



面向虚拟现实大型多人在线游戏的高效边缘云增强
张吴洋,陈佳晨,张延勇,迪潘卡尔·雷乔杜里
罗格斯大学WINLAB实验室,新泽西州, 美国
邮箱:{wuyang, jiachen, yyzhang, ray}@winlab.rutgers.edu
摘要
随着大型多人在线游戏(MMOGs)和虚拟现实(VR) 技术的普及,虚拟现实大型多人在线游戏( VR‐MMOGs)正在快速发展,对更快的游戏交互和图像渲染提出了日益增长的需求。本文中,我们指出了 VR‐MMOGs面临的三个主要挑战:(1)频繁的本地视角变化响应所需的严格延迟要求;(2)持续刷新带来的高带宽要求;(3)支持大量同时在线玩家的大规模要求。考虑到以云为中心的游戏架构可能难以满足延迟和带宽要求,游戏开发社区正尝试利用边缘云计算。然而,一个问题仍未解决:当用户处于移动状态时,如何在用户设备、边缘云和中心云之间合理分配任务,以满足上述三项要求。
在本文中,我们提出了一种实现智能工作分配的混合游戏架构。该架构将局部视图变更更新放置在边缘云上以实现即时响应,将帧渲染放置在边缘云上以满足高带宽需求,将全局游戏状态更新放置在中心云上以支持用户可扩展性。此外,我们提出了一种基于马尔可夫决策过程的高效服务放置算法。该算法在用户通过不同接入点移动时,动态地将用户的游戏服务放置在边缘云上。它还通过共置多个用户来促进游戏世界共享,并降低整体迁移开销。我们推导了最优解,并设计了高效的启发式方法。同时研究了不同的算法实现以加快运行时间。通过详细仿真研究,我们验证我们的放置算法,并表明我们的架构有潜力满足虚拟现实大型多人在线游戏的全部三项要求。
CCS 概念
•网络→网络架构;
ACM 引用格式:
张吴洋, 陈佳晨, 张延勇, 和 Dipankar Ray‐chaudhuri. 2017年. 面向虚拟现实大型多人在线游戏的高效边缘云增强. 在 SEC‘17 会议录, 美国加利福尼亚州圣何塞/硅谷, 2017年10月12日至14日, 14页. https://doi.org/10.1145/3132211.3134463
关键词
边缘计算, 网络架构, 游戏架构, 虚拟现实大型多人在线游戏
1 引言
大型多人在线游戏(MMOGs)的迅速兴起,要求游戏平台能够支持超低延迟和密集的3D世界渲染[1]。随着新兴虚拟现实(VR)技术(e.g.,HTC Vive、Oculus、谷歌纸板)的发展,基于VR的MMOGs,即VR‐MMOGs,正逐渐浮现,对游戏交互速度和图像渲染提出了更高的要求。此外,由于VR与MMOGs的结合,VR‐MMOGs对底层系统设计带来了一组新的需求:1) 需要同时为双眼渲染具有不同视角的两幅图像;2) 需要支持更宽广的视野角度( 120°,而普通游戏为60°);3) 需要提供超低延迟以防止用户产生晕动症(<30ms,而普通游戏为100–1000ms); 以及4) 需要以更高的刷新率进行渲染(60–120帧每秒 (fps),而普通游戏为24–60fps)。
同时,为了使使用“轻量级”移动设备(如智能手机、 平板、电视)的玩家能够享受高质量游戏,游戏开发者提出并开发了一种云游戏范式(也称为按需游戏 [1]),通过该范式从云端向玩家提供游戏。GeForce NOW(面向 Nvidia Shield 客户端 [2])、PlayStation NOW[3], 和 Gaming‐Anywhere 作为云游戏领域的产业先驱,吸引了大量玩家从传统游戏转向这种基于云的模式 [5]。
