种用于无碰撞自动驾驶的预测感知模型与控制策略
摘要
自动驾驶中的一个关键问题是决策逻辑,特别是涉及自动驾驶车辆与人工驾驶车辆共存的混合交通场景。基于此,我们提出一种通过博弈论对自动驾驶车辆与人工驾驶(或其他自动驾驶)车辆之间的交互进行建模的方法,并通过对一个能够描述变道过程运动学特性的简单混合动力系统的解集进行可达性分析,评估潜在碰撞路径的时间演化。进一步,我们采用基于模型预测控制的控制策略,为目标车辆生成安全可靠的运动轨迹。该模型随后在多种仿真场景中,针对可编程的安全保证参数进行了评估。需要强调的是,所提出的方案具有主动式特征,因其考虑了数秒时间范围内的未来状态,并假设局部交通参与者具有一定的行为一致性。因此,该方法必须结合适当的被动式碰撞缓解机制,以应对由不可预测的突发行为所引起的即时威胁。尽管如此,本文研究的场景表现出直观合理的驾驶行为,符合常规驾驶习惯,展示了该方法在自动驾驶策略中应用的良好前景。
索引词
自动驾驶汽车,自然驾驶,碰撞避免,变道操作,模型预测控制。
一、引言
驾驶模式的研究和驾驶员模型的设计在过去三十年中一直受到交通研究人员的关注[1]–[6]。特别是,许多研究聚焦于驾驶员在换道和汇入操作中的决策逻辑[1],[2]。这些工作的重点至少部分在于复现人类驾驶行为的规则,以实现微观交通仿真或增强自动驾驶汽车的实现,这在汽车与交通研究中是一个日益重要的课题[9]。
在这方面,加州PATH项目(先进交通技术合作伙伴)提供了早期的自动驾驶高速公路集成方法版本[10],[11]。美国国防高级研究计划局(Defense Advanced Research Projects Agency)城市挑战赛也展示了自动驾驶的可能性及其面临的挑战[12],[13],而近年来,谷歌、特斯拉等公司在各种场景下展示了自动驾驶技术[14],[15]。相应法规已在多个州颁布,使自动驾驶汽车合法化[16],[17],并且美国交通部正在考虑更广泛的实施。
考虑到这一点,我们可能会在不久的将来看到道路上同时存在自动驾驶汽车和人工操作车辆的情况。在这方面,正如Campbell et al. [13]所提出的,自动驾驶面临的一个挑战是如何像经验丰富的驾驶员一样有效地预测其他车辆的行为,因为人类驾驶员能够区分危险驾驶者和合理驾驶者,并将这些信息用于自身的决策过程中。换句话说,自动驾驶汽车必须能够在各种驾驶情况下应对合作性与非合作性的驾驶行为。这意味着有必要建立一个能够捕捉驾驶员全部行为特征的预测模型,以便在混合交通中制定安全且有效的自动化驾驶策略。
A. 自动驾驶碰撞分析
已有多种方法用于无碰撞轨迹规划与控制[18],[19],如下文引用的部分参考文献所述。特别是,Swaroop 和 Yoon [20]在车辆编队概念下,针对障碍物存在的情况开发了紧急变道操作。Jula et al. [21]对车道变换操作进行了运动学分析,并提出了避免碰撞的最小纵向间距。Kanaris et al. [22]提出了自动化高速公路系统中车道变换和并道的最小安全间距标准。此外,许多研究人员还基于弹性带理论[23],[24]开发了无碰撞路径规划方案。
同时,已经提出了多种概率性/确定性碰撞检测方案,以计算未来的碰撞可能性或避免碰撞。Broadhurst et al.[25]使用蒙特卡洛路径规划算法为竞争车辆的未来运动生成概率分布,并评估碰撞可能性。可达集计算最初应用于无人机[26],随后促使Althoff et al. [27]提出随机可达集,以评估自动驾驶汽车规划路径中的碰撞情况。
B. 自动驾驶车辆的换道操作
车道变换通常分为强制性车道变换(MLC)和自主性车道变换(DLC)。尽管两种情况都需要仔细规划,但安全因素在MLC场景中通常起着更重要的作用。特别地,在[28] Yoo and Langari中引入了一种基于博弈论的方法来研究高速公路汇入问题,并通过斯塔克尔伯格博弈理论预测竞争车辆的行为。在[29]中,通过临界间隙接受分析区分MLC和DLC。在[30] Roncoli 等提出了一种车辆自动化与通信系统,用于控制多车系统中车辆的纵向和横向运动,以实现最大交通效率。在[31]中,提出了一种集成换道方案,该方案考虑了特定车辆到出口匝道的当前距离。在[32] Kesting 等提出了一种与多种跟驰模型(包括标准间隙接受模型)兼容的换道模型。
