




目录
1.简介
pandas 库简介
pandas 是一个基于 Python 的开源数据处理和分析库,提供了高效、灵活的数据结构(如 DataFrame 和 Series),专门用于处理结构化数据(如表格数据、时间序列等)。它是数据科学、机器学习和统计分析中的核心工具之一。
核心功能
- 数据读取与写入:支持从 CSV、Excel、JSON、SQL 数据库等多种格式加载数据,并导出为多种格式。
- 数据清洗:处理缺失值、重复值、异常值,支持数据类型的转换与规范化。
- 数据操作:支持筛选、排序、聚合、合并、分组、透视等操作。
- 时间序列处理:提供强大的日期和时间数据处理功能,如重采样、时区转换等。
- 高性能计算:底层基于 NumPy 和 C 优化,支持大规模数据的高效处理。
适用场景
重要函数概览
| 类别 | 函数 | 功能描述 |
|---|---|---|
| 数据读取/存储 | read_csv() | 从 CSV 文件读取数据 |
read_excel() | 从 Excel 文件读取数据 | |
to_csv() | 将数据保存为 CSV 文件 | |
| 数据查看/检查 | head() | 查看数据前几行 |
tail() | 查看数据后几行 | |
info() | 显示数据摘要(列、数据类型等) | |
describe() | 生成数值型数据的统计摘要 | |
| 数据选择/过滤 | loc[] | 基于标签选择数据 |
iloc[] | 基于整数位置选择数据 | |
query() | 使用表达式筛选数据 | |
| 数据处理 | dropna() | 删除缺失值 |
fillna() | 填充缺失值 | |
groupby() | 数据分组聚合 | |
merge() | 合并多个 DataFrame | |
sort_values() | 按列值排序 | |
| 数据转换 | apply() | 对数据应用自定义函数 |
pivot_table() | 创建透视表 | |
melt() | 将宽格式数据转换为长格式 | |