这些云游戏服务在云服务器上执行游戏逻辑计算,并通过互联网将编码后的画面流式传输到各种移动设备的应用程序上。云游戏使用户能够通过移动设备随时随地访问游戏,而无需定期升级硬件以满足日益增长的硬件需求。同时,它还显著降低了移动设备因繁重的渲染任务而产生的能耗。最后,那些在本地生成非常困难甚至不可能实现的高分辨率帧,也可以从云中进行流式传输。
尽管云游戏可以为玩家带来诸多益处,但其服务提供商面临着一系列严峻挑战,以确保服务质量(QoS)。首要挑战源于云服务器与玩家之间的延迟。在虚拟现实游戏(VR gaming)中,响应速度不足会导致令人不满的游戏体验,并可能引发玩家的晕动症。根据[6], ∼20ms是此类应用可接受的端到端延迟。50毫秒的延迟虽然仍能支持基本响应式服务,但已会出现明显滞后。不幸的是,当前互联网中亚马逊EC2云与移动设备之间的平均网络延迟超过80毫秒[1],,即使不进行任何计算,也已超出可容忍的延迟水平。
第二个挑战是大型多人在线游戏的高带宽需求—— 通常需要100Mbps的带宽才能以60帧每秒的速度流式传输1080p分辨率的VR游戏[7],,而移动设备可用的无线互联网带宽仅为2兆比特每秒[8]。网络抖动会导致刷新率下降和数据包延迟增加,这两者都会恶化用户体验。此外,使用移动设备的用户相比连接固定主机的用户更倾向于移动,有些人甚至会在汽车或火车上玩游戏。由于切换网络接入点导致的断连也可能造成游戏性能下降。
边缘云计算 [8–10] 将云服务推向更接近用户的位置。它有望降低不可接受的网络延迟,提供高下行链路带宽,并充分利用高性能计算资源。虚拟现实大型多人在线游戏可以利用边缘云计算来满足其QoS需求 [11],,但若简单地将所有游戏任务迁移到边缘,则会使玩家难以跨网络共享游戏,因为在广泛分布的边缘云之间同步用户配置文件和游戏世界较为困难。
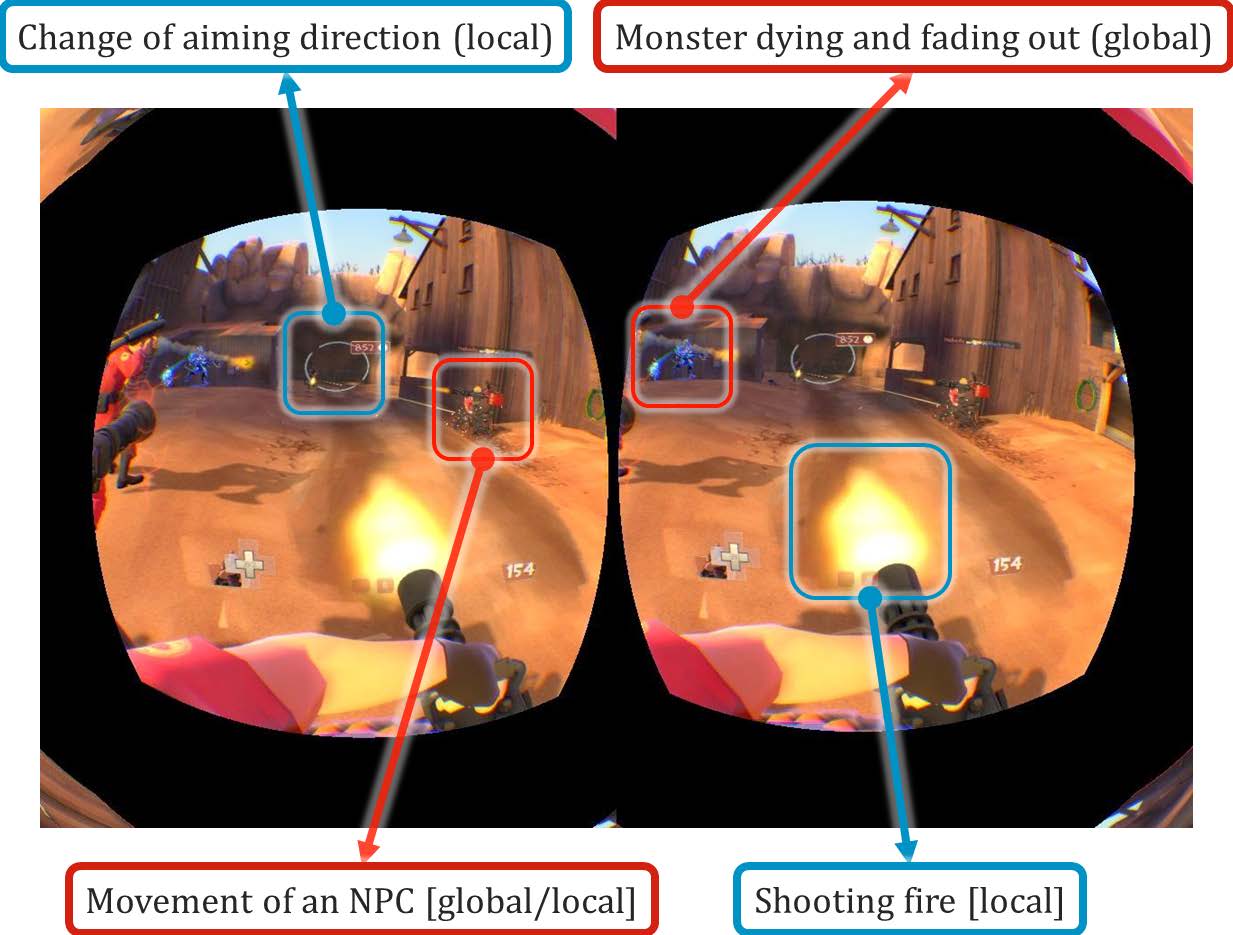
为了解决这些挑战,我们深入研究了虚拟现实大型多人在线游戏中的游戏流程,并发现玩家发起的事件通常可根据响应延迟的容忍度分为两类。针对用户本地视角切换事件(仅对用户本地产生影响)的响应其屏幕上的操作(例如鼠标移动、地图滚动、选择游戏对象但不进行更改)相比对游戏事件的响应(涉及全局游戏状态更新,例如分数更新、射击目标出血效果)具有更严格的时效性要求。在VR‐MMOG中,由于虚拟现实设备的方向不断变化,视图变化事件的发生频率远高于非VR‐MMOG,并且需要在极短时间内(∼20毫秒)在屏幕上得到即时反馈。而另一方面,玩家对游戏事件的延迟容忍度更高,可接受超过100毫秒的延迟,在某些游戏中该值甚至可达1秒[6]。
基于视角变化与游戏事件之间的根本差异,我们认为应对其进行区别处理,以提供最佳的虚拟现实大型多人在线游戏用户体验。本文提出了EC+,一种用于边缘云增强型虚拟现实大型多人在线游戏的架构。EC+利用边缘云进行视图切换事件的渲染,以满足超低延迟的要求。由于边缘云具有更强的计算能力,相较于在移动设备上渲染,边缘云上的渲染还可提供更高的分辨率和刷新率。而对于游戏事件,EC+则使用中心云来管理全局游戏和游戏逻辑。这能够实现广覆盖,并以最小的开销维持游戏状态一致性。