同时,许多研究人员提出了用于在特定情况下精确控制车辆的控制器。例如,尼尔森和斯约伯格[33]将交通视为混合逻辑动态系统,并提出了一种控制器来协调纵向和自主换道决策。同样,希尔德巴赫和博雷利[34]通过考虑周围车辆的行为,提出了一种换道策略。许多其他作者也提出了相关策略,对这一领域产生了重要影响[18],[19]。
尽管之前的研究人员假设了非合作场景,但也有研究者在合作框架内考虑了强制换道问题。特别是Cao et al. 和Ran et al.假设利用车对车(V2V)通信来协同执行强制变道。其他研究者,包括van Arem et al. [37]和Xu et al. [38],提出了结合车对车(V2V)技术的协作式自适应巡航控制,以实现协同高速公路合流。
本工作的重点
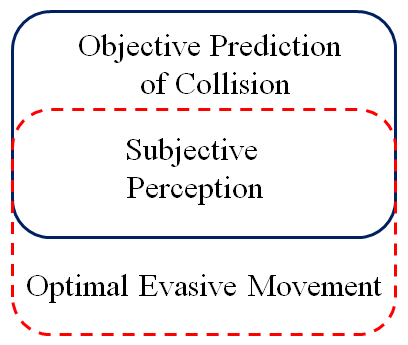
驾驶员对驾驶安全的个体感知可以通过客观风险和主观风险估计的结合来解释[39]。客观风险代表了碰撞的概率。主观风险则反映了驾驶员对此概率的认知和感知。后者可能与驾驶员固有的激进性水平、紧迫感或在交通中移动时对敏捷性的追求有关。因此,主观风险估计并不总是与客观碰撞概率相匹配。从这个意义上说,驾驶与其他驾驶员表现出类人行为的方式类似(有时是非理性但可量化的)行为[40]–[43],因此构建一个分层的碰撞避免模型以涵盖驾驶行为的多样性非常重要(特别是竞争车辆的激进性,或目标车辆为实现自身驾驶目标所需具备的敏捷性)。
鉴于此,本研究重点关注两个相互关联的问题:i) 评估由于竞争车辆可能行为谱所导致碰撞的客观指标,以及 ii) 使用主观指标来评估感知威胁,并确保后续决策考虑到目标车辆所需的敏捷性。通过结合可达集分析(用于客观碰撞评估)和基于敏捷性的潜在碰撞区域缩放(即将定义),以确保目标车辆表现出适当的行为。一旦评估出碰撞的可能性,就有必要生成一条避撞轨迹。为此,设计了一种模型预测控制(MPC)策略,以避免在特定时间范围内可能出现的任何碰撞。
所提出的方案允许调节目标车辆的敏捷性参数(或其安全保证水平),以应对不同的交通状况,并在客观与主观风险之间实现平衡,如图1所示。尽管这看似令人困惑,但这种方法实际上可能提高安全性。例如,一名极为谨慎的驾驶员可能不会利用换道机会,从而不仅增加了交通负荷,还可能因不作为而无意中引发碰撞。至少,此类驾驶员需要与交通环境(或当地驾驶文化)保持协调。请注意,我们在此次的意图并非规定目标车辆必须具备某种特定的敏捷性水平;而是旨在开发一种具有可调敏捷性参数(或安全保证)的灵活策略,以帮助开发适用于多种交通环境(包括高速公路、干线道路,甚至可能城市交通)的自动驾驶方案。
本文的结构如下:第二节描述了问题的系统配置。第三节定义了一种用于换道模型的混合模型以及用于评估碰撞的人类预测感知模型。第四节提出了避碰控制策略,第五节给出了相关仿真结果。第六节总结了本研究工作并对全文进行了结论。
II. 系统配置
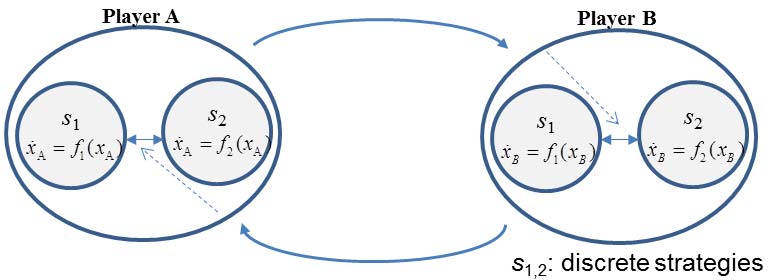
驾驶情况由车辆的离散决策及其相应的连续动力学共同决定。为了说明我们的基本系统配置,我们考虑如图2所示的两个作为智能体(或参与者)的车辆,每个智能体具有两种策略。每个智能体基于自身的离散决策模型,并利用另一智能体行为的信息做出决策。在这些决策过程中,连续动力学(其状态为xi,i=A,B)根据智能体所选择的离散策略(si,i= 1,2)进行演化。
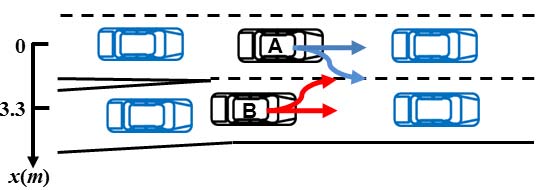
为了说明这一点,我们考虑一种情况:两辆车辆分别从汇入车道和主路竞争并道,如图3所示。
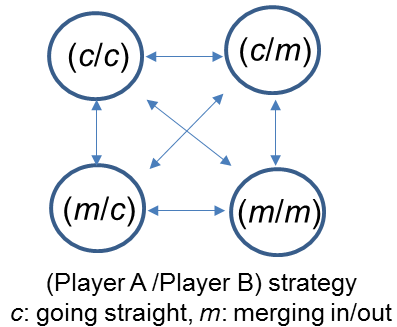
给定的车辆有两种策略:直行于current lane(c)和 merging in/out(m)。我们将车辆离散strategies的组合定义为:
$$ \mu={(c, c),(c, m),(m, c),(m, m)} $$
