







目录
1.概述
在设计开发过程中,芯片架构师确定划分、优化以及组装系统。根据设计的复杂性和集成度,设计人员可以从下面的3个流程中选择一个:
- 自顶向下的层次化设计方法
- 自底向上的设计方法
- 自顶向下的自顶向上相结合的设计方法
此外,时序收敛取决于模块或者芯片模式的数量,设计人员可以通过合并模式减少迭代,从而有效地有效地管理约束。
2.自顶向下的方法
方法概述:整个芯片被看作单个设计单元,约束施加在顶层,设计按照一个独立的单元进行综合。
优点:简单的使用模式,优化相对简单,不用关心步骤。
缺点:无法进行扩展,设计内容有任何轻微的改变都要求重新实现。
3.自底向上的方法
方法概述:这种方法与自顶向下的层次设计方法正好相反,它采用了分而治之的方法,先将芯片划分成为子芯片,再将子芯片划分为模块。为每个子芯片或模块创建约束,然后按照自顶向下的流程对其进行分析。每个模块基于自身的约束被单独优化,并在子芯片或芯片级中集成。
优点:便于扩展,当模块需要修改时,不需要综合整个设计。
缺点:(1)顶层集成时出现问题,模块在单独优化时可以满足它的工作时序,但是当模块在子芯片或芯片中集成时可能无法满足时序。(2)在层次化中的中间级或顶层设计中关键路径在模块级中可能不明显。这是因为在模块级创建的约束对于顶层和与之交互的相邻模块而言是不可见的。这会导致在集成多个模块时为满足模块内外时序的要求增加迭代次数。
3.1 实例一:约束冲突
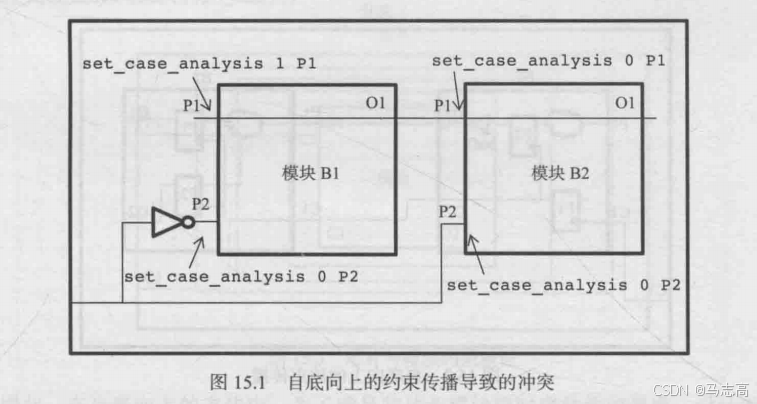
分析:
在该图中,模块级约束(如端口P1)被模块B1约束为1,而模块B2的端口P1被设置为0。芯片不可能同时使用两种工作模式,所以会有冲突。
自底向上的设计方法中,当约束向上传播时,可能存在3种变化:
- 只有芯片级的层次结构发生变化时,才会施加模块级的约束
- 为反映SOC上下文,模块级约束应被修改
- 由于约束在SOC上下文中没有任何意义,所以它被删除
3.2 实例二:约束传播
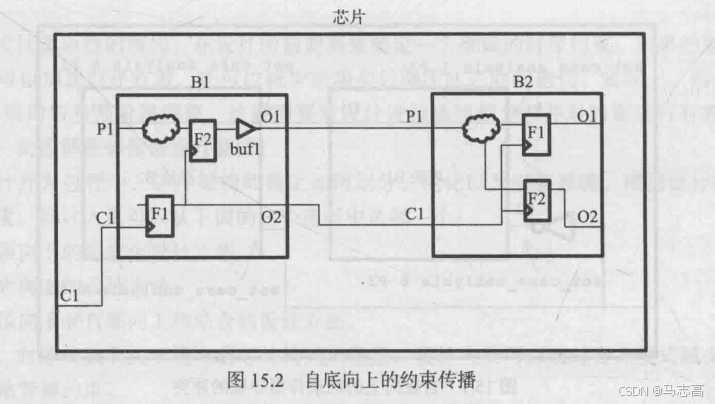
##模块B1的约束
create_clock -name C1 -period 10 [get_ports C1]
create_generated_clock -name GC1 -divide_by 2 -source C1 [get_pins F1/Q]
set_false_path -from F2
##模块B2的约束
create_clock -name C1 -period 20 [get_ports C1]
set_false_path -from P1 -to F1
##基于传播的芯片约束
create_clock -name C1 -period 10 [get_ports C1]
create_generated_clock -name GC1 -divide_by 2 -source C1 [get_pins B1/F1/Q]
set_false_path -from B1/F2
分析:
(1)由于GC1有效地驱动了由模块B2的C1端口建模时钟,因此B2的时钟不需要额外的约束。
(2)不需要模块B2中的从P1到F1的虚假路径,因为该路径已被来自B1/F2的虚假路径所覆盖
3.3 实例三:约束一致性
芯片的约束
create_clock -name C1 -period 8 [get_ports C1]
set_input_delay 6 -clock C1 [get_ports P1]
##模块的约束
create_clock -name C1 -period 10 [get_ports C1]
set_input_delay 4 -clock C1 [get_ports P1]