| 时间序列处理 | to_datetime() | 将字符串转换为时间格式 |
resample() | 时间序列重采样 |
pandas 广泛应用于金融、统计、机器学习等领域,是 Python 数据分析生态系统的核心工具之一。pandas 通常与 NumPy、Matplotlib、Scikit-learn 等库配合使用,构成 Python 数据科学生态的核心工具链。
2.入门
已经安装了 Python 和 PIP,安装Pandas:C:\Users\Your Name>pip install pandas
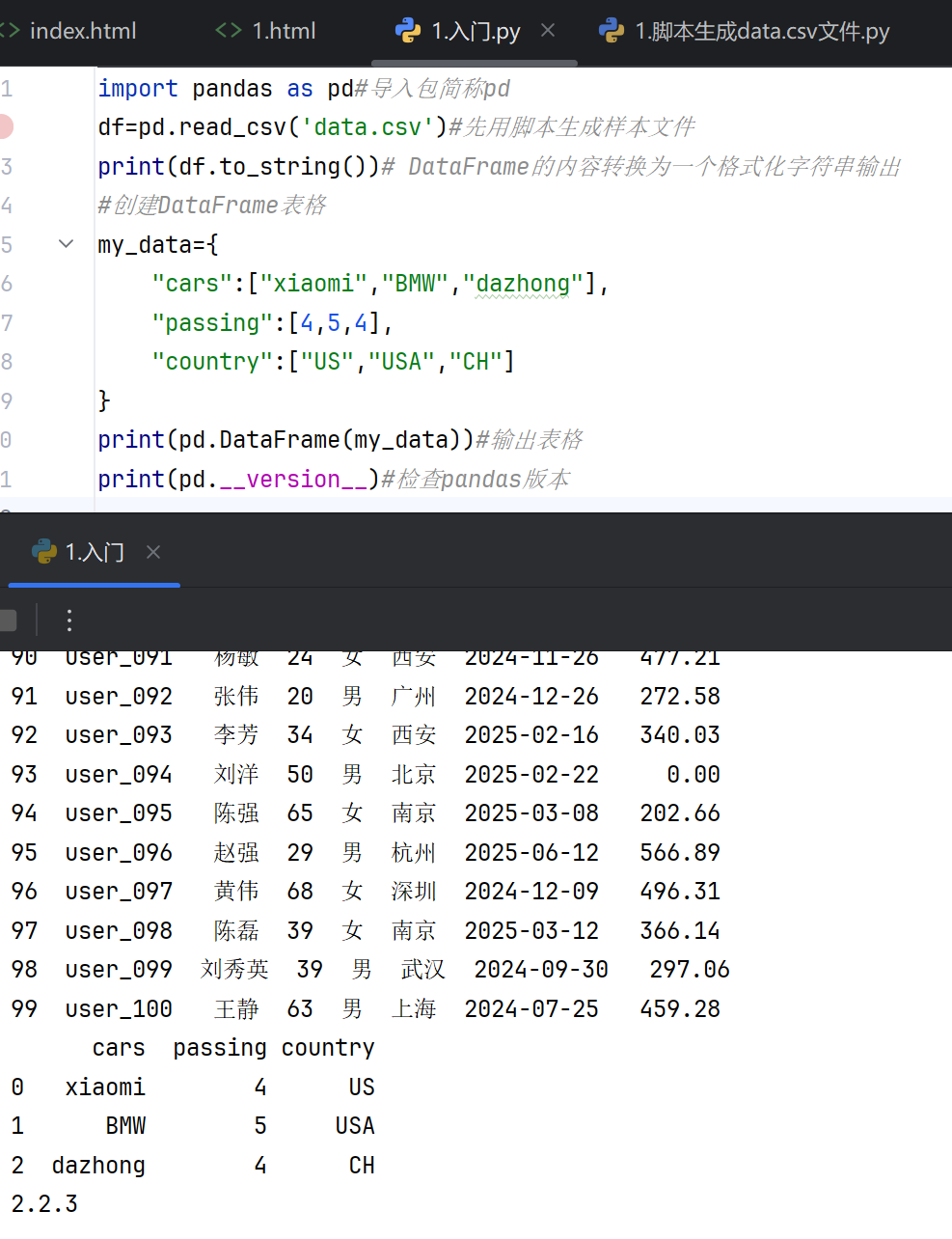
3.序列(Series)
pandas序列简介
- 数据清洗与预处理
- 探索性数据分析(EDA)
- 机器学习特征工程
- 金融、社会科学等领域的时间序列分析
pandas中的Series是一种一维标记数组,能够存储任何数据类型(整数、字符串、浮点数、Python对象等)。每个元素都有对应的索引标签,默认情况下为从0开始的整数索引,但也可以自定义索引。
核心特性
索引与数据对齐:Series会自动对齐不同索引的数据,便于后续操作。 数据类型多样性:支持多种数据类型,包括数值、字符串、布尔值等。 向量化操作:支持基于标签的数学运算,无需显式循环。
常用函数
数据操作类
统计计算类
数据清洗类
索引与选择类
转换类
Series是pandas的基础数据结构之一,通常与DataFrame结合使用,适合处理表格数据中的单列或单行操作。
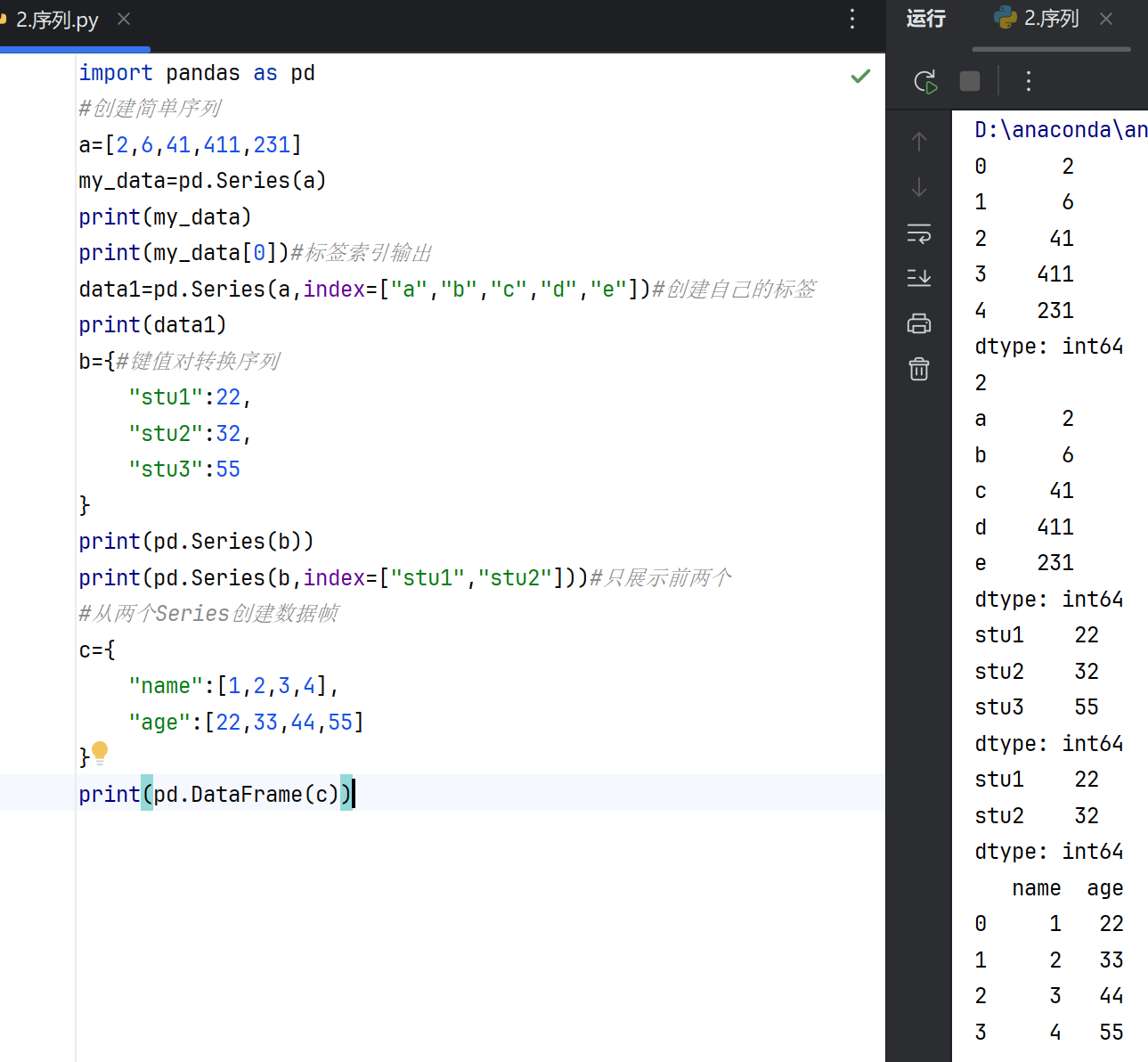
4.数据帧(DataFrame)
head()/tail():查看序列前/后几行数据。unique():返回序列中的唯一值数组。value_counts():统计每个唯一值的出现次数。sort_values():按值排序序列。sort_index():按索引排序序列。mean()/median():计算均值或中位数。sum()/prod():求和或乘积。