如图4所示。请注意,这种冲突可能发生在正常驾驶中相互变换车道的两辆车辆之间(discretionary变道),也可能发生在汇入情况下(mandatory变道)。
理想情况下,始终会确保安全间距。然而,通常当两车相互竞争时,目标车辆无法完全准确判断对方车辆的行为。正如预期的那样,这两辆车辆在汇入时刻和变道操作本身方面都存在不确定性。从目标车辆的角度来看,我们对此进行建模。
通过一种激进性度量[44]来表征竞争车辆行为的不确定性(下文将详细阐述),并考虑该度量的一系列可能取值。我们进一步利用混合策略纳什博弈和可达集分析来预测竞争车辆可能的行为,如下所述。
III. 变道的混合模型
许多研究集中于基于车辆动力学和驾驶员转向操作[20],[45]以及静态轨迹方程[21],[46],[47]的车辆运动表示。为了在此背景下构建风险估计的数学模型,我们首先在与目标车辆相连的坐标系中定义交互车辆的相对动力学(实际上是运动学)。接着,我们用一对可切换的微分方程来定义变道轨迹,该方程包含两个子模式:接近和稳定。接近模式对应范温瑟姆研究[48]中的第一阶段和第二阶段的结合,使目标车辆从当前车道移动到相邻车道。稳定模式则是相反方向的描述,使车辆能够保持在相邻车道内行驶。
A. 简单的换道混合模型
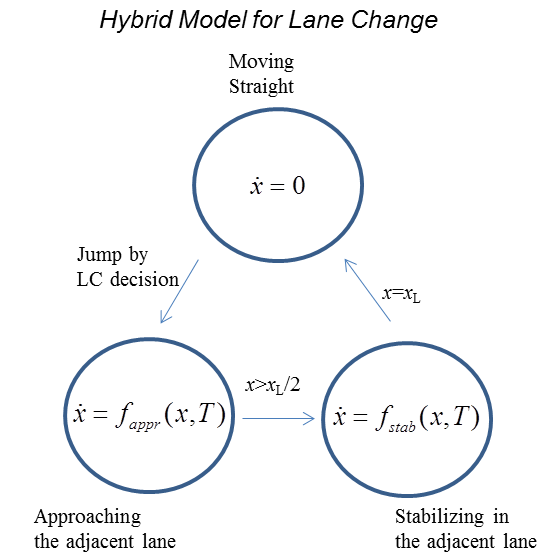
鉴于此,我们提出一种用于变道轨迹的简单混合模型,以符合人类在变道操作中的转向特性,再现给定车辆横向位置的时间历程[49],[50]。该混合模型及相应的连续横向动力学如图5所示,并在下文进一步阐述。
在图中,T表示变道轨迹的周期,xL表示车道宽度。为简便起见,我们假设对于同一车辆,T在两个离散状态中是相同的。关于接近和稳态的详细连续动力学(实际上是运动学轨迹)如公式(1.2)和(1.3)所示,其中K、a和b是适当选择的模型参数。(在本研究中,这些值分别选为7.0528,0.05和3.35。)
$$ f_{appr}(x, T)= \frac{K}{T}(x+ a) $$
$$ f_{stab}(x, T)= -\frac{K}{T}(x - b) $$
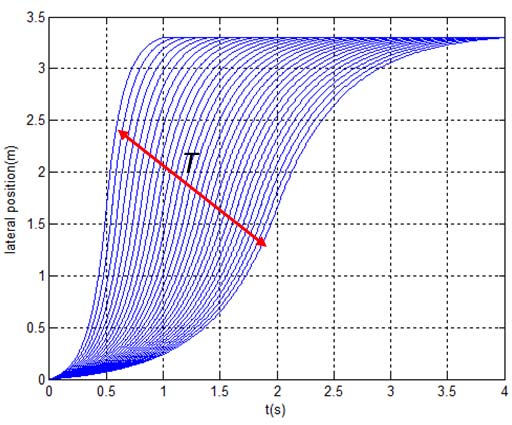
由于每位驾驶员的车道变换完成时间不同,我们利用该轨迹的持续时间来反映驾驶员的激进性或敏捷性;激进(或敏捷)的驾驶员完成时间更短。图6展示了在1s到4s范围内完成的车道变换。尽管纵向运动实际上会受到横向速度的影响,但此处我们假设纵向速度与横向速度无关,因为其影响相对较小。然而,我们意识到这是本研究的一个局限性,并将在该方法的持续演进过程中加以解决。此外需注意,参数T依赖于反映驾驶员在特定交通环境中的行为模式的激进性度量。
B. 横向运动模式的定义
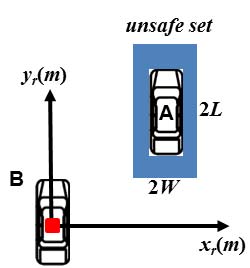
接下来,我们定义一个不安全集(碰撞区域),用于描述两辆车(A 和 B)相互竞争并道或变道时的情形(图 7)。为简化问题,我们不考虑车辆旋转的影响。因此,在假设车辆物理尺寸相同的情况下,不安全集被定义为一个大小为 2W × 2L的矩形,其中W和L分别为每辆车的宽度和长度。我们指出本研究在这方面存在的局限性:实际中必须能够调节车辆尺寸,以应对道路上车辆类型的多样性。
注意,坐标系固定在标记为B的目标车辆上(图中以红色方块标示)。
对于特定策略(merging 或在 current 车道上行驶),不安全集将沿以下相对动力学传播:
$$ \dot{x}
r= f
{mode,A}(x_A, T_A) - f_{mode,B}(x_A -x_r, T_B) $$
$$ \dot{y}
r= v_A - v_B $$
其中 $ x_r=x_A -x_B $ 和 $ y_r=y_A -y_B $。这里 $ f
{mode}(x, T) $ 定义为
$$ f_{mode}(x, T)=
\begin{cases}
f_{appr}(x, T)= \frac{K}{T}(x+ a) \
f_{stab}(x, T)= -\frac{K}{T}(x - b) \
f_{straight}(x, T)= 0
