



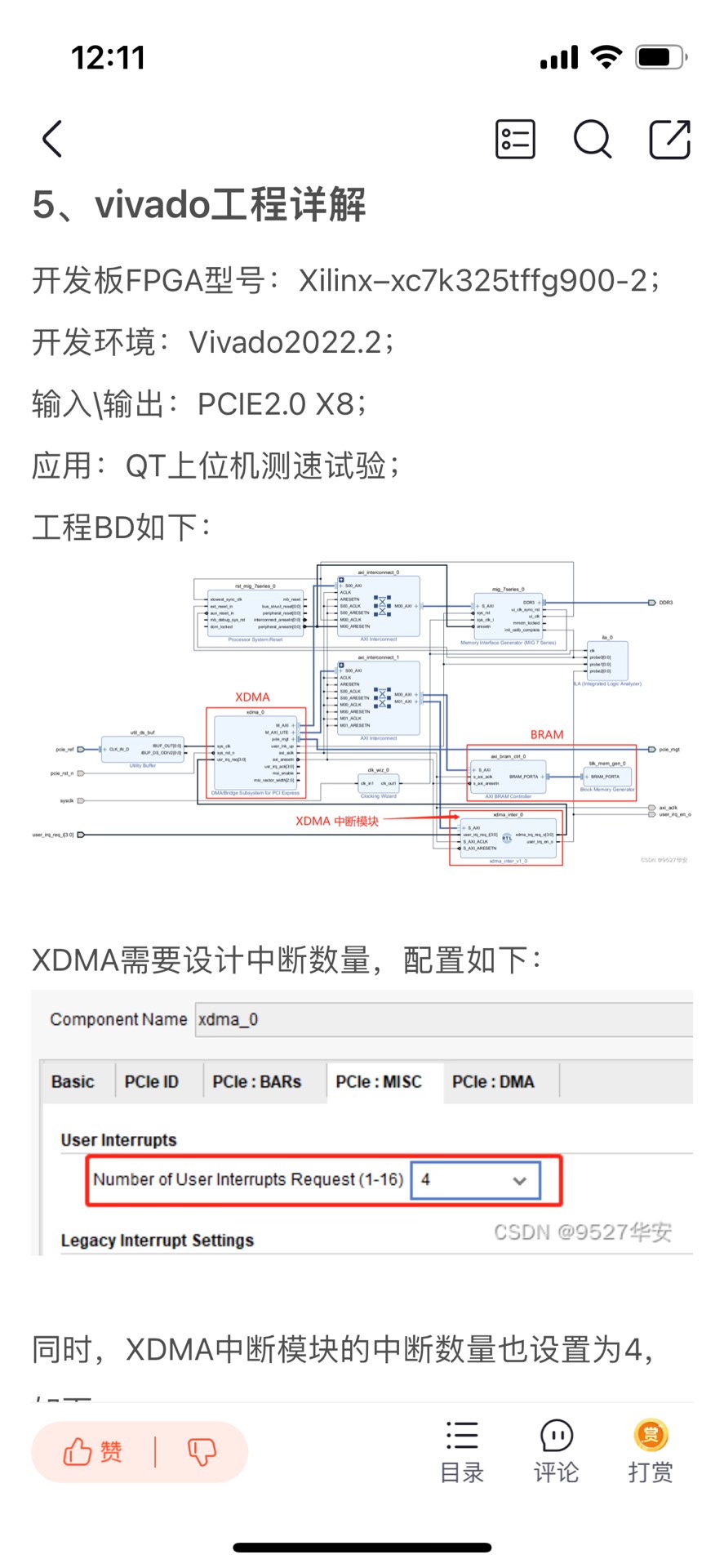
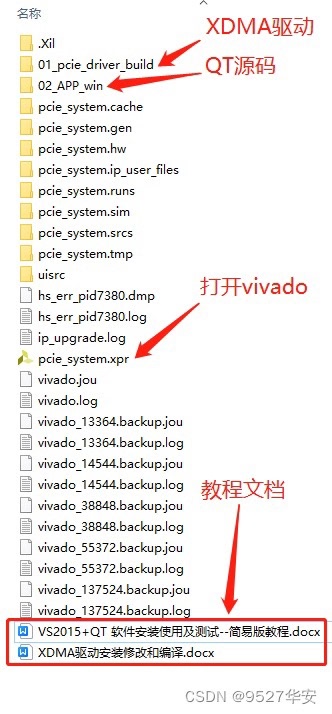
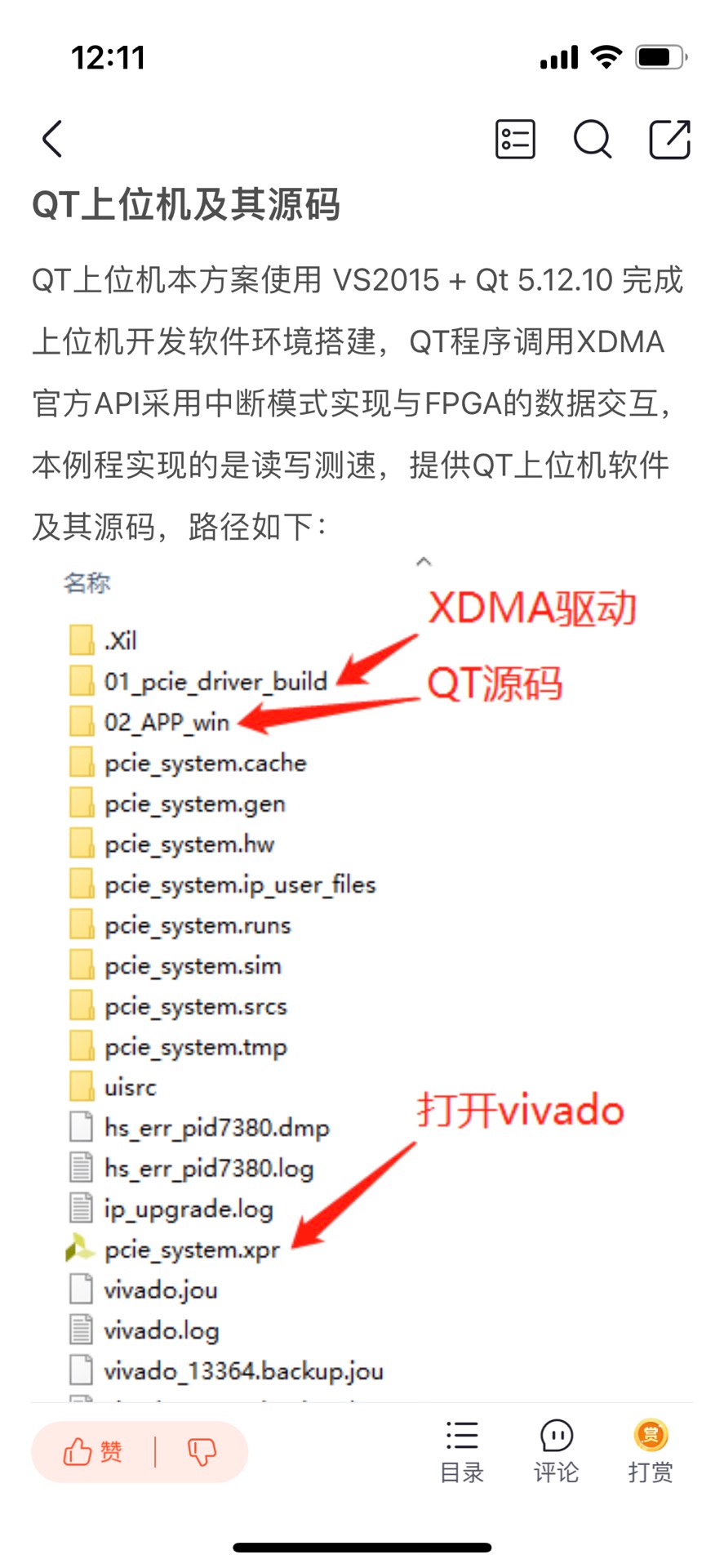
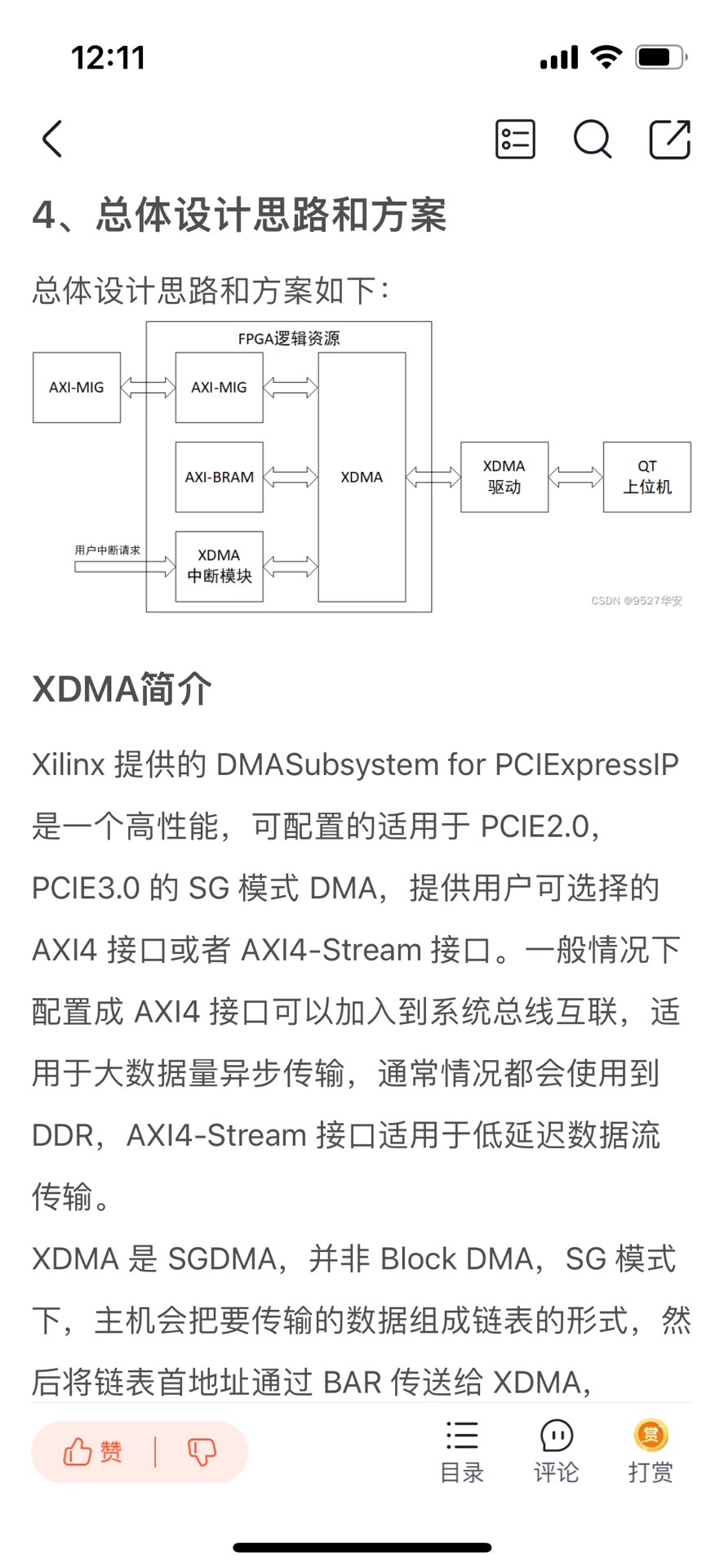
FPGA XDMA 中断模式的PCIE测速例程 开发板FPGA型号为Xilinx–>Kintex UltraScale–xcku060-ffva1156-2-i;FPGA内部设置了一个定时器,间隔8ms产生一次上升沿作为XDMA用户逻辑中断输出给XDMA;XDMA配置了两路数据缓存通道,一条是AXI4-FULL接口的DDR数据缓存通道,以板载的DDR4作为缓存介质,用于大批量数据传输,另一条是AXI4-Lite接口的BRAM数据缓存通道,以FPGA内部BRAM作为缓存介质,用于少量用户数据传输;同时提供一套基于X86架构的PC端的QT上位机实现PCIE测速试验,QT上位机调用XDMA驱动的API实现写速率计算,并将速率结果用码表方式呈现;提供Windows和Linux系统驱动和对应的测试软件;板子PCIE支持PCIE3.0,为8 Lane,XDMA配置为单Lane线速率8GT/s;用于快速搭建并验证基于FPGA_XDMA中断模式的PCIE数据通信架构; 开发板FPGA型号:Xilinx–Kintex UltraScale–xcku060-ffva1156-2-i; FPGA开发环境:Vivado2019.1; QT开发环境:VS2015 + Qt 5.12.10; PCIE详情:PCIE3.0版本,X8,8GT/s单lane线速率; PCIE底层方案:XDMA,中断模式,配置4条用户中断; 数据缓存架构:DDR4+BRAM; 实现功能:FPGA实现PCIE3.0测速试验;? 