isna()/notna():检测缺失值(返回布尔序列)。fillna():填充缺失值。dropna():删除包含缺失值的项。loc[]:通过标签索引访问数据。iloc[]:通过整数位置索引访问数据。get():安全获取索引对应的值(避免KeyError)。astype():强制转换数据类型。to_list()/to_dict():转换为Python列表或字典。apply():对每个元素应用自定义函数。std()/var():计算标准差或方差。min()/max():获取最小值或最大值。
pandas DataFrame 简介
DataFrame 是 pandas 库中的核心数据结构,用于处理结构化数据。它类似于电子表格或 SQL 表,由行和列组成,列可以是不同的数据类型(如整数、字符串、浮点数等)。DataFrame 提供了高效的数据操作和分析功能,是数据科学和机器学习中常用的工具。
DataFrame 的核心特点
二维表格结构:DataFrame 是一个带有行索引和列名的二维表格,可以方便地存储和操作数据。 灵活的数据类型:每一列可以包含不同类型的数据(数值、字符串、布尔值等)。 强大的数据操作:支持数据筛选、合并、分组、聚合、排序等高级操作。 与外部数据集成:可以轻松读取和写入 CSV、Excel、SQL 数据库等多种数据源。
常用 DataFrame 函数
DataFrame 的设计使其成为处理结构化数据的理想选择,适用于数据分析、数据清洗和机器学习等任务。
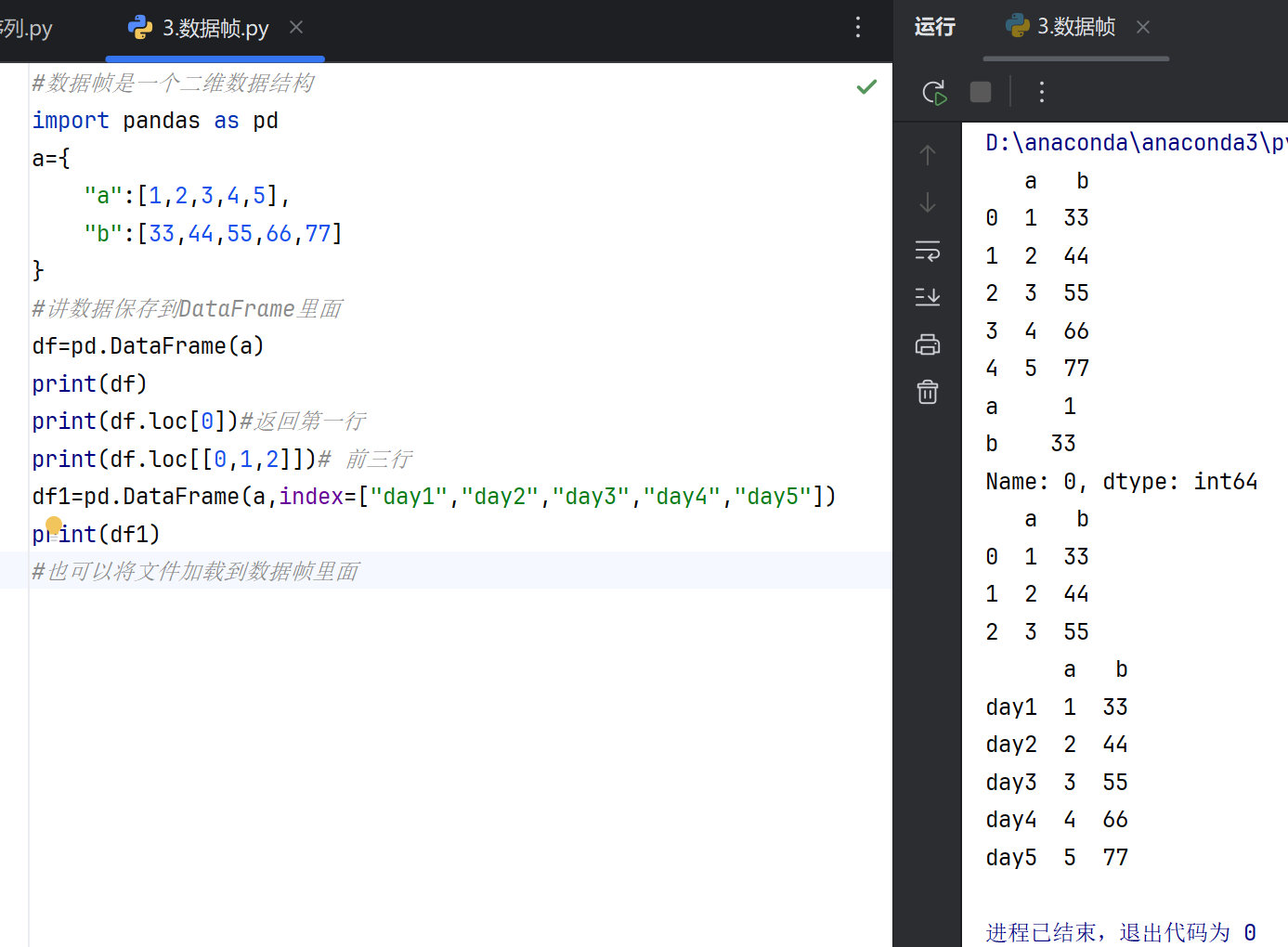
5.读取csv文件
- 数据查看:
head()查看前几行,tail()查看后几行,info()显示数据概要。 - 数据选择:
loc[]按标签选择数据,iloc[]按位置选择数据。 - 数据清洗:
dropna()删除缺失值,fillna()填充缺失值,drop()删除行或列。 - 数据计算:
mean()计算平均值,sum()求和,groupby()分组计算。 - 数据排序:
sort_values()按值排序,sort_index()按索引排序。 - 数据合并:
merge()合并多个 DataFrame,concat()连接多个 DataFrame。
pandas读取CSV文件的主要函数
pandas.read_csv() 是用于读取CSV(逗号分隔值)文件的核心函数,支持多种参数以适应不同格式的数据文件。
函数的关键参数及含义
filepath_or_buffer
指定文件路径或URL,可以是本地文件系统路径或网络地址,支持字符串或文件对象。
sep/delimiter
定义字段分隔符,默认为逗号(,)。可自定义为制表符(\t)、分号(;)等其他字符。
header
指定表头行位置,默认为0(第一行作为列名)。设为None时表示无表头,自动生成数字列名。
index_col
将某一列设为行索引,支持列名或列位置编号。多级索引可传入列名列表。
names
自定义列名列表,覆盖文件中的原有列名。需与数据列数一致。
dtype
强制指定列的数据类型,传入字典格式(如{'列名': 'float64'})可优化内存或避免自动推断错误。
na_values
指定哪些字符串应被识别为缺失值(NaN),支持单个字符串或列表(如['NA', 'NULL'])。
skiprows
跳过文件开头指定行数或行号列表(如跳过注释行)。
nrows
仅读取前N行数据,适用于快速检查大型文件。
encoding
指定文件编码格式(如utf-8、gbk),解决中文等非ASCII字符乱码问题。
parse_dates
将指定列解析为日期类型,支持列名列表或True(自动尝试转换日期列)。
其他实用功能
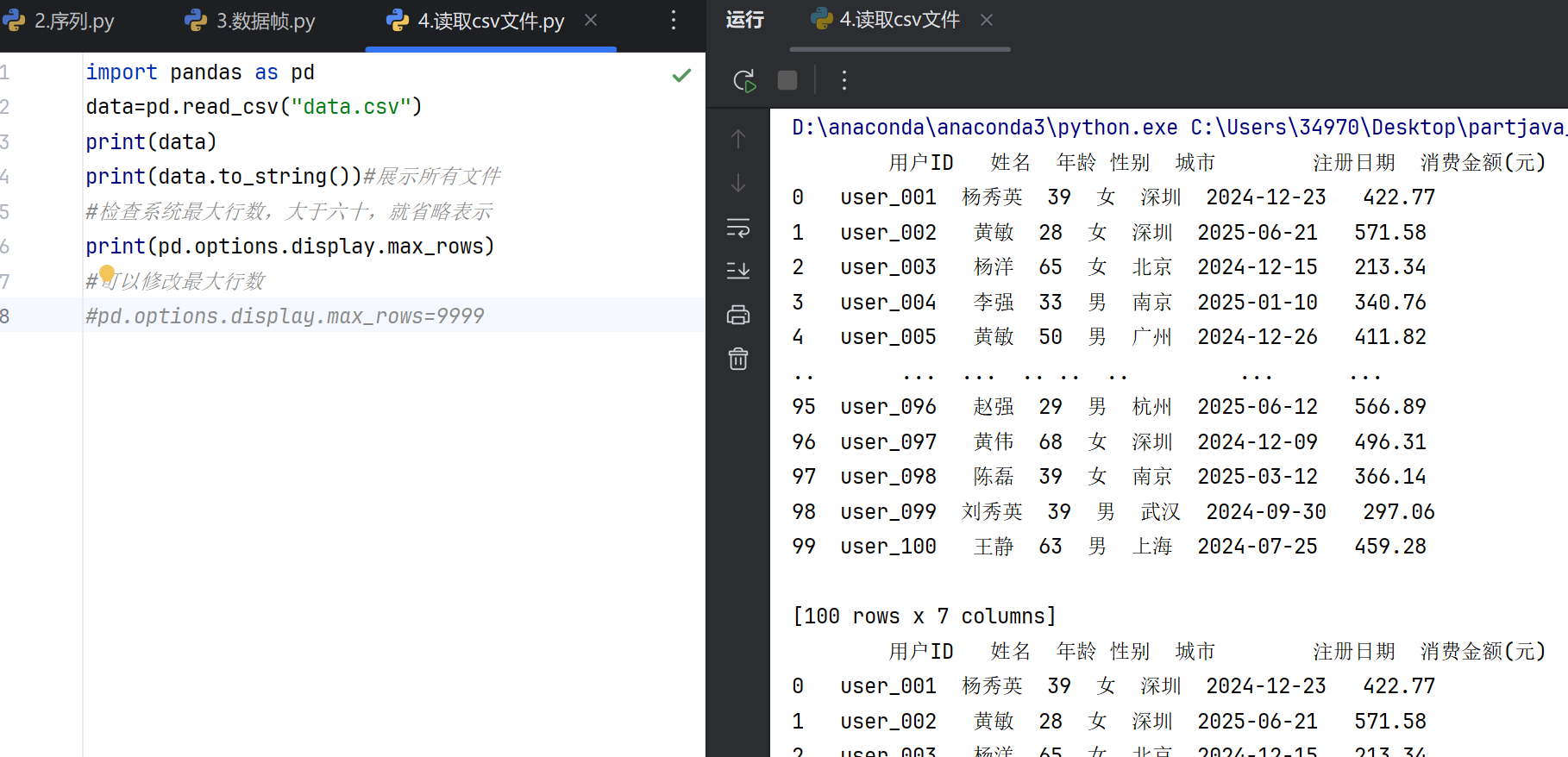
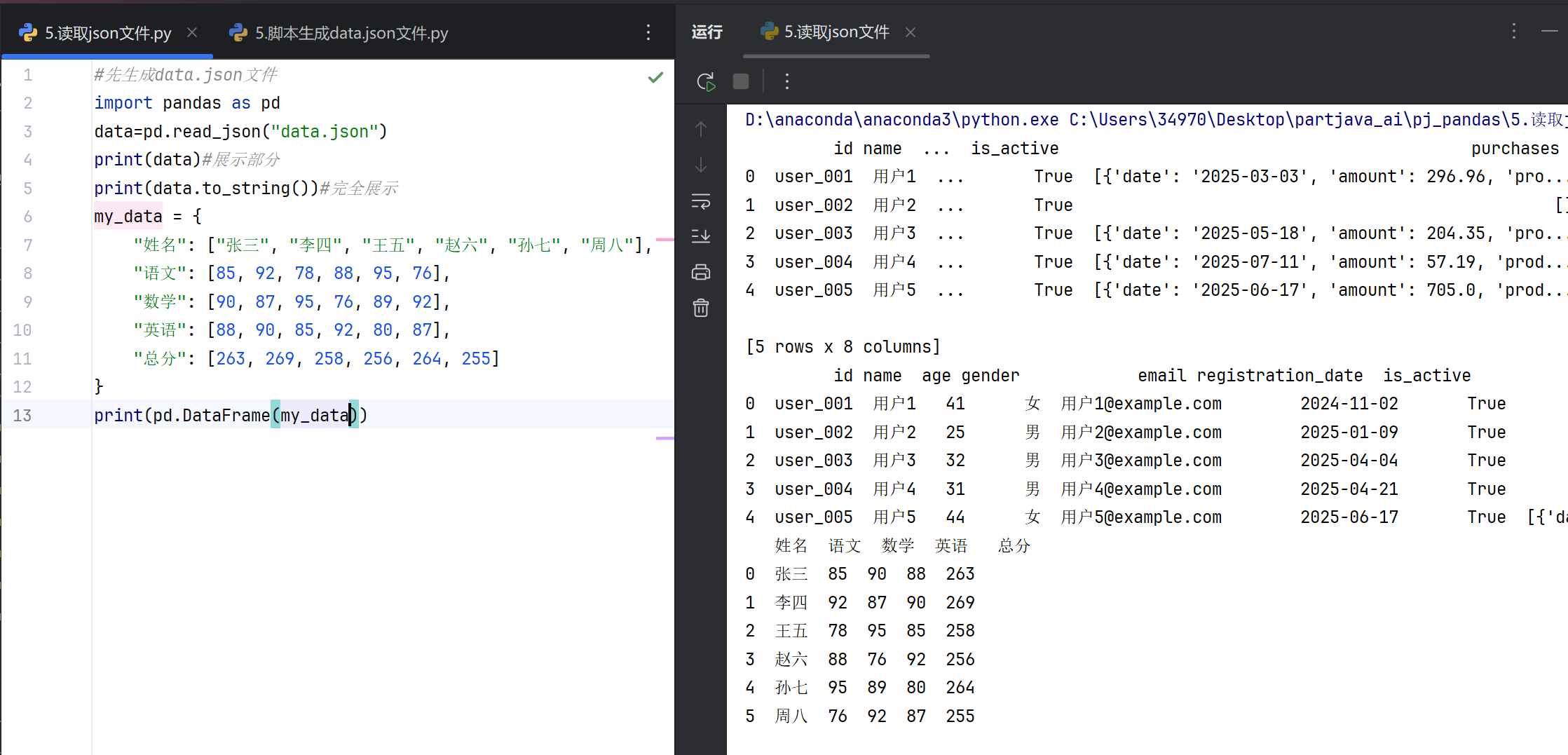
6.读取json
- 日期解析:通过
parse_dates参数可合并多列为单个日期列(如年、月、日分列时)。 - 分块读取:
chunksize参数支持迭代读取大型文件,减少内存占用。 - 压缩文件:自动识别
.gz、.zip等压缩格式,无需提前解压。
JSON 的含义