分析:在这个例子中,模块级和芯片级的时钟约束不一致。模块的时钟约束为10ns,然而在芯片级,它是由8ns的时钟驱动的。模块未在更快的时钟下运行,这可能导致芯片无法正常工作。同样,芯片级的输入延迟大于模块级的输入延迟。模块端口处的延迟不能低于芯片边界处的延迟,这表明输入延迟不一致,这是由于芯片级端口P1和其所连接的模块级的P1端口之间存在有限的飞行时间延迟产生的。
可见两种方法都存在着问题,所以设计者往往使用自顶向下的自顶向上相结合的设计方法。
4.自顶向下的自顶向上相结合的设计方法
方法概述:
为了进行精确的上下文敏感优化,模块的接口电平约束应该包括模块的信息,输入的到达时间,输出需要的时间以及诸如电容、负载、驱动单元等其他参数。这个方法还要确保在模块之间的延迟能够以均衡的方式进行正确的分割。这一过程称为预算。
时序预算要确保包含以下内容:
- 为满足顶层的时序需要,需要在模块间分配延迟。分配原则可以基于某一固定比例的时钟周期,或者取决于逻辑电平数的比例
- 在初始预算被分配给模块及模块被综合之后,一些模块可以有正裕度,一些模块可以有负裕度。改进模块约束后,模块输入输出延迟的裕度按照正裕度路径不能变为负裕度路径同时负裕度路径不能变得更差的方式重新分配。
- 该过程可以迭代,但是出现增量变化时仅需要对受影响的模块综合,而不需要综合整个设计。
给出如何在顶层约束中对模块进行预算的过程。
实例:
在该例中,芯片级的时钟周期为20ns。令输入延迟和输出延时均为3ns。芯片的约束如下:
##芯片的约束
create_clock -name C1 -period 20 [get_ports C1]
set_input_delay 3 -clock C1 [get_ports P1]
set_output_delay 3 -clock C1 [get_ports O1]
假设所有互连延迟为1ns,模块之间的直通为4ns,那么得到模块的约束为:
##模块B1的后预算约束
create_clock -name C1 -period 20 [get_ports C1]
set_input_delay 4 -clock C1 [get_ports P1]
set_output_delay 17 -clock [get_ports O1]
##模块B2的后预算约束
ceate_clock -name C1 -period 20
set_input_delay 4 -clock C1 [get_ports P1]
set_output_delay 12 -clock C1 [get_ports P1]
##模块B3的后预算约束
create_clock -name C1 -period 20 [get_ports C1]
set_input_delay 9 -clock C1 [get_ports P1]
set_output_delay 4 -clock C1 [get_ports P1]
如果这些预算分配会导致任何模块具有负裕度,则要重新分配具有正裕度的模块的延迟。例如:如果模块B1具有1ns的负裕度且B2具有1ns的正裕度,则重新分配延迟。
##模块B1的后预算约束
create_clock -name C1 -period 20 [get_ports C1]
set_input_delay 4 -clock C1 [get_ports P1]
set_output_delay 16 -clock [get_ports O1]
##模块B2的后预算约束
ceate_clock -name C1 -period 20
set_input_delay 5 -clock C1 [get_ports P1]