除了提出EC+架构外,我们还设计了一种高效算法,为每位玩家选择边缘云,以应对玩家移动性和动态边缘云工作负载。该算法基于马尔可夫决策过程(MDP),周期性地做出边缘云部署决策,综合考虑整体服务质量(客户端与边缘之间的延迟和带宽,以及 边缘与游戏服务器之间的延迟和带宽)、玩家间的相互影响(例如边缘负载、游戏世界共享)以及玩家移动模式。为确保可行性,我们提出了一种方法,在存储和执行时间上均降低了算法复杂度。此外,我们还设计了一种机制,以确保游戏服务从一个边缘云迁移到另一个边缘云时实现无缝切换。
我们总结了以下贡献:
- 一项关于虚拟现实大型多人在线游戏(VR‐MMOGs)新需求的研究,以及解释以客户端为中心和云游戏为何无法满足这些需求 (§3);
- 一种混合架构设计,利用边缘和中心云来满足虚拟现实大型多人在线游戏的延迟和吞吐量要求(第4节);
- 一种通用的边缘云部署算法,可在不同带宽、延迟、边缘负载和游戏世界共享场景下,为大量玩家最大化游戏性能(§5);以及
- 使用合成和真实世界拓扑进行综合评估,以量化所提出的架构和算法的优势(第6节)。
2 相关工作
我们首先介绍(虚拟现实‐)大型多人在线游戏的背景,然后回顾了可能支持虚拟现实大型多人在线游戏的现有解决方案,即以云为中心的游戏和边缘云计算辅助游戏。
2.1 虚拟现实与大型多人在线游戏的融合
虚拟现实(VR)已得到PlayStation.VR [3], HTC Vive[12], Oculus[6],谷歌纸板 [13]等多种工业产品的支持。VR设备提取玩家的感官(例如,眼睛和耳朵) 信息,并相应地通过虚拟世界生成器的人工刺激“接管” 自然刺激 [14]。VR技术显著提供了具有强烈深度感知的高度沉浸式体验。通过VR设备玩大型多人在线游戏是自然而然的下一步 [15]。事实上,一些流行的大型多人在线游戏已经开发出VR版本,例如 魔兽世界、我的世界多人游戏和侠盗猎车手V在线模式 [16]。
尽管虚拟现实大型多人在线游戏在游戏社区中引发了极大的热情,但它也对底层系统设计提出了前所未有的要求和挑战,尤其是在提供超低延迟和高刷新率方面。本文旨在设计一种经过精心调优的架构,以满足这些需求。
2.2 通过云支持游戏
许多云游戏解决方案[2–4, 17, 18]已被提出,以降低游戏终端的计算和/或存储需求。这些解决方案大致可分为两类:文件流式游戏和视频流式游戏。在文件流式传输游戏(i.e.,渐进式下载)中,游戏的一小部分最初被下载到用户设备上。当这一部分运行时,游戏的其余部分可以并行下载和安装[17, 18]。虽然文件流式游戏确实可以减少游戏启动时间和设备所需的存储空间,但它仍然要求设备处理游戏逻辑并执行3D渲染。因此,很难在谷歌纸板等移动设备上支持虚拟现实大型多人在线游戏。
另一方面,视频流游戏将所有处理任务都放在云中进行,包括用户档案管理、游戏更新计算、游戏帧渲染和编码等。云随后通过互联网将编码后的帧流式传输给玩家 [2–4]。这种机制使得玩家即使在计算能力和电源资源有限的设备(如智能手机、平板电脑、电视)上也能享受高质量的游戏体验——游戏终端只需像观看 YouTube视频一样对帧进行解码即可。随着GPU网格的出现 [19],,游戏处理效率相比仅使用基于中央处理器的云有了显著提升。
许多研究致力于进一步提升视频流游戏的用户体验。在 [20]中,视频游戏被分为中央处理器消耗型和内存消耗型,以提高云中的资源利用率。Lee etal.[21]采用高效视频编码 (HEVC)技术,在不影响视频质量的前提下将带宽要求降低59%。[22, 23]中的解决方案通过预测可能的游戏更新并提前渲染推测帧来减少响应时间。