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,采用文本形式存储和传输数据。其结构由键值对组成,兼容多种编程语言,常用于Web应用、API数据传输和配置文件存储。JSON支持嵌套结构,可表示复杂数据关系。
Pandas 中的 JSON 相关函数
read_json():将 JSON 格式的数据转换为 Pandas 的 DataFrame 对象。支持从文件路径、URL 或 JSON 字符串读取数据,可自动解析嵌套结构。参数 orient 用于指定 JSON 数据的排列方式(如 'records'、'columns')。
to_json():将 DataFrame 或 Series 转换为 JSON 格式的字符串或文件。通过 orient 参数控制输出结构(如 'split'、'index'),date_format 参数可调整时间序列的格式化方式。
json_normalize():用于展平嵌套的 JSON 数据,将其转换为扁平的 DataFrame。适用于处理包含多层嵌套的复杂 JSON 结构,如 API 返回的嵌套响应。参数 record_path 指定展开的路径,meta 定义保留的元字段。
JSON 结构的常见形式
7.数据分析
- 键值对集合:类似 Python 字典,如
{"name": "Alice", "age": 25}。 - 列表结构:表示有序数据,如
[1, 2, 3]。 - 混合嵌套:键值对中嵌套列表或其他字典,适合表示层次化数据。
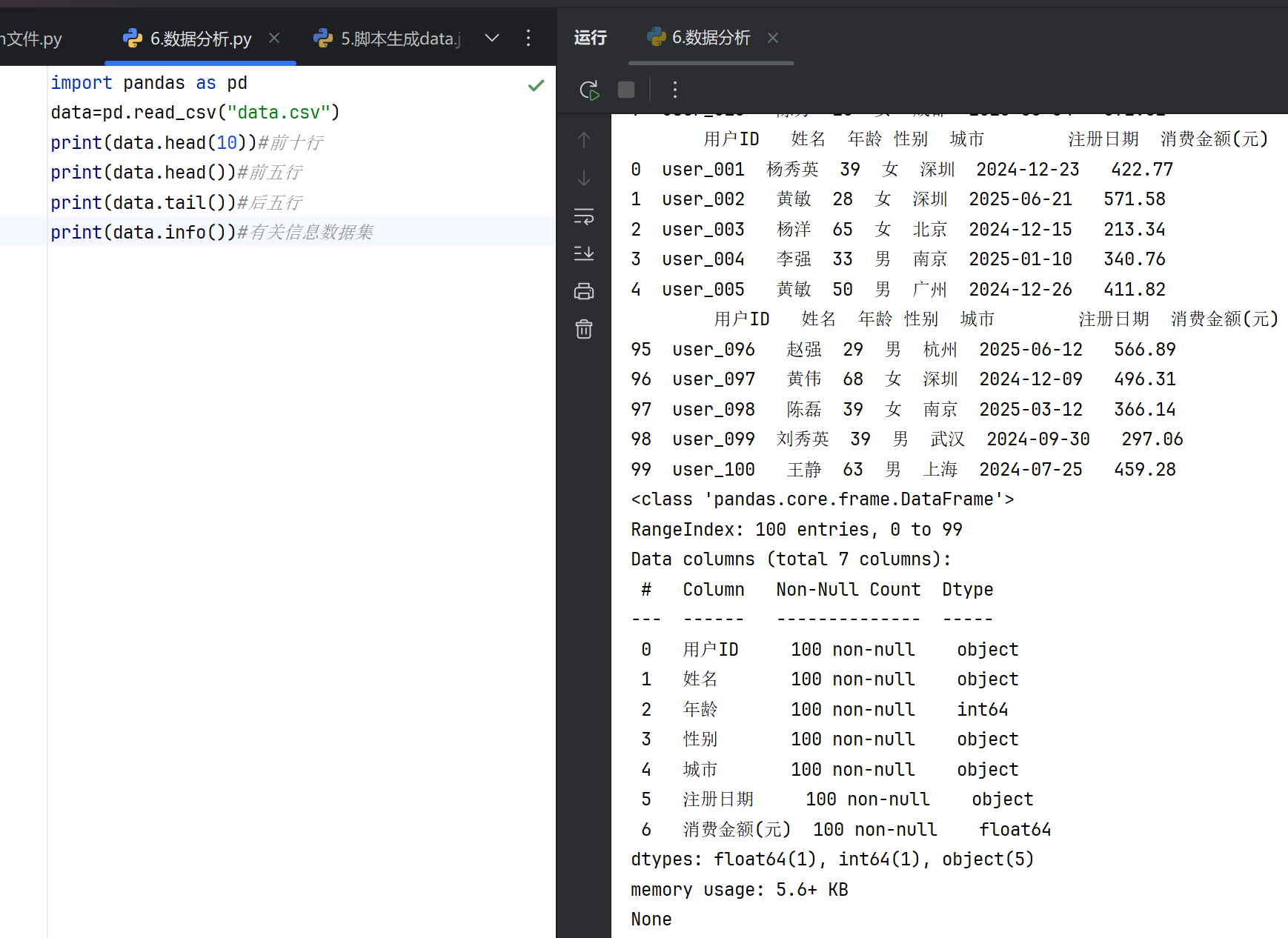
pandas 数据分析简介
pandas 是一个强大的 Python 数据分析库,提供了高效的数据结构和工具,用于处理和分析结构化数据。其核心数据结构是 DataFrame(二维表格数据)和 Series(一维数据),支持多种数据操作和分析功能。
主要数据分析功能
数据读取与查看