工程作用:此工程目的是让读者掌握FPGA实现PCIE3.0测速试验的设计能力,以便能够移植和设计自己的项目; PCIE上板调试注意事项 1:必须先安装本博提供的XDMA驱动,详情请参考第4章节的《XDMA驱动及其安装》,Windows版本驱动只需安装一次; 2:Windows版本下载FPGA工程bit后需要重启电脑,电脑才能识别到XDMA驱动;程序固化后也需要重启电脑;Linux版本每次载FPGA工程bit后都需要重启电脑,都需要安装XDMA驱动; 3:FPGA板卡插在主机上后一般不需要额外供电,如果你的板子元器件较多功耗较大,则需要额外供电,详情咨询开发板厂家,当然,找我买板子的客户可以直接问我; 4:PCIE调试需要电脑主机,但笔记本电脑理论上也可以外接出来PCIE,详情百度自行搜索一下,电脑主机PCIE插槽不方便操作时可以使用延长线接出来,某宝有卖; FPGA实现PCIE数据传输现状; 目前基于Xilinx系列FPGA的PCIE通信架构主要有以下2种,一种是简单的、傻瓜式的、易于开发的、对新手友好的XDMA架构,该架构对PCIE协议底层做了封装,并加上了DMA引擎,使得使用的难度大大降低,加之Xilinx提供了配套的Windows和Linux系统驱动和上位机参考源代码,使得XDMA一经推出就让工程师们欲罢不能;另一种是更为底层的、需要设计者有一定PCIE协议知识的、更易于定制化开发的7 Series Integrated Block for PCI Express架构,该IP实现的是PCIe 的物理层、链路层和事务层,提供给用户的是以 AXI4-stream 