






实验代码
import torch
import matplotlib.pyplot as plt
# Logistic函数
def logistic(z):
return 1.0 / (1.0 + torch.exp(-z))
# ReLU
def relu(z):
return torch.maximum(z, torch.tensor(0.))
# 2个特征数为5的样本
X = torch.rand(2, 5)
# 含有5个参数的权重向量
w = torch.rand(5, 1)
# 偏置项
b = torch.rand(1, 1)
# 使用'torch.matmul'实现矩阵相乘
z = torch.matmul(X, w) + b
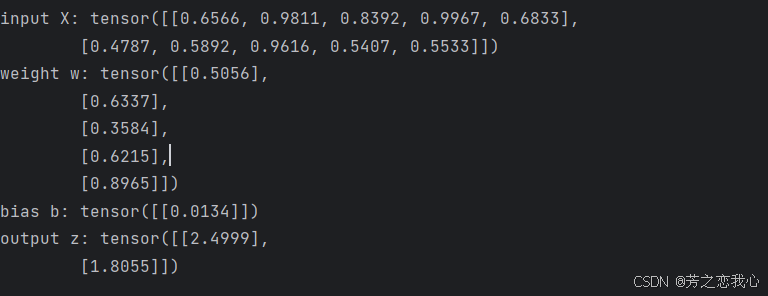
print("input X:", X)
print("weight w:", w, "\nbias b:", b)
print("output z:", z)
# Tanh函数
def tanh(z):
return (torch.exp(z) - torch.exp(-z)) / (torch.exp(z) + torch.exp(-z))
# 带泄露的ReLU
def leaky_relu(z, negative_slope=0.1):
a1 = (z > 0).float() * z
a2 = (z <= 0).float() * (negative_slope * z)
return a1 + a2
# 在[-10,10]的范围内生成10000个输入值,用于绘制函数曲线
z = torch.linspace(-10, 10, 10000)
plt.figure()
plt.plot(z.tolist(), logistic(z).tolist(), color='#8E004D', label="Logistic Function")
plt.plot(z.tolist(), tanh(z).tolist(), color='#E20079', linestyle ='--', label="Tanh Function")
ax = plt.gca() # 获取轴,默认有4个
# 隐藏两个轴,通过把颜色设置成none
ax.spines['top'].set_color('none')
ax.spines['right'].set_color('none')
# 调整坐标轴位置
ax.spines['left'].set_position(('data',0))
ax.spines['bottom'].set_position(('data',0))
plt.legend(loc='lower right', fontsize='large')
plt.savefig('fw-logistic-tanh.pdf')
plt.show()
plt.figure()
plt.plot(z.tolist(), relu(z).tolist(), color="#8E004D", label="ReLU Function")