\end{cases} $$
根据车辆所处的模式(即接近、直线行驶稳定(其中有效 $\dot{x} = 0$))。注意,周期T与给定车辆的激进性或敏捷性相关。特别是TA会在碰撞预测方法中产生不确定性。因此,我们将对方的激进性(嵌入于TA中)和目标车辆速度vB分别视作目标车辆的扰动d和输入u。据此,我们将(1.4)重新表述为:
$$ \dot{x}
r= f
{mode,A}(x_A, d) - f_{mode,B}(x_A -x_r, T_B) $$
$$ \dot{y}_r= v_A - u $$
C. 碰撞风险估计
为了构建目标车辆对潜在未来碰撞的感知预测框架,我们通过计算初始不安全集(图7中车辆A周围的蓝色区域)在有限预测时域内沿系统混合动力学的时间演化,来计算前向可达集。由于每种策略(及相应模式)中使用的连续动力学是线性的,因此图7中系统的相对动力学也是线性的:
$$ \dot{z}= A(d) z+ b(d, u) $$
$$ z=
\begin{bmatrix}
x_A \
x_r \
y_r
\end{bmatrix} $$
其中,对于每种组合策略,A(d)和 b(d,u)均根据(1.4)和 (1.5)求得。附录对此进行了更详细的描述。给定系统在(1.7)中的动态特性,时间范围 t内的精确可达集 Reachu(μ, u,d, t)定义如下
$$ R(\mu, u, d, t)=
\left{ z(u, d, t) \middle| z(u, d, t)
=
\int_0^t (A(d, u(\tau)) z(\tau)+ b(d, u(\tau)))d\tau \right} \quad |u(\tau) \in U , d(\tau) \in D $$
其中U和D分别为输入u和扰动d的有界凸集, μ是车辆 A和B的组合策略。接下来,我们确定初始不安全集在某一未来时间与坐标原点相交(即与目标车辆发生碰撞)时的可达集。导致碰撞的输入集合,即Uunsafe,因此被定义为
$$ U_{unsafe}={u | \exists d \in D \text{ and } t \ge 0 \text{ such that } (0, 0)
r \in Reach(\mu, u, d, t)} $$
因此,关于组合策略 μ 的最终不安全前向可达集 Reachu(μ,t) 定义为
$$ Reach_u(\mu, t) \triangleq \bigcup
{u\in U_{unsafe},d\in D} R(\mu, u, d, t), $$
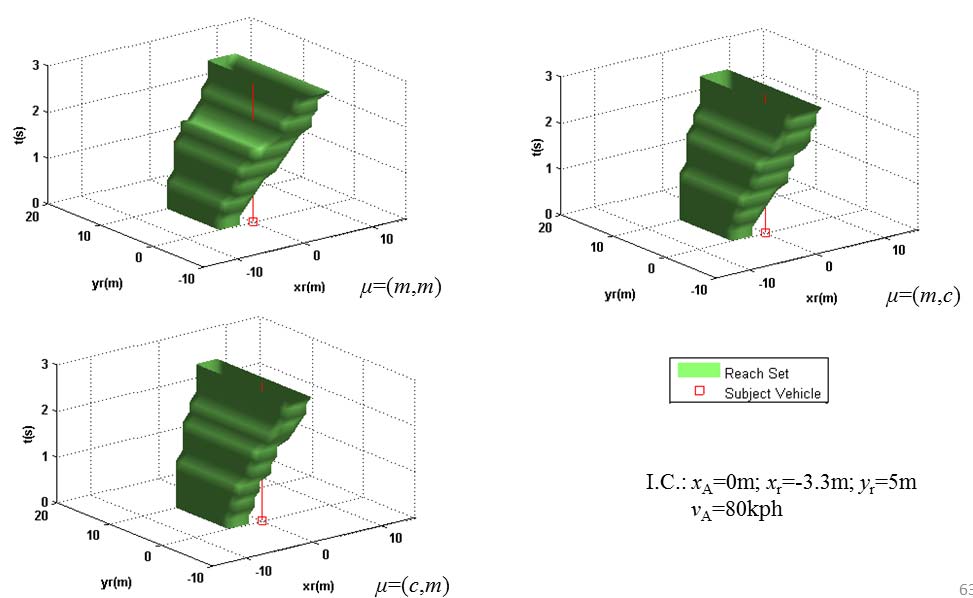
如图8所示。在图中,组合策略c和m再次分别表示直行于当前车道以及并道(换道)。需要注意的是,这些策略可能通过混合换道模型具有多种模式(例如,接近和稳定,或如公式1.5中定义的直行)。同样值得注意的是,在图中,两辆车同时并道的情况相比其他仅有一辆车并道而另一辆车保持在当前车道的情况,会产生更大的不安全集扩展。
显然,当两辆车都保持在当前车道时不会产生不安全集,因此未在图中显示。博弈论模型根据每辆车采取某一策略(直行于当前车道或并道)的概率对这些情况进行了综合,并得出在事件视界内的组合不安全可达集(即接下来的几秒,如后文图9所述并讨论的内容)。
D. 博弈论评估
为了组合为各个组合策略计算出的离散前向可达集,我们采用博弈论。需要注意的是,与我们之前的工作[44]不同,目标车辆不能对其对应车辆主张优先权。因此,我们设计了一个非合作纳什博弈[51],其效用函数基于上述工作[44]中讨论的驾驶员决策模型中的设计,用于估计对应车辆对目标车辆策略的响应策略。该博弈论模型相关的收益在附录中简要描述。
在非合作纳什博弈中,尽管通常不存在纯策略解[51],但鞍点的存在是有保证的。我们定义p1和q1为车辆A和B直行的概率,p2和q2为车辆A和B变道的概率。双矩阵博弈(UA, UB)的混合策略解(p
, q
)由[44]中设计的效用函数推导而来,其满足以下不等式,对所有p ∈ P和q ∈ Q [52],[53]成立:
$$ p^{
T} U_A q^{