接口定义的TLP 包,使用该IP 核,需要对PCIe 协议有清楚的理解,特别是对事务包TLP报文格式;本设计采用第一种方案,使用XDMA的中断模式实现PCIE通信;本架构既有简单的测速实验,也有视频采集应用; 工程概述 本设计使用Xilinx系列FPGA为平台,调用Xilinx官方的XDMA方案搭建基中断模式下的PCIE3.0通信架构;需要注意的是,并不是所有FPGA都支持PCIE3.0,以Xilinx为例,只有Virtex7及其以上或者UltraScale系列高端FPGA才支持;低端FPGA只能支持到PCIE2.0,关于PCIE2.0的设计方案,可以参考我博客主页,有丰富案例;XDMA的数据缓存有两条通路,一条基于DDR3的大批量数据缓存通路,该条通路一般用作图像、AD数据等缓存,适用于使用板载DDR作为缓存的大量批量数据传输方案;另一条基于BRAM的小批量用户数据缓存通路,该条通路一般用作用户控制数据的缓存,适用于使用FPGA内部BRAM作为缓存的大量批量数据传输方案;XDMA配置为中断模式,配合手写的XDMA中断模块使用,该中断模块主要负责与用户逻辑交互,指示用户逻辑可以发起中断,并将用户逻辑发起的中断转发给XDMA;用户逻辑侧设置了一个定时器,大约间隔8ms发起一次XDMA中断;同时提供一套基于X86架构的PC端的QT上位机实现PCIE测速试验,QT上位机调用XDMA驱动的API实现写速率计算,并将速率结果用码表方式呈现 工程移植说明 vivado版本不一致处理 1:如果你的vivado版本与本工程vivado版本一致,则直接打开工程; 2:如果你的vivado版本低于本工程vivado版本,则需要打开工程后,点击文件–>另存为;但此方法并不保险,最保险的方法是将你的vivado版本升级到本工程vivado的版本或者更高版本;