plt.plot(z.tolist(), leaky_relu(z).tolist(), color="#E20079", linestyle="--", label="LeakyReLU Function")
ax = plt.gca()
ax.spines['top'].set_color('none')
ax.spines['right'].set_color('none')
ax.spines['left'].set_position(('data', 0))
ax.spines['bottom'].set_position(('data', 0))
plt.legend(loc='upper left', fontsize='large')
plt.savefig('fw-relu-leakyrelu.pdf')
plt.show()
运行结果
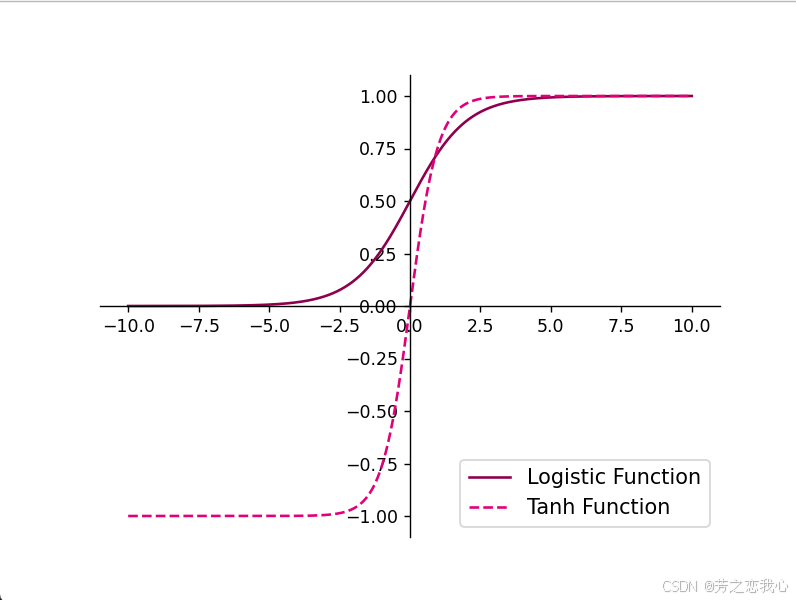
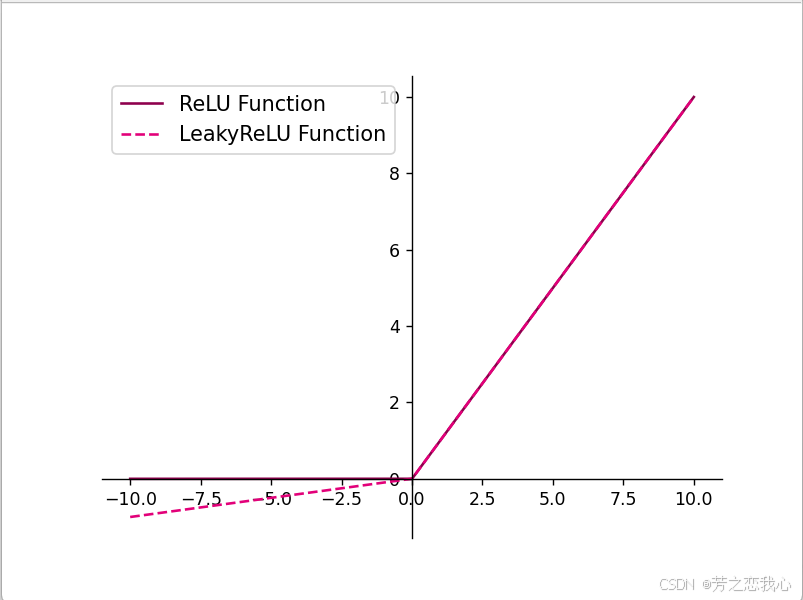
Sigmoid函数和ReLU函数的区别
Sigmoid函数:
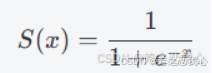
输出范围:(0,1)
特点:函数在 x=0x=0 处输出为 0.5,接近于 −∞ 时输出接近于 0,接近于 +∞ 时输出接近于 1。
ReLU 函数:
输出范围:[0,+∞)[0,+∞)
特点:如果输入 xx 小于 0,输出为 0;如果输入 xx 大于 0,输出为 xx 的值。
ReLU(x)=max(0,x)
2. 输出范围
Sigmoid: 输出被限制在 (0,1)(0,1) 的范围内,因此适合于处理概率值或二分类问题。
ReLU: 输出范围是从 0 到正无穷,能提供更大的响应值,适合用于深层网络。
3. 导数特性
Sigmoid:
导数可以用 Sigmoid 函数本身来表示:S′(x)=S(x)⋅(1−S(x))
当输入的绝对值很大时,导数的值会接近于 0,导致梯度消失(vanishing gradient)。
ReLU:
导数为:ReLU′(x)={0if x<01if x≥0,对于正输入,ReLU 可以提供恒定的梯度。
4. 计算效率
Sigmoid: 由于涉及指数运算,计算较慢。
ReLU: 计算非常简单,仅需取最大值,速度快。
5. 梯度消失问题
Sigmoid: 在反向传播中,输入值为极大或极小时,Sigmoid 函数的导数接近于 0,导致梯度消失。
ReLU: 不会出现梯度消失的问题,但可能会有“死亡 ReLU”现象,即某些神经元在训练过程中可能一直输出 0,从而无法更新。
6.
Sigmoid:常用于输出层,特别是在二分类问题中,能够输出概率值。
ReLU:常用于隐藏层,适合于深度学习网络,能够更好地处理非线性问题。

















 8074
8074

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