然而,云游戏(包括文件流和视频流游戏)的主要缺点是需要通过核心网络传输大量数据,无论是游戏本身还是游戏帧。由于互联网设计具有大规模复用的特性,云与玩家之间的可用带宽和延迟可能会随时间发生剧烈变化[24]。这常常导致游戏中出现抖动、卡顿、丢帧或低质量画面(画面故障),从而造成较差的游戏体验,尤其是对于视频流游戏而言[25]。
2.3 边缘云计算
边缘云(或雾计算 [8–10])将计算和存储资源推向更靠近客户端的位置,有望实现更低的延迟和更高的带宽。它可以为需要高带宽、低延迟但无需大规模聚合的应用程序带来优势,e.g.,监控摄像头数据预处理 [26],图像分类 [27],智能交通灯控制 [9], etc.如果经过精心设计以解决大规模聚合的挑战(i.e.,所有玩家之间的游戏状态同步),边缘云计算也有潜力更好地服务于(虚拟现实‐)大型多人在线游戏。
在[28–30]中的研究提出了一种点对点(P2P)大型多人在线游戏,其中玩家的代理(游戏主机或边缘云服务器)构成一个P2P网络,直接在玩家之间同步共享的游戏状态。这种分布式架构会产生大量的同步开销,并可能限制游戏中并发玩家的数量。为应对这些挑战, [31]中的作者提出将渲染过程从云迁移至靠近客户端的空闲桌面。事实上,该技术可将网络延迟降低20%,并将网络流量减少90%。然而,所有用户事件(包括那些仅需本地更新的事件)都被统一发送到中心云。该方案对于非虚拟现实游戏表现良好,因为这类游戏中本地更新事件较少。但虚拟现实大型多人在线游戏具有显著更多的此类事件,使得该方案不适用。
2.4 云间服务迁移
为了满足特定的应用需求,任务最初必须被放置在云 [32–34] 的指定机器上。随后,这些任务可能会被迁移 (重新分配)到利用率低的机器上,以实现特定的优化目标。关于迁移到何处,已有基于预期最优目标的不同迁移策略被提出。Lim etal.[35] 提出了一种感知性能的迁移方案,以应对动态服务器负载。Ghribi et al.[36] 研究了一种节能调度方法,以实现显著的节能效果。关于如何迁移,道格利斯 [37] 提出了一种进程迁移方案,将进程从源机器移动到目标机器,但该方法面临将进程与其操作系统分离的困难。Clark et al.[38] 设计了一种虚拟机(VM)实时迁移机制,有效克服了这一障碍。
然而,虚拟机迁移的一个主要成本是在迁移过程中产生短暂的停机时间,在此期间应用程序被迫暂停。停机时间因不同应用程序而异,范围从几毫秒到几秒[39]。为了减少停机时间,Jinet al.[40] 研究了一种内存压缩方法,Haet al.[41] 研究了虚拟机迁移的流水线处理。
3 深入探讨虚拟现实大型多人在线游戏
虚拟现实大型多人在线游戏本质上是一个大规模的事件驱动系统。尽管每款虚拟现实大型多人在线游戏可能拥有独特且复杂的游戏逻辑,但它们具有相似的游戏事件,并共享相同的底层游戏流程。在本节中,我们首先研究虚拟现实大型多人在线游戏的新特性和挑战,然后介绍几种现有的大型多人在线游戏模型,以帮助理解为何这些模型无法满足这些新要求。
3.1 视图变更事件 vs.游戏事件
任何游戏流程都始于特定的用户事件。玩家在玩游戏时,可以通过鼠标、键盘、VR头显等外部设备触发用户事件。例如,在游戏世界中的某个位置点击鼠标、按下特定按键,或(佩戴VR头显时)改变头部朝向,都会引发一个用户事件。然而,玩家对不同类型的事件有不同的延迟期望,因此游戏架构应区别对待这些事件。