读取数据:支持从 CSV、Excel、SQL、JSON 等格式加载数据,常用函数如 read_csv()、read_excel()。 查看数据:head() 显示前几行数据,tail() 显示后几行数据,info() 提供数据概览(如列名、数据类型、非空值数量)。
数据清洗
数据筛选与排序
数据聚合与分组
描述性统计
数据合并与重塑
时间序列分析
常用分析场景
pandas 的函数设计注重简洁性和表达力,能够高效处理大规模数据,是数据科学领域的核心工具之一。
8.数据清洗
- 处理缺失值:
isnull()检测缺失值,dropna()删除缺失值,fillna()填充缺失值。 - 去重:
drop_duplicates()删除重复行。 - 数据类型转换:
astype()修改列的数据类型。 - 条件筛选:通过布尔索引选择满足条件的数据。
- 列选择:通过列名或标签选择特定列。
- 排序:
sort_values()按某列的值排序,sort_index()按索引排序。 - 分组统计:
groupby()对数据进行分组,结合聚合函数(如sum()、mean())计算统计量。 - 透视表:
pivot_table()创建类似 Excel 的透视表,支持多维数据分析。 - 汇总统计:
describe()提供数值列的统计摘要(如均值、标准差、分位数)。 - 相关性分析:
corr()计算列之间的相关系数。 - 合并数据:
merge()类似 SQL 的 JOIN 操作,concat()沿轴拼接多个 DataFrame。 - 重塑数据:
melt()将宽格式数据转换为长格式,pivot()将长格式数据转换为宽格式。 - 时间数据处理:支持日期解析、时间偏移、滚动窗口统计等。
- 重采样:
resample()对时间序列数据进行降采样或升采样。 - 探索性数据分析(EDA):通过统计和可视化快速理解数据分布和关系。
- 数据预处理:清理和转换数据,为建模或分析做准备。
- 业务分析:计算关键指标(如转化率、留存率),生成报表。
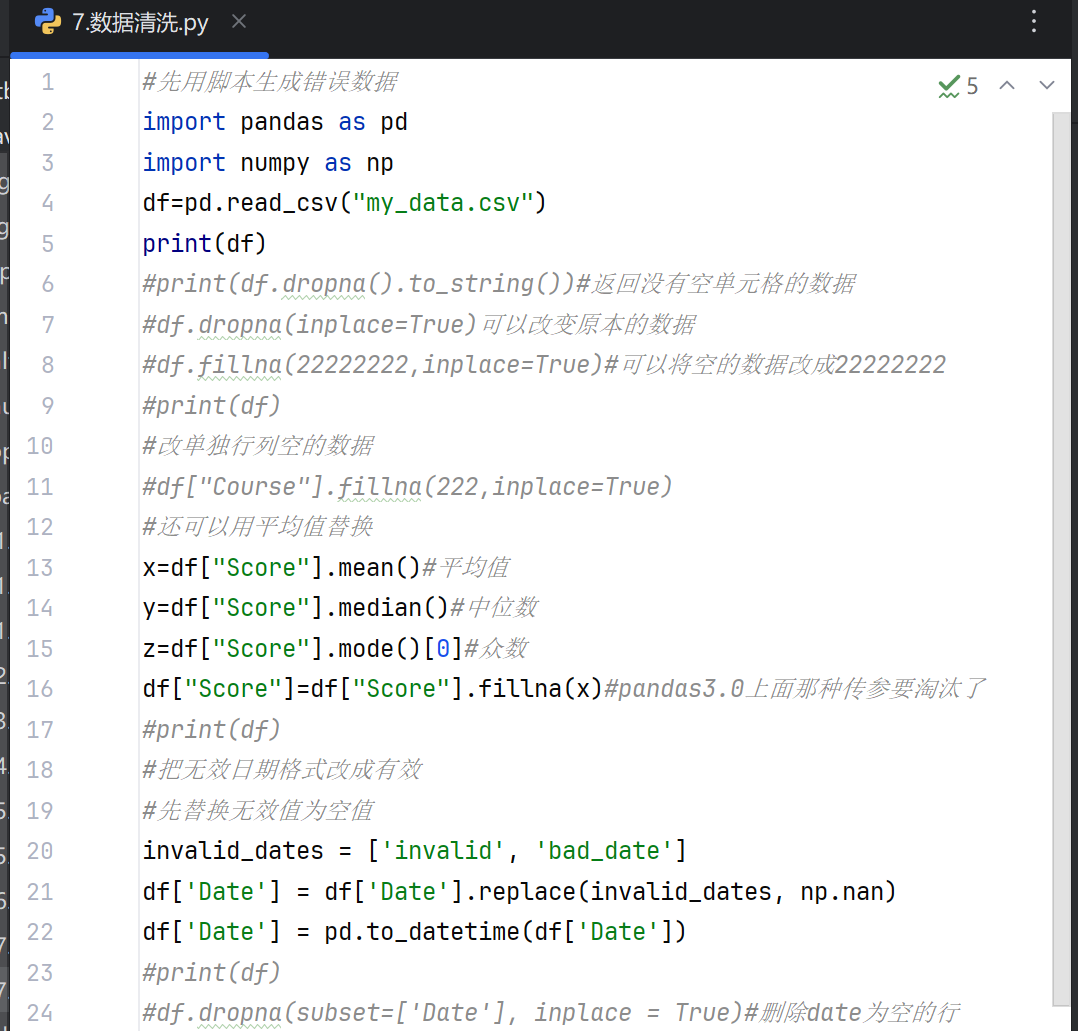
pandas数据清洗概述