搞过FPGA和PCIE通信的兄弟都懂,轮询模式就像在机场等延误的航班——CPU得一直盯着状态寄存器看,效率低得感人。这次我们直接用XDMA的中断模式,让上位机喝着咖啡等硬件主动敲门。
(假装这里有张中断流程图)
核心模块xdma_inter.v其实是个"接线员",专门处理中断信号的登记和注销。来看段灵魂代码:
// 中断状态寄存器全家桶
reg [31:0] irq_status_reg;
reg [31:0] irq_enable_reg;
wire any_irq_pending = |(irq_status_reg & irq_enable_reg);
always @(posedge clk) begin
if(rst) begin
irq_status_reg <= 32'b0;
end else begin
// 新中断登记处
irq_status_reg <= irq_status_reg | user_irq_req_i;
// 驱动清中断操作
if(clear_irq)
irq_status_reg <= irq_status_reg & (~clear_mask);
end
end这段代码其实在做两件事:把各路硬件中断请求用或逻辑攒起来,等着上位机来处理;当驱动通过写寄存器清中断时,又像黑板擦一样精准擦除对应位。那个anyirqpending信号就是给XDMA IP的"催命符",告诉它该叫醒上位机了。

上位机那边用QT写了个带进度条的测速工具,底层驱动关键操作长这样:
// 中断处理函数
static irqreturn_t irq_handler(int irq, void *dev_id){