我们意识到,用户事件有两种基本类型,即(局部)视角变化事件和(全局)游戏事件。第一种用户事件——视图切换事件——仅对用户的视角造成瞬时变化,而不会改变其游戏世界。例如,在位置(153,85)点击鼠标的用户事件可能会被解释为从玩家的军队中选择部队。被选中的士兵将在玩家屏幕上高亮显示,但该事件对其他玩家是不可见的。
第二种用户事件——游戏事件——不仅会导致玩家视角的变化,还会对其游戏世界造成永久性更新,我们称之为游戏事件。在(虚拟现实‐)大型多人在线游戏中,此类更新应在所有能看到该游戏事件的玩家之间进行同步。例如,同一鼠标点击(153,85)可能被解释为“玩家A击打玩家B” 或“玩家A从地面拾取100个金币”,两者都会对游戏世界造成改变,因此被视为游戏事件。由于相同的用户事件可能根据特定的游戏逻辑和特定的游戏世界被不同地解释,因此大型多人在线游戏通常包含一个模块,用于在将这些事件发送至游戏服务器之前区分用户事件的类型。
如图1所示,所有用户事件无论类型如何,最终都将在用户界面上反映出来。然而,玩家对反馈延迟的期望确实不同。根据[6],,玩家对游戏事件的容忍度各不相同,范围从100毫秒(e.g.,第一人称射击游戏)到1秒(e.g.,实时策略游戏)。许多研究致力于通过优化服务器调度[20],、改进渲染算法和硬件[19]以及优化网络传播[42]来降低游戏事件响应延迟。
与游戏事件相比,我们发现玩家对视图变化事件期望的反馈延迟要短得多,这似乎有违直觉。即时本地视角更新能够实现流畅的游戏控制和无缝的用户体验。此处可容忍的延迟范围从几十毫秒(e.g.,3D 游戏中的方向变化)到几百毫秒(e.g.,按键)。对于视频流式传输游戏而言,这种延迟更为关键,因为渲染器位于云中,距离较远,而非本地GPU。
| 表1:虚拟现实大型多人在线游戏中事件类型的比较。 | ||
|---|---|---|
| 视角变化 | Game | |
| 可容忍延迟(毫秒) | 20 | 100 |
| 事件大小(字节) | 180 | 90 |
| 频率(每秒事件数) | 95 | 5 |
VR‐MMOG中此类事件的高发频率使情况更加恶化。我们基于几项关于游戏的研究[6, 43–45],在表1中比较了视图切换事件与游戏事件的特征。在VR‐MMOG中持续发生的方向变化(视图切换事件)通常需要反馈延迟尽可能低于20毫秒[6],,以确保良好的用户体验。当延迟超过50毫秒时,玩家可能会感到头晕。这种超低延迟使得中心云几乎无法支持视频流游戏,因为亚马逊 EC2与客户端之间的平均延迟已经高于80毫秒。方向变化事件的数量是另一个挑战,因为游戏通常每秒获取加速度计和陀螺仪读数超过50次,一些高端设备如HTC Vive甚至可达100次。这一频率远高于视图变化事件。
通过每分钟操作数(APM)估算的游戏事件通常约为 50,在熟练玩家操作下最高可达300[45]。因此,我们认为视图切换事件应被视为“头等大事”,并且应精心设计游戏架构,以在虚拟现实大型多人在线游戏中更好地支持这些事件。
3.2 大型多人在线游戏架构概述
我们研究了现有大型多人在线游戏架构的底层通信和计算模型,以理解这些方案为何在支持虚拟现实大型多人在线游戏方面存在不足。根据渲染发生的位置,我们将这些架构分为两类:传统的客户端为中心的游戏和云为中心的游戏。尽管文件流式传输游戏也得到云的支持,但其游戏模型几乎等同于客户端为中心的游戏,因为它需要本地功能强大的游戏主机来进行渲染。这两种游戏模型的流程图如图2a和2b所示。
3.2.1 传统的客户端为中心的游戏。