set_output_delay 12 -clock C1 [get_ports P1]
##模块B3的后预算约束
create_clock -name C1 -period 20 [get_ports C1]
set_input_delay 9 -clock C1 [get_ports P1]
set_output_delay 4 -clock C1 [get_ports P1]
5.多模式合并
概述内容:一个芯片可以具有多种工作模式,比如具有快速时钟的功能模式、具有慢时钟的功能模式、测试模式、用于省电的随眠模式。试图让一个设计运行在所有模式上且满足时序是非常困难的,而且迭代非常费力,这种分析通常称为多模式多角度分析(MMMC)。
模式合并使一种技术,它将不同的工作模式的约束结合起来形成单一的模式。这个单一的约束是一个假象的模式,是将所有模式结合起来所产生的模式。在合并时,遵守以下准则:
- 合并后任何路径和对象的约束不得少于单个模式下的约束。有效的合并约束不应该比任何一个模式乐观。
- 合并约束必须容易被设计者理解。
- 合并约束不应该导致太多的命令或扩展太多的路径,因为它可能会造成实现工具的崩溃。
- 理论上,所有模式都可以合并为一个陌生,但通常不会这么做。合并仅限于一个较小的集合,从而在过度悲观、可读性及不需要太多的异常之间取得一个平衡点。
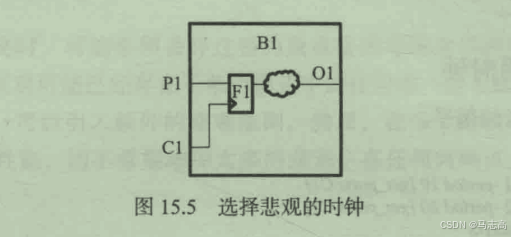
5.1 选择悲观时钟
考虑下图所示的电路,模式1的时钟周期为10ns,模式2的时钟周期为5ns。合并模式中,选择时钟为5ns,这样任何路径的约束都不会超过单个模式。
##模式1
create_clock -name C1 -period 10 [get_ports C1]
##模式2
create_clock -name C1 -period 5 [get_ports C1]
##合并模式
create_clock -name C1 -period 5 [get_ports C1]
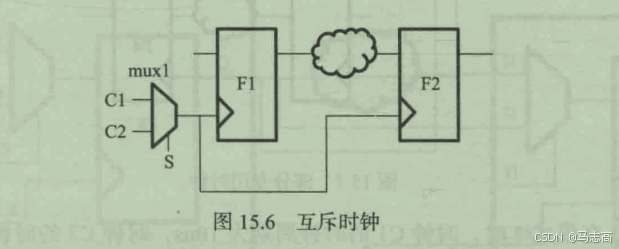
5.2 时钟互斥
考虑下面的电路,该例给出了在两种不同模式中具有约束冲突的时钟多路复用结构。
##模式1
create_clock -name C1 -period 10 [get_ports C1]
set_case_analysis 0 mux1/S
##模式2
create_clock -name C2 -period 40 [get_ports C2]
set_case_analysis 1 mux1/S
分析:模式1中的C1的时钟周期为10ns,C2未定义时钟,且多路复用器的选择线设置为0,模式2时,C1未设置时钟,C2的时钟周期为40ns,且多路复用器的选择线设置为1。这种情况下通过定义一个set_clock_group -logically_exclusive来实现
##合并模式
create_clock -name C1 -period 10 [get_ports C1]
create_clock -name C2 -period 40 [get_ports C2]
set_clock_group -logically_exclusive -group C1\ -group C2
5.3 部分专用时钟
##模式1
create_clock -name C1 -period 10 [get_ports C1]
create_clock -name C2 -period 20 [get_ports C2]
set_case_analysis 0 mux1/S
##模式2
create_clock -name C1 -period 10 [get_ports C1]