} \ge p^{T} U_A q^{
} $$
$$ p^{
T} U_B q^{
} \ge p^{
T} U_B q $$
其中p和q分别为参与者A和B在纯策略空间(P和Q均定义为区间[0,1])上的概率分布。给定一个纳什解(组合策略上的最优概率分布),初始不安全集的最终可达集是关于最优概率分布的离散不安全可达集的概率组合。因此,对 R 2× 的概率碰撞预测,即Reach(t),定义为
$$ Reach(t)= \sum_{i=1}^2 \sum_{j=1}^2 p_i q_j Reach_{ij}(\mu_{ij} , t) $$
其中 是碰撞概率 ω 的有界凸集;即 [0, 1]。
例如,假设车辆A和B直行的概率,即movingstraight, p1和q1,均为0.3。那么,策略组合的概率分别为0.49、 0.21、0.21和0.09。由于我们已经在前一节中给出了关于车辆组合策略下碰撞区域的离散可达集,因此得到概率可达集,Reach(t)在时间t= 0,1、2和3秒时,如图9所示。碰撞概率 ω在我们之前定义的不安全集内被设为1 (即发生碰撞),时间为t= 0秒。可以看出,随着时间的推移,碰撞概率最高的区域穿过目标车辆,且由于未来不同策略可能产生的影响,不安全区域随之扩散。
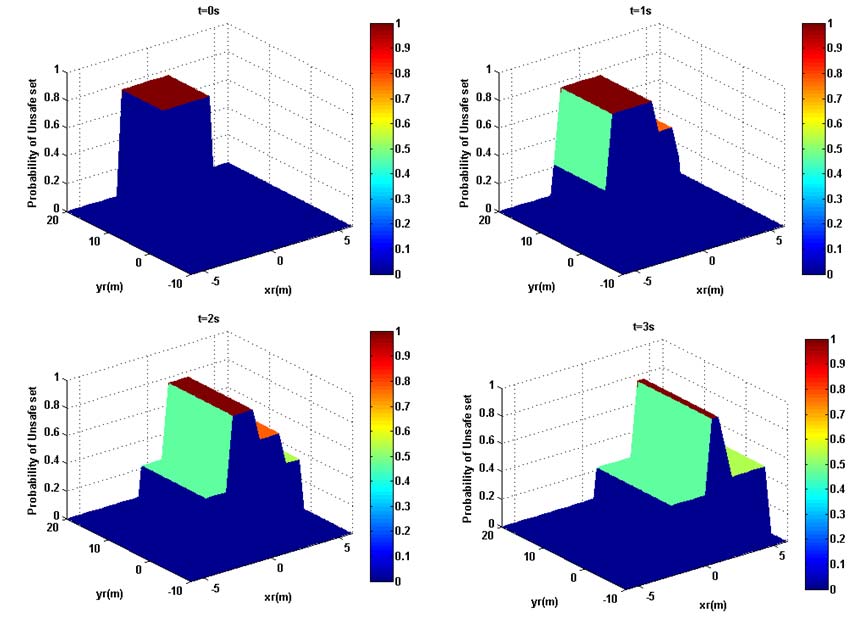
E. 主观风险评估
从心理学角度来看,“客观风险可被定义为卷入事故的客观概率”[39]。因此,我们将客观碰撞预测区域CO定义为在给定时间范围[0, h],内的可达区域Reach(t),其中 h表示目标车辆的预测时域, ω表示客观碰撞预测的碰撞概率。
$$ CO \triangleq {(x_r, y_r,\omega,t)|Reach(t) \text{ for } t \in[0, h]} $$
另一方面,主观的碰撞估计指的是驾驶员对客观碰撞概率[39]的感知。因此,我们提出为目标车辆设置一个可编程的安全保证水平,以表明给定的碰撞概率对该车辆构成威胁的程度。该安全保证水平sa可以被定义为目标车辆的敏捷性指数 qa ∈[0, 1]的补数,其最大值为1。基于此,我们定义
$$ sa= 1 - qa. $$
随后,主观估计的碰撞风险被转化为与给定安全保证水平 sa 一致的主观评估的碰撞区域Cs:
$$ Cs \triangleq {(x_r, y_r, t)|CO \text{ such that } 1 -\omega \le sa, \text{ for } t \in[0, h]} $$
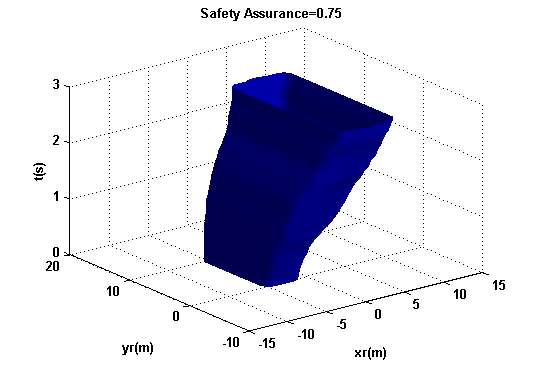
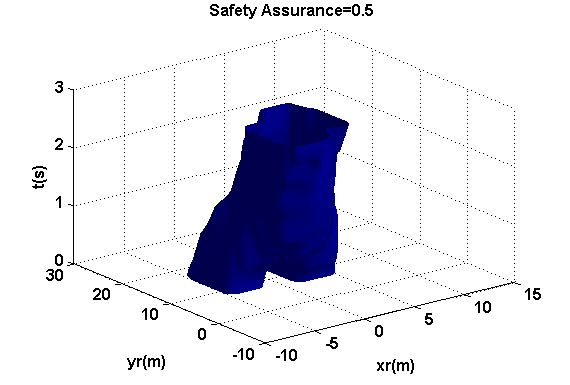
Cs覆盖了目标(或概率性)碰撞区域,在某种意义上,它作为目标车辆对未来碰撞感知的一个确定性边界。图10展示了两种不同安全保证水平下的主观碰撞区域,sa={0.25,0.75}。安全保证水平越高,目标车辆希望避开的区域就越大。
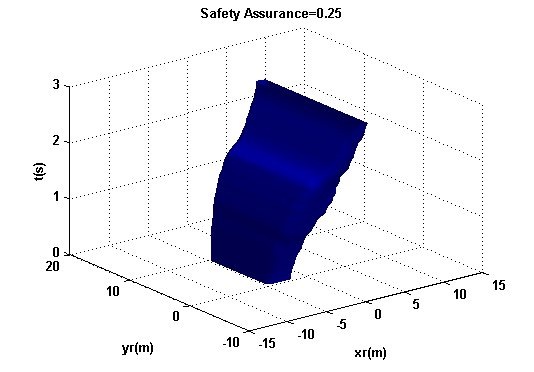
IV. 基于碰撞风险估计的驾驶控制
主观感知的不安全区域被视为目标车辆的关键风险区域。为了体现这一点,我们设计了一种控制器,迫使车辆保持在该风险区域之外,称之为主观预测安全控制器(SPSC)。该控制器基于模型预测控制(MPC)的通用框架进行设计,因为模型预测控制能够使我们考虑相关约束在时域中予以考虑,这正是如图10所示的不安全区域的定义方式。附加约束包括对加速度/减速或速度的物理限制。
A. 控制目标
SPSC的主要目标是确保目标车辆保持在上述定义的不安全区域Cs之外。为此,我们识别出Cs在R 3中与由(xr,yr, t) ∧xr= 0定义的平面的截面,因为目标车辆位于相对坐标系的原点。因此,我们推导出Cv为
$$ Cv \triangleq {(y_r, t)| (x_r, y_r, t)_r \in C_S \wedge x_r= 0, \text{ for } t \in[0, h]} $$
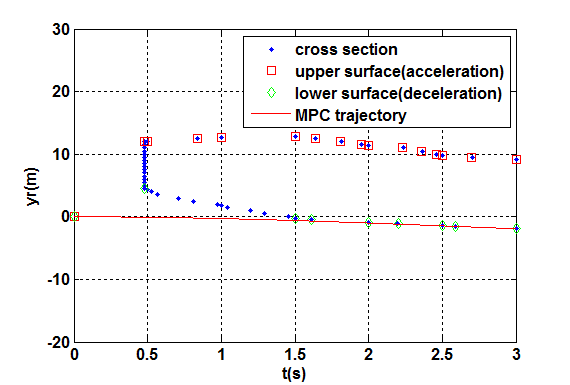