传统游戏架构在客户端执行大部分任务,除了共享游戏世界的同步。如图2a所示,游戏循环以捕获用户事件 (例如,鼠标点击(153,85))开始。该事件首先被发送到本地游戏事件计算器(步骤S1),以检测其是否为游戏事件。在大多数游戏中,游戏事件也会触发视图切换事件 (例如,射击)
| 表2:不同游戏中移动设备与台式机的刷新率(帧每秒)比较。 | ||||
|---|---|---|---|---|
| Game | 分辨率 | 台式机 | 移动设备 | |
| 星际争霸II | 1024×768 | 380 | 55 | |
| 星际争霸II | 1280×1024 | 136 | 13 | |
| 星际争霸II | 1920×1080 | 119 | 5 | |
| GTA V | 1024×768 | 168 | 10.8 | |
| GTA V | 1280×1024 | 161 | <5 | |
| GTA V | 1920×1080 | 136 | <5 |
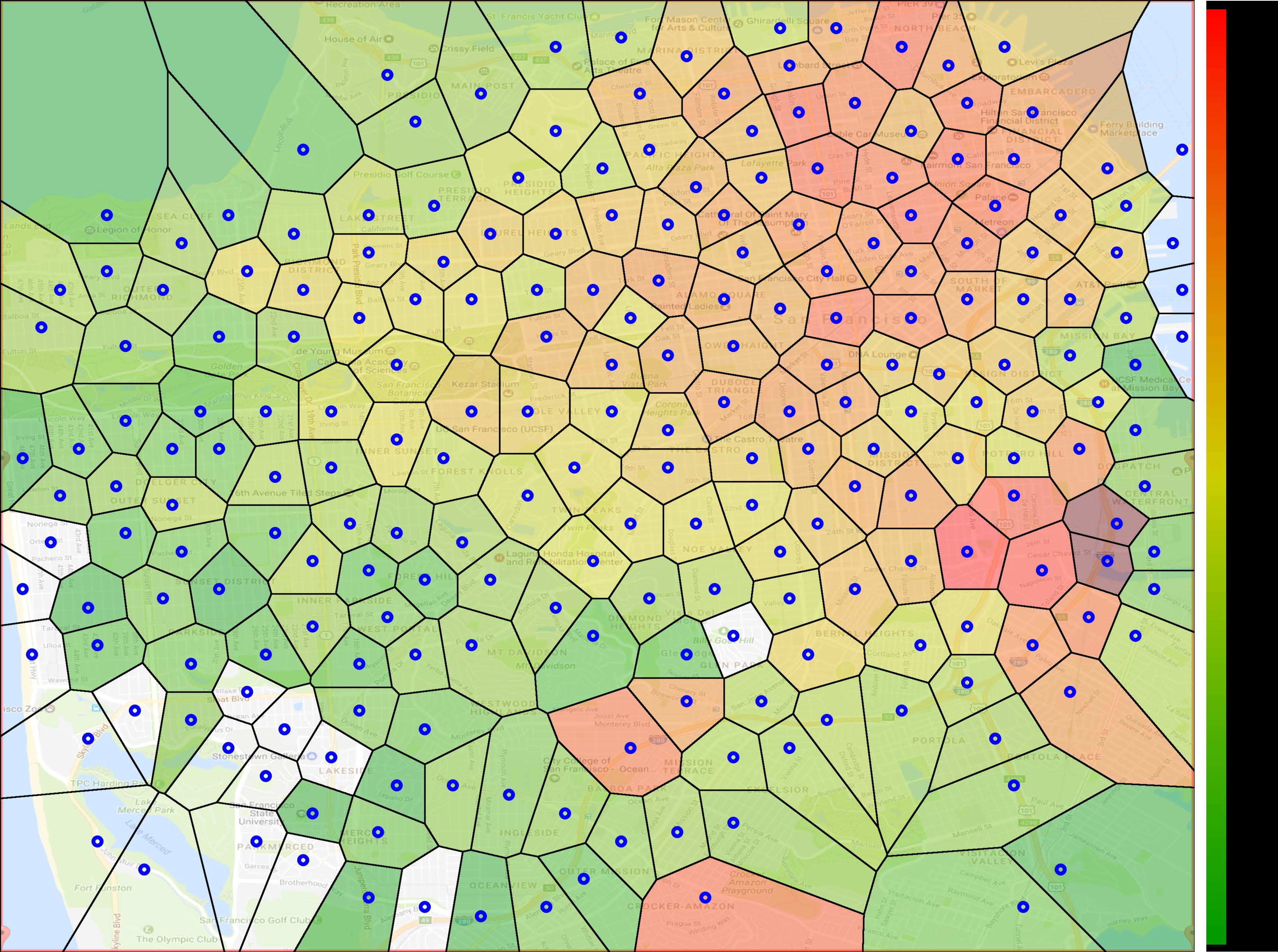
图1中的开火),因此会向渲染器发送一个视图变化渲染请求(步骤S2′)。如果该事件是游戏事件(例如,玩家 A击打B),此游戏事件将被转发到游戏服务器(步骤S2)。一旦服务器接收到游戏事件,验证模块会根据游戏逻辑(e.g.,A是否被允许攻击B,A是否足够靠近B等)检查该事件的有效性。它将丢弃可疑的作弊事件(可能由游戏机器人生成)和过时事件(由网络延迟引起)。服务器上的更新计算器随后计算每个有效游戏事件的 “后果”(游戏更新,e.g.,A获得3点经验值,B后退一步并损失20点生命值),并相应地更新用户档案。用户档案通常包含游戏角色的个体状态信息(e.g.,当前位置、经验值和技能等级)。为了避免传输过多的小型游戏更新,服务器通常会在短时间内累积游戏更新,并将该时间段内的所有更新批量发送(步骤S3)。该时间段的长度通常由所有玩家中最小的帧间隔决定(e.g., 对于30帧每秒的客户端为33毫秒)。当所有玩家共享同一个同步游戏世界时,相同的更新应送达所有玩家,因此可以通过多播或广播方式发送,以提高分发效率。
客户端上的渲染器通常会定期(每秒30‐60帧)渲染游戏世界,以反映视图变化事件(来自S2)和游戏更新(来自S3)的输出。在大多数游戏中,即使没有需要反映的更新,渲染器也可能生成帧,例如光强的变化、水流的流动和/或非玩家角色(NPC)的移动。渲染过程将几何、视角、纹理、光照和着色投影到游戏世界中的3D骨架对象上,最终在游戏界面(如屏幕或VR设备) 中输出一个游戏帧(步骤S4)。
该架构通常要求游戏客户端具备充足的中央处理器、 图形处理器和内存资源,因为渲染一帧涉及大量的矩阵乘法和浮点运算。因此,对于偏好使用移动设备玩游戏的玩家来说并不友好。例如,像AMD Radeon HD这样的普通台式机图形处理器7970M在1024x768、1280x1024和1920x1080分辨率下运行《星际争霸II》时,分别可达到380、136和119帧率。然而,采用于微软Surface 3平板电脑的英特尔高清显卡 Cherry Trail(GPU)在相同分辨率下仅能提供55、13和 5帧率(见表2)。这意味着,如果玩家试图在微软 Surface 3平板电脑上玩这款游戏,则只能选择1024x768 或更低的分辨率。类似限制也存在于GTA V、我的世界等大多数流行的大型多人在线游戏中etc.然而,为了享受沉浸式的虚拟现实游戏体验,玩家不应受限于台式机和电缆。