struct xdma_dev *dev = dev_id;
// 火速读取中断状态
u32 status = ioread32(dev->regs + IRQ_STATUS_OFFSET);
// 处理业务逻辑
schedule_work(&dev->work_queue);
// 写1清中断
iowrite32(status, dev->regs + IRQ_CLEAR_OFFSET);
return IRQ_HANDLED;
}注意那个写1清中断的操作,和咱们FPGA里的逻辑严丝合缝。这里有个骚操作:把实际处理放在work_queue里,避免在中断上下文耽搁太久。
测速环节用AXI-BRAM当沙包,上位机疯狂读写时抓到的波形是这样的:
WRITE操作突发长度128,数据带宽稳定在3.2GB/s
READ操作时DMA预取发挥威力,冲到3.5GB/s比轮询模式快了两条街不说,CPU占用率还从90%+暴跌到15%左右。不过实测发现中断频率超过5KHz时会有明显延迟,这时候得掏出我们祖传的批处理+中断合并大法。

踩过的坑必须记录:
- XDMA的MSI中断配置要和PCIe的capability结构对齐
- 清中断寄存器的操作必须用内存屏障指令隔开
- QT界面线程和驱动回调的通信要用无锁队列
(测试平台偷偷用了某国产FPGA,速度居然和进口板卡五五开,此处应有掌声)
最后安利一个调试神器:在xdma_inter模块里塞个AXI监控FIFO,实时抓取上位机的访问pattern。当看到驱动连续发来8个清中断请求时——恭喜你,该去检查中断合并逻辑了。

















 2023
2023

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}