SPSC必须设计为生成一个速度曲线,以避免Cv。然而,如图11所示,目标车辆可通过两种方式避开Cv:一种是通过其上表面(加速),另一种是通过其下表面(减速)。在这种情况下,有必要选择两种方案中总体成本最小的控制方案。
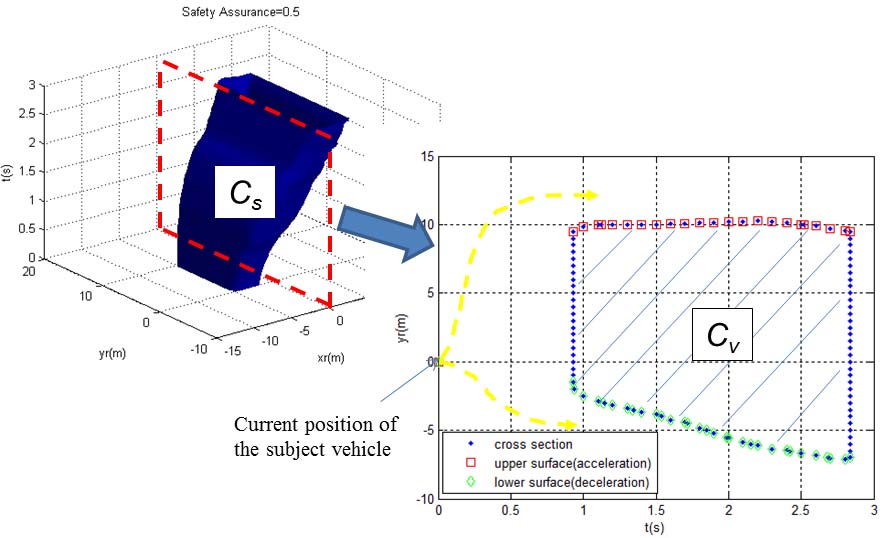
B. 控制设计
我们考虑纵向的一个简单运动学模型。设yr为状态变量 x1。相应的纵向速度和控制输入分别表示为状态变量 x2 和加速输入 u。因此,我们得到状态方程 $\dot{x}=f(x,u)$,其中 $x=[x_1 x_2]^T$ 作为
$$
\begin{bmatrix}
\dot{x}
1 \
\dot{x}_2
\end{bmatrix}
=
\begin{bmatrix}
x_2 \
u
\end{bmatrix}.
$$
相应的模型预测控制以满足以下目标的方式构建:即最小化在$t=[t_o t_f]$上定义的代价函数J,其中$t_f= t_o+ h$。
$$
\min
{u(\cdot)} J(x, u) \quad \text{s.t.} \quad \dot{x}= f(x, u), \quad x_1(t_0)= 0 \
x_1 \ge C_{v,upper} \vee x_1 \le C_{v,lower} \
x_2(t_f)= 0 \
a_{min} \le u \le a_{max}
$$
其中 $a_{min}$ 和 $a_{max}$ 表示控制输入(加速)的下界和上界。我们将 J 定义为一个二次代价函数,用于最小化在有限时域内相对于原点的过度状态偏差以及控制 effort:
$$
J= \int_{t_0}^{t_f} (x^T Qx+ u^T Ru)d\tau
$$
其中Q和R为权重矩阵。主要控制目标通过满足轨迹约束$x_1 \ge C_{v,upper} \vee x_1 \le C_{v,lower}$来实现,从而将状态引导至Cv的边界之外。
C. 所设计SPSC的实际解决方案
为在滚动预测时域内求解最优控制问题(OCP),我们采用多种次优近似方法相结合的方式;即有限元方法和配置方法[54]。通过结合这两种方法,我们能够高效地获得模型预测控制(MPC)的解,而无需进行大量的积分运算[55],[56]。首先,有限元方法通过将轨迹参数化为如下形式来估计系统状态和控制轨迹
$$
\hat{x}=\sum \alpha_i \cdot \phi_i,
$$
使用基函数 $\phi_i(t)$,其中 $\alpha_i$ 为标量系数。然而,为了提高参数化的精度,在(1.21)中,必须最小化投影误差的积分:
$$
\min \int_{t_0}^{t_f} (x - \hat{x})\cdot \phi(\tau)d\tau.
$$
接下来,我们使用一种称为配置的数值方法对轨迹进行参数化,从而在无需解析积分的情况下求解OCP[56]。通过对基函数在时间上进行离散化,所需的模型预测控制(MPC)因此被转化为一个非线性规划问题。具体而言,该MPC问题通过非线性约束优化求解。定义在$[t_o t_f]$上的系统状态和控制输入通过B样条基函数参数化为
$$
\hat{x}
1= \Phi \cdot \alpha \quad \hat{x}_2= \Phi \cdot \beta \quad \hat{u}= \Phi \cdot \gamma
$$
其中基函数矩阵$\Phi$以及系数向量$\alpha$、$\beta$和$\gamma$定义为
$$
\Phi=[\phi_1 \cdots \phi_N], \quad \phi_i=[\phi_i(0),\cdots,\phi_i(h)]^T \
\alpha=[\alpha_1 \cdots \alpha_N]^T \quad \beta=[\beta_1 \cdots \beta_N]^T \quad \gamma=[\gamma_1 \cdots \gamma_N]^T
$$
现在,设 $\rho$定义为
$$
\rho=[\alpha \quad \beta \quad \gamma]^T.