create_clock -name C2 -period 20 [get_ports C2]
set_case_analysis 1 mux1/S
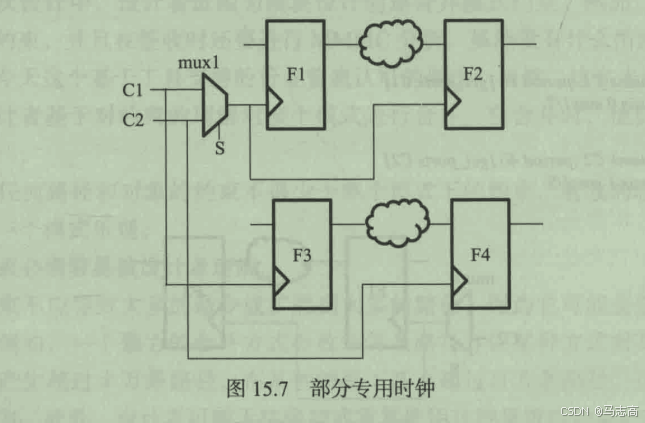
分析:
在模式1时,F1,F2,F3采用的C1的时钟,F4采用的是C2的时钟。
在模式2时,F3采用的是C1的时钟,F1,F2,F4采用的是C2的时钟。
##合并模式
create_clock -name C1 -period 10 [get_ports C1]
create_clock -name C2 -period 20 [get_ports C2]
create_generated_clock -name GC1 -combinational -source [get_pins mux1/A] [get_pins mux1/Z]
create_generated_clock -name GC2 -combinational -source [get_pins mux1/B] [get_pins mux1/Z]-add
set_clock_group -physically_exclusive -group GC1 -group {GC2}
5.4 合并功能和测试模式
下图,该例中扫描触发器用于连接设计和扫描链。
##模式1
create_clock -name C1 -period 10 [get_ports C1]
set_case_analysis 0 [get_ports TE]
##模式2
create_clock -name C1 -period 40 [get_ports C1]
set_case_analysis 1 [get_ports TE]
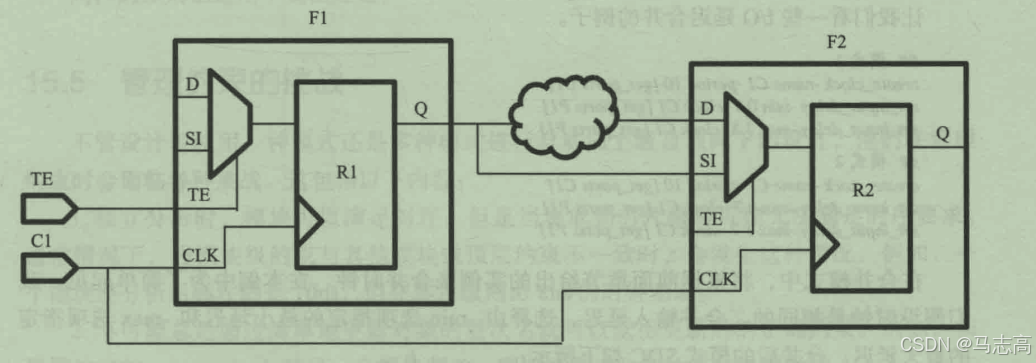
分析:功能模式下,测试使能引脚设置为0,时钟周期为10ns。在测试模式下,测试使能引脚设置为1,时钟周期为40ns。在合并模式下,必须考虑两个时钟。但是,测试使能引脚上的set_case_analysis将会被丢弃。在合并模式下,从周期为10ns的时钟到所有连接扫描输入引脚(SI)寄存器的路径将被使能。因此,需要设计中从周期为10ns的时钟到所有描述输入引脚(SI)定义一条虚假路径。
##合并模式
create_clock -name C1 -period 10 [get_ports C1]
create_clock -name C2 -period 40 [get_ports C1] -add
set_clock_group -physically_exclusive -group C1 -group C2
set_false_path -from C1 -to F*/SI
5.5 合并同一时钟的I/O延迟
##模式1
create_clock -name C1 -period 10 [get_ports C1]
set_input_delay 0.5 -clock C1 [get_ports P1]
set_input_delay 1.5 -clock C1 [get_ports P1]
##模式2
create_clock -name C1 -period 10 [get_ports C1]
set_input_delay -min 0.7 -clock C1 [get_ports P1]
set_input_delay -max 1.7 -clock C1 [get_ports P1]
##合并模式
create_clock -name C1 -period 10 [get_ports C1]