数据清洗是数据分析的关键步骤,旨在处理数据集中的错误、缺失、重复或不一致问题,确保数据质量。pandas作为Python的核心数据分析库,提供了丰富的函数和方法支持高效清洗。
常用数据清洗场景
缺失值处理
识别缺失值:isnull()或isna()检测缺失值,返回布尔值。 填充缺失值:fillna()用指定值或插值方法填充。 删除缺失值:dropna()移除包含缺失值的行或列。
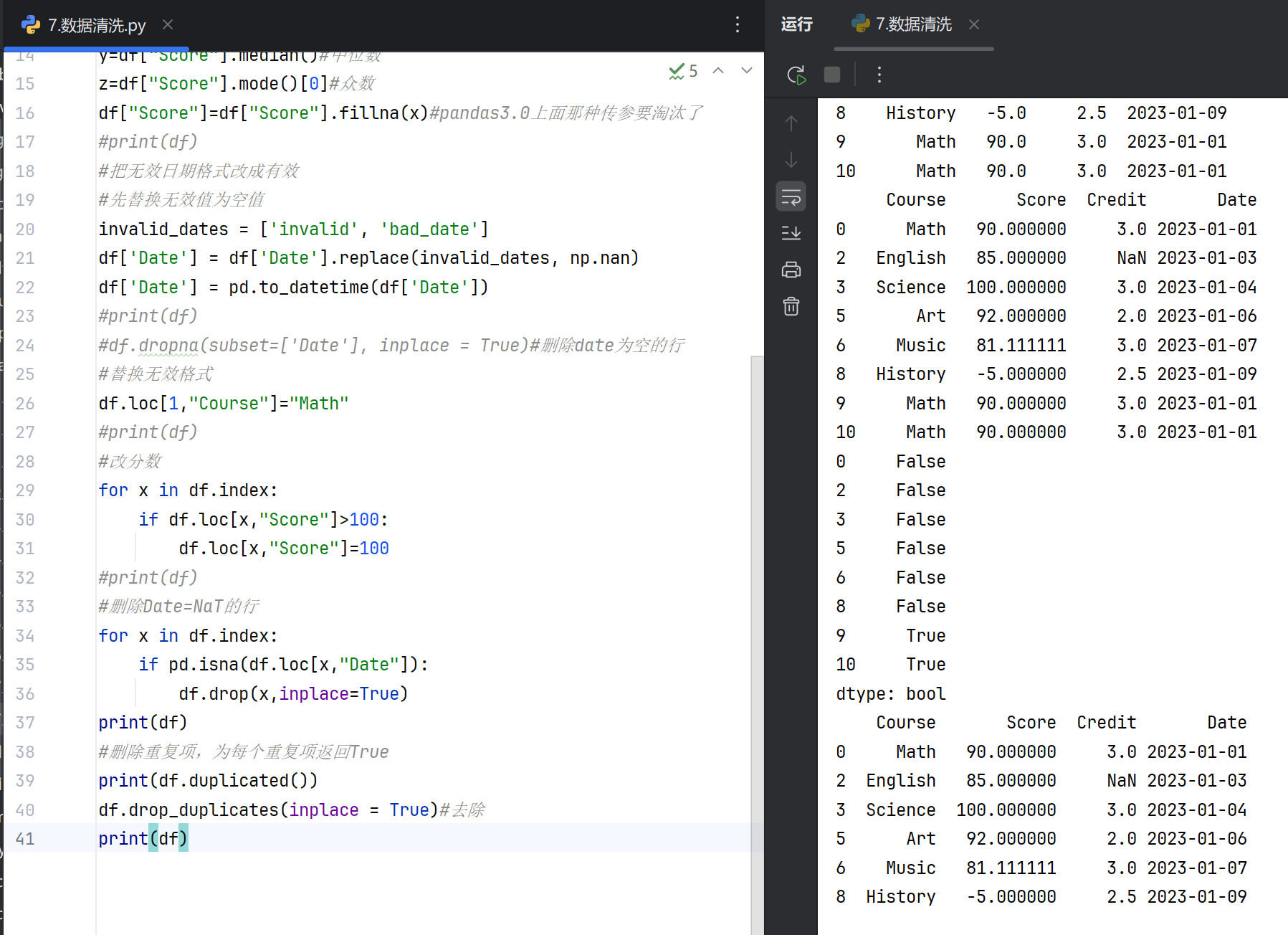
重复数据处理
数据类型转换
异常值处理
字符串处理
数据规范化
核心函数功能说明
数据清洗需结合业务场景选择合适方法,通常需要多次迭代才能达到理想效果。
 9.绘图
9.绘图
- 检测重复行:
duplicated()标记重复行。 - 删除重复行:
drop_duplicates()移除重复记录,可基于部分或全部列。 - 类型转换:
astype()将列转换为指定数据类型。 - 日期转换:
to_datetime()将字符串转为日期格式。 - 描述统计:
describe()快速识别数值异常。 - 条件筛选:通过布尔索引过滤不合理值。
- 大小写转换:
str.lower()/str.upper()统一文本格式。 - 标准化/归一化:通过数学变换使数据符合特定范围。
- 分箱处理:
cut()/qcut()将连续值离散化。 isnull():生成缺失值掩码,便于定位问题数据。fillna():支持前向填充、均值填充等多种缺失值填补策略。drop_duplicates():通过keep参数控制保留首个或末个重复项。replace():支持值映射或正则表达式替换。apply():支持自定义函数进行复杂清洗操作。merge()/join():处理多表数据不一致问题。- 空白处理:
str.strip()清除首尾空格。 - 文本替换:
str.replace()替换特定字符或模式。
pandas绘图概述
pandas内置的绘图功能基于Matplotlib,提供了快速可视化数据的能力。通过DataFrame和Series对象直接调用绘图方法,可以简化常见图表(如折线图、柱状图、散点图等)的生成流程,适合探索性数据分析(EDA)。
