




前言
昨天在介绍Center Loss的时候提到了这两个损失函数,今天就来介绍一下。Contrastive Loss是来自Yann LeCun的论文Dimensionality Reduction by Learning an Invariant Mapping,目的是增大分类器的类间差异。而Triplet Loss是在FaceNet论文中的提出来的,原文名字为:FaceNet: A Unified Embedding for Face Recognition and Clustering,是对Contrastive Loss的改进。接下来就一起来看看这两个损失函数。论文原文均见附录。
问题引入
假设我们现在有2张人脸图片,我们要进行一个简单的对比任务,就是判断这两张人脸图片是不是对应同一个人,那么我们一般会如何解决?一种简单直接的思路就是提取图片的特征向量,然后去对比两个向量的相似度。但这种简单的做法存在一个明显的问题,那就是CNN提取的特征“类间”区分性真的有那么好吗?昨天我们了解到用SoftMax损失函数训练出的分类模型在Mnist测试集上就表现出“类间”区分边界不大的问题了,使得遭受对抗样本攻击的时候很容易就分类失败。况且人脸识别需要考虑到样本的类别以及数量都是非常多的,这无疑使得直接用特征向量来对比更加困难。
Contrastive Loss
针对上面这个问题,孪生网络被提出,大致结构如下所示:
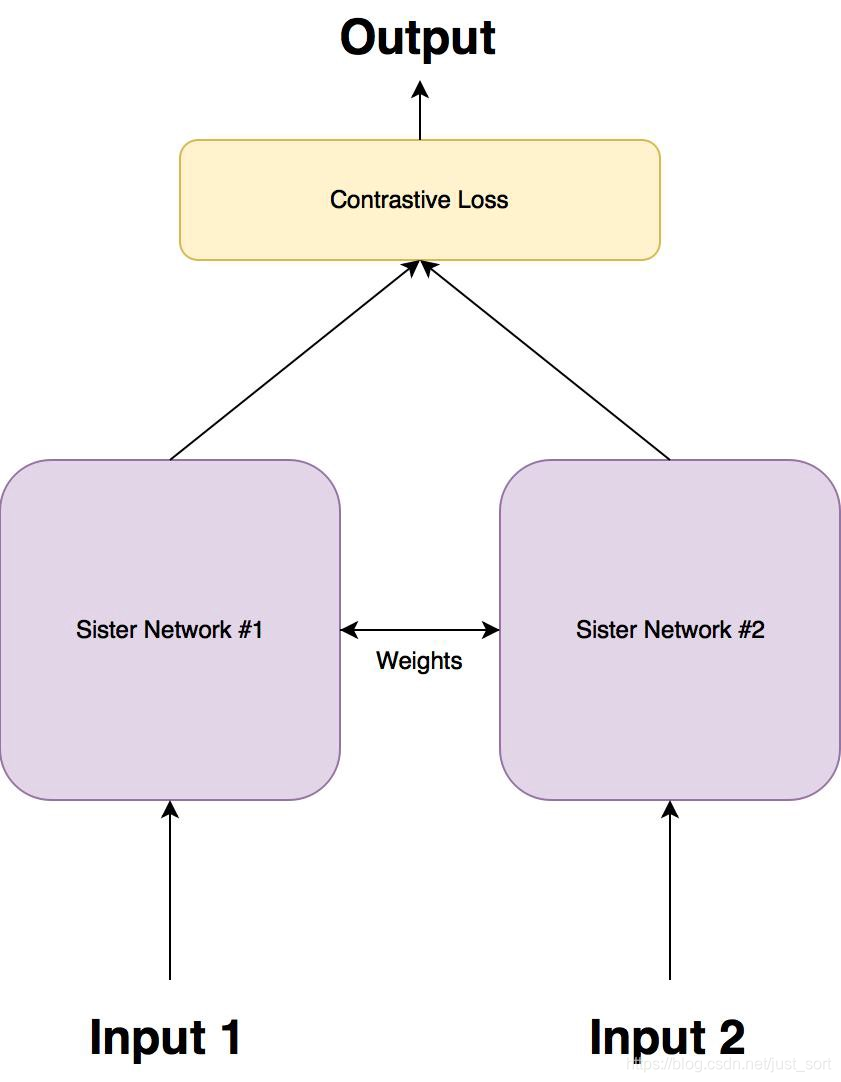
然后孪生网络一般就使用这里要介绍的Contrastive Loss作为损失函数,这种损失函数可以有效的处理这种网络中的成对数据的关系。
Contrastive Loss的公式如下:

其中 W W W是网络权重, Y Y Y是成对标签,如果 X 1 X_1 X1, X 2 X_2 X2这对样本属于同一个类,则 Y = 0 Y=0 Y=0,属于不同类则 Y = 1 Y=1 Y=1。 D W D_W DW是 X 1 X_1 X1与 X 2 X_2 X2在潜变量空间的欧几里德距离。当 Y = 0 Y=0 Y=0,调整参数最小化 X 1 X_1 X1与 X 2 X_2 X2之间的距离。当 Y = 1 Y=1 Y=1,当 X 1 X_1 X1与 X 2 X_2 X2之间距离大于 m m m,则不做优化(省时省力)当 X 1 X1 X1与 X2 之间的距离小于 m m m, 则增大两者距离到m。下面的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1807
1807

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









