







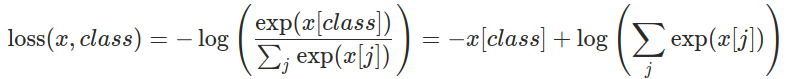

input 为 (N,C)维, 其中N为样本个数, C为分类数, 其中值为每个样本在某类上的得分, 注意这里不是概率, 可以为正也可以为负, 也可以大于1, 后面会经过softmax的处理, 统一变成概率的分布
target为N维, 其值为truth groud 的分类值
这个Loss就是正确得分(后面会转成概率)在所有得分所占的比重来确定的, 如果正确的概率为1, 其他都为0的话, 那么 根据上面的公式可得loss为0
然后特别特别重要的一点, 就是送入cross_entropy之前不要进行softmax归一化处理, 否则会训练不出来。因为归一化把信号变弱了, 而且你会发现cross_entropy久久不能为0, 然后可能造成logits为错误的one hot vector, 梯度消失, 参数得不到更新。这个bug耽误了我一年左右的科研时间!!!

















 3770
3770

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