主要绘图函数及含义
DataFrame.plot() :功能:通用绘图入口,通过参数指定图表类型(如折线图、柱状图等)。 关键参数:
kind:图表类型(如line、bar、hist等)。x/y:指定横纵轴数据列。title:图表标题。grid:是否显示网格线。
DataFrame.plot.line()
DataFrame.plot.bar() / DataFrame.plot.barh()
DataFrame.plot.hist()
DataFrame.plot.box()
DataFrame.plot.scatter()
DataFrame.plot.pie()
其他功能
pandas绘图方法适合快速生成基础图表,复杂定制仍需结合Matplotlib或Seaborn库。
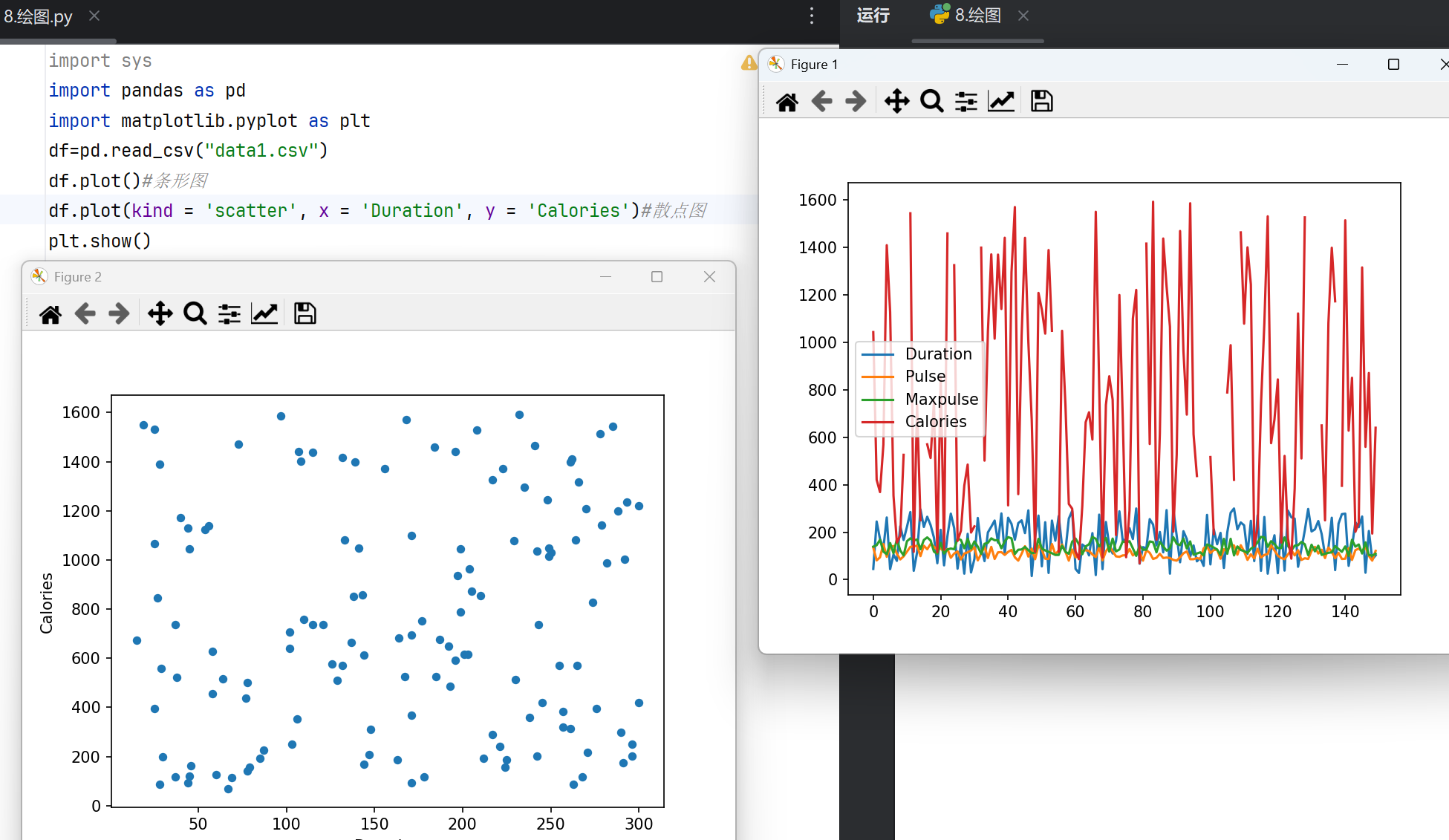
- 用途:绘制折线图,适合展示数据随时间或有序变量的趋势变化。
- 适用场景:时间序列数据、连续变量对比。
- 用途:垂直/水平柱状图,用于分类数据对比。
- 关键参数:
stacked:是否堆叠显示不同分类。
- 用途:直方图,展示数值数据的分布情况。
- 关键参数:
bins:控制分箱数量,影响分布细节。
- 用途:箱线图,显示数据的中位数、四分位数及异常值。
- 适用场景:分析数据离散程度和离群值。
- 用途:散点图,展示两个数值变量的相关性。
- 用途:饼图,显示各类别占比关系。
- 注意点:适用于少量类别,避免过多分割导致可读性下降。
- 子图绘制:通过
subplots=True参数可拆分多列数据到不同子图。 - 样式定制:支持Matplotlib的样式参数(如颜色、线型、标签等),需通过
plt接口进一步调整。 - 关键参数:
x/y:指定横纵轴列名。c:基于某列数值的颜色映射。

















 817
817

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