3.2.2 以云为中心的视频流游戏。
以云为中心的视频流游戏[2–4]显著降低了用户设备的资源需求。所有渲染任务将在中心云中执行,如图 2b所示。具体而言,客户端设备仅需将用户事件直接发送到云,并接收后续的更新后的帧。这种视频流游戏架构有望使玩家能够在移动设备上享受大型多人在线游戏,但要通过该架构支持虚拟现实大型多人在线游戏,仍需解决若干重要挑战。
首先,该架构难以满足VR‐MMOG的超低延迟要求。特别是,用户可能希望视角变化渲染在20ms内完成[6]。当延迟为50ms时,VR游戏仍能响应用户的输入,但会出现明显的滞后现象,可能导致不良的用户体验。不幸的是,亚马逊EC2与移动设备之间的平均网络延迟约为 80ms[1],,远高于视图切换事件所期望的延迟。
其次,该架构在支持高刷新率方面也面临挑战。虚拟现实大型多人在线游戏通常需要50兆比特每秒的带宽来传输1080p分辨率、60帧每秒的视频,而移动设备通过无线网络所能获得的可用带宽仅有约2兆比特每秒[8]。在传统游戏架构中,游戏服务器只需向客户端发送游戏更新,这些更新可以通过多播方式传输,以最小化网络流量。然而,在此架构中,游戏服务器需要向每个单独的客户端发送不同的渲染帧,因此必须采用单播方式。综合来看,与传统游戏架构相比,该架构所需的网络带宽显著增加。
4 EC+:由边缘云增强的虚拟现实大型多人在线游戏架构
在上一节中,我们讨论了传统的以客户端为中心的游戏方式将繁重的渲染任务放在游戏客户端上,这实质上导致用户无法在移动设备上运行虚拟现实大型多人在线游戏。视频流游戏本意是为移动设备提供便利,但由于响应缓慢和视频质量差,最终未能实现这一目标。因此,人们希望利用一种具有充足资源且与客户端之间网络延迟较短的第三类计算平台。我们认为边缘云计算是一个理想的选择,原因如下:1) 边缘云中的服务器通常配备桌面级或更高级别的图形处理器,具备足够的计算能力; 2) 它位于接入网络中,靠近用户。
基于这一理解,我们提出了一种新架构EC+,该架构巧妙地在中心云和边缘云之间分配工作。它具有以下显著特点:1) 利用边缘云管理视角变化更新和渲染,以实现低延迟和高刷新率;2) 利用中心云管理游戏状态更新,以支持大量玩家并最小化维持一致游戏状态所需的开销;以及3) 通过执行动态游戏服务迁移来处理用户移动性和边缘云计算负载不均衡,从而提供持续的性能保障。
4.1 EC+中的游戏流程
下面,我们将逐步讨论EC+架构中的游戏流程,该流程也在 图2c中展示:
-
客户端上的用户事件转发 (S1)
:VR游戏设备捕获所有用户输入,并将其发送到指定的边缘云。我们将在第 5节讨论如何为用户选择并动态更改关联的边缘云。
-
边缘云上的本地视图更新与渲染 (S2,S2′)
:当边缘云接收到用户事件时,会将该事件传递给“游戏事件计算器”,该计算器并行执行两项任务:(1)计算本地视图更新,以及(2)判断是否涉及全局游戏事件。在任务(1)完成后,本地视图更新请求将被传递给“渲染器和编码器”,由其执行图像渲染与编码。在任务(2)完成后,若需要触发全局游戏事件,则该游戏事件将进一步传递至中心云。
-
中心云上的全局游戏更新 (S3)
:游戏服务器的行为与传统游戏类似。当位于中心云上的游戏服务器接收到游戏事件时,它会计算由此事件引发的更新,相应地更新用户档案,并生成一个或多个针对参与此游戏事件的所有玩家的更新请求。然后,它将这些请求发送到这些玩家当前连接的边缘云。与传统游戏类似,该服务器在此处也可以利用多播技术进行游戏更新的分发。