$$
然后,初始的模型预测控制问题(1.19)被转化为
$$
\min \sum
{i=1}^{N_I} (\hat{x}^T Q\hat{x}+ \hat{u}^T R\hat{u}) \quad \text{Subject to} \quad (d\Phi \cdot \alpha - \hat{x}
2) \cdot \phi_i= 0, \quad i= 1,\cdots, N \
(d\Phi \cdot \beta - u) \cdot \phi_i= 0, \quad i= 1,\cdots, N \
x_1 \ge C
{v,upper} \vee x_1 \le C_{v,lower} \
\hat{x}
1(t_0)= 0, \quad \hat{x}_2(t_f)= 0 \
a
{min} \le \hat{u} \le a_{max}
$$
其中,$d\Phi$是基函数矩阵 $\Phi$导数的离散配点矩阵。$N_I$表示用于近似定积分的任何数值方法,例如梯形法则[57]。注意,此时最优控制问题已转化为一个生成系数向量 $\rho$的优化问题,可使用已知工具(如MATLAB命令fmincon)求解该非线性约束优化问题。
V. 仿真
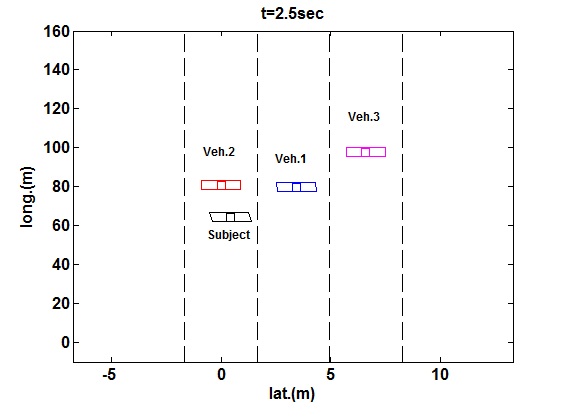
为了研究所提出方法的性能,我们考虑一条单向行驶的三车道公路。我们将车道宽度设置为3.3m。第一车道的中心线横向位于0m处,第二车道位于3.3m处,第三车道位于6.6m处。每条侧边车道中至少有一辆车辆。车辆1和车辆2在纵向方向上靠近目标车辆,以生成有意义的不安全可达集,用于我们的评估。
A. 仿真结果
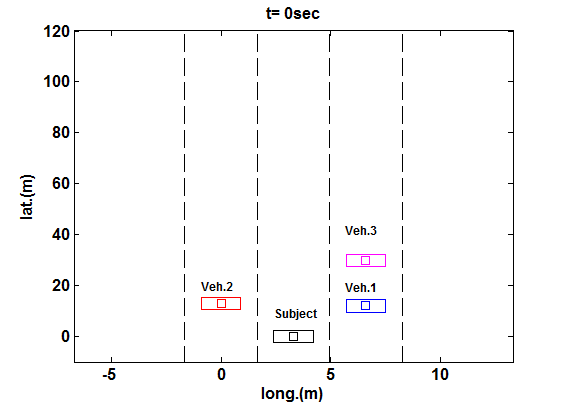
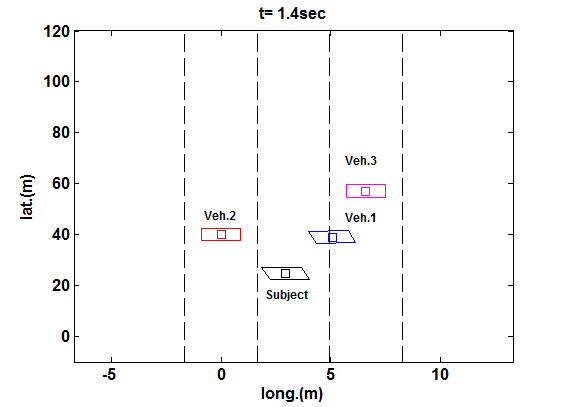
1) 正常安全保证场景 :首先,我们模拟一辆具有正常安全保证水平sa= 0.5的主车。初始时刻(及预测结果)的总体风险估计(即对客观风险的主观评估)如图12所示。不安全可达集分析(考虑了两个相邻车道)基于混合策略博弈论分析的结果,预测了在竞争驾驶员激进程度值的不同可能水平下,各车辆可能采取的可能操纵动作范围。安全保证因子有助于根据公式(1.16)对该风险进行缩放,从而生成如图12上图所示的Cs的形状。该图的下图描绘了在t= 0时刻的Cv,即根据公式(1.17)得到的Cs的截面,以及在同一时间范围内的SPSC生成的轨迹。这意味着目标车辆需要减速(即其相对纵向位置yr会随时间变为负值),以避免因相邻车道的车辆可能侵入其车道而导致的潜在碰撞,尽管侵入行为并非绝对会发生。然而,考虑到这些其他车辆也被设定为遵循博弈论决策模型,旨在最大化自身效用以实现其驾驶目标[44],这一结果是可能发生的,并且确实如下面所述会发生。具体而言,如图13顶部面板所示,目标车辆从中间车道起步,其右侧有两辆车辆,左侧各有一辆车。目标车辆遵循SPSC控制策略,如上所述,该策略要求其减速,以避免在接下来的几秒内因相邻车辆可能侵入中间车道而发生碰撞。这反过来使得(或可能鼓励了)一辆竞争车辆(车辆1)如图13中图所示变道进入中间车道。对于目标车辆而言,这是否为一个理想的结果或许值得商榷。然而,所提出的决策模型的目的并非不惜一切代价实现最优性能。当仅考虑纯粹性能时,该结果可能并非最佳,但在事件视界内存在潜在碰撞风险的情况下,可能是合理的。由于该操作(以及由此产生的有限车头间距),目标车辆变道至最左侧车道。此时,如图13底部所示,目标车辆保持在最左侧车道,并以其期望速度继续向前行驶(由于相邻车道中存在车辆1,此时变道无法获得额外的车头间距,因此没有立即变道的好处)。换句话说,目标车辆遵循此前建立的基本驾驶模型[44],对其当前车道保持满意。此阶段未显示主观风险估计的重新评估,因为此时不安全可达集未与目标车辆相交(在预设时间范围内未预见任何碰撞)。然而,交通状况可能随时间变化,届时目标车辆将重新评估交通状况(如同其定期执行的操作一样)。那时确实可能会考虑额外的变道操作。
2) 高敏捷性场景 :接下来,我们在安全保证水平 sa 为 0 的情况下模拟相同场景。当 sa= 0 时(即目标车辆处于高度敏捷状态,或更直白地说非常激进),根据图14所示的零安全保证水平,初始时不存在对碰撞风险的主观感知。因此,车辆不会减速;相反,它会如图15所示进行加速。这是因为在博弈论建模中所使用的效用函数反映了目标车辆的激进性或敏捷性,进而影响了目标车辆与车辆1之间的交互行为,并降低了车辆1变道进入目标车辆车道的可能性,因为该车辆也会根据其自身的驾驶决策模型[44]考虑潜在碰撞。显然这是一个极端情况,但为了进行比较和完整性考虑,本文仍将其纳入讨论。
此外,鉴于碰撞概率较低且安全保证水平较低,SPSC在所考虑的时间范围内不会启动。换句话说,主体车辆忽略来自相邻车辆(如车辆1)的任何潜在威胁并加速。然而,随着相对距离的减小,由于相邻车道上存在车辆而导致的碰撞概率无法无限期地忽略,因此目标车辆在此场景结束时停止加速。目标车辆未来的动作将遵循相同的一般方法,但由于处于零安全保证水平,如果其他车辆也表现出潜在的危险行为,则该车辆在后期阶段发生碰撞的可能性并非不大。