set_input_delay -min 0.5 -clock C1 [get_ports P1]
set_input_delay -max 1.7 -clock C1 [get_ports P1]
分析:在合并模式中,选择由-min选项指定的最小延时和-max选项指定的最大延时,同样原则适用于输出延时。
5.6 使用不同的时钟合并I/O延迟
##模式1
create_clock -name C1 -period 10 [get_ports C1]
create_clock -name C2 -period 20 [get_ports C2]
set_input_delay -min 0.5 -clock C1 [get_ports P1]
set_input_delay -max 1.5 -clock C1 [get_ports P1]
##模式2
create_clock -name C1 -period 10 [get_ports C1]
create_clock -name C2 -period 20 [get_ports C2]
set_input_delay -min 0.7 -clock C2 [get_ports P1]
set_input_delay -max 1.7 -clock C2 [get_ports P1]
分析:合并模式下,输入延时需要对这两个时钟和时钟间需要的时钟组建模。因为现在对两个时钟定义输入延时需要在set_input_delay约束中使用-add_delay选项。输出延时同样适用。
create_clock -name C1 -period 10 [get_ports C1]
create_clock -name C2 -period 20 [get_ports C2]
set_input_delay -min 0.5 -clock C1 [get_ports P1]
set_input_delay -max 1.5 -clock C1 [get_ports P1]
set_input_delay -min 0.7 -clock C2 [get_ports P1] -add_delay
set_input_delay -min 1.7 -clock C2 [get_ports P1] -add_delay
set_clock_group -logically_exclusive -group {C1} -group {C2}
6.约束面临的挑战
- 独立分析时,模块可以满足时序,但是当集成到芯片级时可能无法满足时序要求。通常情况下,当模块级约束与其他模块或者顶层约束不一致时,会发生这种情况。例如,一个模块经分析后标注的是10ns,但在芯片级则由8ns的时钟驱动。
- 不可能总是通过简单地更新对象的层次名就可以获得更新后的正确约束。例如,如果模块级别的create_clock被另一个模块驱动,则它可能成为芯片级的生成时钟。
- 在芯片级上跨越模块边界的关键路径在模块级看起来可能并不重要。通常情况下,如果跨模块的顶层黏合逻辑的延迟分配未正确完成,会发生这种情况。
- 对设计所做的优化可能不再模拟约束。
- 多模式分析挑战包括时序收敛迭代和遗漏时序路径
- 模式合并在理论上听起来是一个强大的概念,但是实际上在芯片设计中它不一定能成功,因为它固有的限制在于无法确定那些模式能够合并。在试图消除冲突时,新添加的约束可能导致不必要的优化。虽然并不清楚,模式合并可能会将芯片的性能和面积放在该表上,因为它是速度与精度的平衡。



















 6937
6937

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