3) 高度谨慎行为 :最后,我们考虑相同的场景,但此次安全保证水平为1(即目标车辆表现得非常谨慎)。图16显示了在初始阶段以及与之前场景相同预设时间区间内的主观碰撞风险估计,反映了目标车辆对碰撞风险的增强感知。因此,如图中底部面板所示,车辆显著减速(类似于之前安全保证水平为0.5的情况,但更为明显)。整体行为如图17所示。与前述先前情况(normal行为)的不同之处在于,由于主观风险估计较大,目标车辆以更高的减速度减速。这一点体现在目标车辆相对于其前车(车辆2)的最终相对距离增加,目标车辆因车辆1变道至中间车道而受到压力,随后向左车道变道。
B. 结果总结
总之,我们可以看到,正常和谨慎的车辆会根据其在预设时间范围内对与相邻车辆发生碰撞风险的主观感知而降低各自的速度(假设这些其他车辆可能考虑进行变道操作并侵入目标车辆所在的车道)。这使得其他车辆(例如上述相关仿真中的车辆1)能够驶入目标车辆所在的车道。这本身是因为这些其他车辆也在其所采用的博弈论框架内努力最大化自身效用,以实现各自的驾驶目标。相反,高度敏捷或激进的目标车辆会加速并与竞争车辆保持相对较小的相对距离,从而阻止其变道。这种情况再次发生的原因在于目标车辆的行为模式(即其敏捷性或激进性)以及竞争车辆所遵循的决策模型,该模型在博弈论框架内重视安全性。换句话说,这些其他车辆也能感知到敏捷目标车辆的存在,并对其做出适当反应。需要注意的是,这些交互作用也可以从驾驶员礼让(或缺乏礼让,视情况而定)的角度来理解,例如希达斯[58]所讨论的那样。然而,上述方法是在时间范围内看待该问题,不仅包括希达斯所讨论的强制性车道变换,还包括车辆可能进行强制性和随意性车道变换的一般场景。
六、结论与未来工作
在本研究中,我们考虑了驾驶中碰撞风险的客观评估与主观评估之间的区别,并提出了一种基于称为安全保证水平(与激进性或敏捷性呈负相关)参数的自动驾驶碰撞风险模型。我们进一步提出了一种混合模型,用于描述给定车辆在变道过程中的轨迹。该模型旨在根据预设的敏捷性水平生成多种驾驶轨迹。借助此模型,我们在双智能体系统框架下,基于相对坐标系中建立的前向可达集概念,实现了对碰撞的客观预测。这种碰撞的客观预测假设了一种无法保证竞争车辆理性的场景(涵盖全部激进程度),并使用混合策略纳什博弈进行评估。接下来,我们设计了一个主观碰撞感知模型,该模型反映了目标车辆的可编程敏捷性(或反向的安全保证水平),以提供实际驾驶中所必需的真实感,并避免在无碰撞自动驾驶模型中常被假定的极端保守性。在此安全保证水平的基础上,我们进一步开发了驾驶控制器,利用模型预测控制理论来最优地规避任何预期的碰撞。结果表明,即使在目标车辆行为较为激进的情况下,结果也具有直观性,并且表明单方面的激进车辆本身并不必然构成问题,当然前提是其他车辆不会同样表现出激进行为。这一点在我们的其他研究工作中也有进一步讨论[28],[44]。
目前的研究显然存在局限性。特别是,碰撞预测评估算法并非一种针对即将发生的碰撞做出响应的碰撞缓解/避免方案。其功能是通过博弈论分析预测竞争车辆可能的未来车道变换行为,对各车辆可能的未来路径进行可达性分析,并评估数秒后是否存在潜在的未来碰撞风险(例如如图9所示)。在此基础上,我们设计了一种模型预测控制策略以选择一条无碰撞路径。换句话说,我们的工作是评估未来的碰撞可能性(或碰撞风险)并提前规划。这种规划过程本质上并不旨在应对无法预知的紧急威胁。为了更全面地避免碰撞,我们必须将本方法与其他措施相结合。这些措施可能会覆盖当前计划(例如,当即将发生车道侵入时,大幅降低车辆速度)。当然,这些措施较为激进,若执行不当,可能引发其他问题(例如目标车辆后方车辆因减速过快而导致追尾碰撞)。它会急剧减速)。然而,不可避免的是,自动驾驶的全面解决方案确实需要结合proactive规划以及reactive威胁缓解措施。
我们还假设竞争车辆的激进程度是已知且保持不变的。这一假设并不完全成立。在我们最近的研究中(在一个并行项目的背景下),我们开发了一种统计学习算法,该算法基于车道变换频率以及加速度/减速模式变化等指标来评估其他车辆的激进性,并通过人体受试者研究验证了该方案。我们计划将该方法应用于当前研究的扩展工作中,并将在不久的将来报告相关成果。
我们的工作还存在其他局限性,例如感知传感器(如自动驾驶中常用的激光雷达、前向和侧向雷达、摄像头以及相关的信号处理算法和硬件)能力有限,尤其是在某些环境因素下(如光饱和、雾、雨等会严重影响摄像头性能)。目前,我们的研究尚未真正考虑这些问题,但未来的工作显然必须加以考虑。
计算限制也同样存在。尽管所提出的接近方法试图在其优化任务中使用高效求解器,但求解最优控制策略的计算负担超出了当前车辆中常用电子控制单元的处理能力。然而,自动驾驶并非无需成本的方案。汽车制造商已经意识到这一问题,电子行业也正在快速发展自身的硬件解决方案(一些基于图形处理器),以满足自动驾驶中复杂算法所需的计算能力。
最后,需要指出的是,本文是正在进行的一项研究活动的一部分,旨在使用我们的基于dSpace的驾驶模拟器开展更广泛的人体受试者研究。我们将在不久的将来报告这项工作。我们还计划与行业合作伙伴合作,对所提出的算法进行试验场研究。这将需要一定时间,但我们相信在不远的将来能够实现,并将对此进行报告。

















 2520
2520

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