-
在边缘云上进行游戏世界变化渲染 (S4)
:边缘云执行所有渲染任务,包括本地视角变化渲染、游戏世界变化渲染以及背景视图刷新渲染。渲染性能对EC+的整体性能至关重要。我们可以利用类似[46]中提出的可扩展的并行渲染框架技术,为共享同一游戏世界的多个玩家同时进行渲染,从而显著降低整体渲染延迟。
总之,所提出的游戏流程具有以下优势。首先,在处理时绕过中心云通过视图变化事件(在步骤S2′中)可以大幅缩短响应延迟,从而实现即时的本地视图更新。其次,通过在边缘云上渲染帧(在步骤S4中),我们可以利用其低延迟和高带宽优势。第三,由于采用边缘云以及对用户多播游戏更新的可能性,核心网络流量可以大幅减少。
4.2 边缘云迁移
当我们将玩家的游戏服务(包括驻留在边缘云中的所有组件)部署到边缘云上时,选择合适的边缘云成为一个关键问题。在初步选定边缘云之后,我们还需要考虑随着工作负载和用户位置的变化,将服务动态迁移至其他边缘云的需求。具体而言,当玩家在玩游戏时移动位置, 和/或各边缘云的工作负载随时间发生变化时,服务迁移就变得十分必要。
在我们的框架中,通过将连续时间划分为相等长度的离散时间槽(例如2分钟),来考虑迁移问题。通过这种时间划分,我们可以基于网络/服务器状态的离线快照,为网络中的所有客户端同时做出最优迁移决策。然而,为了响应动态的网络/服务器状态,任何在线解决方案都会在高频率的决策过程中引入显著的计算开销。
我们开发了一种基于马尔可夫决策过程(MDP)的高效算法,用于选择并迁移玩家的边缘服务,具体内容将在第5节详细讨论。但与许多假设服务切换时间可忽略的服务迁移方案不同,我们认识到,鉴于虚拟现实游戏世界的规模,不可能立即将边缘服务从一个边缘迁移到另一个边缘。因此,我们提出了一种机制,以确保当玩家连接到新的边缘云时,新的边缘云能够被激活。
为了确保在两个边缘云之间实现平滑过渡,关键在于能够为连接到目标边缘云的玩家正确渲染帧。帧渲染过程包括对游戏世界矩阵、视图/透视矩阵以及投影矩阵进行的一系列矩阵运算,其中游戏世界矩阵表示具有特定空间关系的一组三维游戏模型,视图/透视矩阵将三维游戏模型的相对位置转换以适配特定的视角,投影矩阵则将三维游戏模型的位置转换为齐次屏幕空间。EC+中的服务迁移主要涉及迁移玩家的游戏世界,因为其他矩阵在尺寸上可忽略且易于重新生成。
在此,我们讨论从 τ开始的一个时隙内的迁移事件。我们假设移动用户在 τ时刻从边缘云e获得服务。
- EC+开始在网络中于时间 τ为所有客户端做出迁移决策。
- 在时刻 τ+ ∆1,边缘云+完成决策计算,并决定将该移动用户的服务迁移到边缘云e′。e′将收到通知,从而订阅该游戏的多播组并开始接收所有游戏更新。边缘云 e开始发送在 τ+ ∆1时刻的游戏世界快照。
- 在时间 τ+∆2,e′成功接收游戏世界快照(在 τ+ ∆1时刻拍摄),并开始合并自 τ+ ∆1以来接收的游戏更新。
- 在该时刻 τ+∆3,e′完成合并,现在它已拥有与e中保存的完全相同的最新游戏世界。同时,e′继续接收游戏更新并保持游戏世界处于最新状态。
- 在时隙 τ 结束时,该移动用户连接到e′,并成功从这个新的边缘云获得游戏服务。之前的边缘云 e 将释放所有游戏资源 i f th这里没有其他 her cl客户端连接到它.
通过该机制,我们可以在时隙大于 ∆3的所有迁移中,在 EC+上无缝完成服务迁移,而不会产生任何服务停机时间。
5 用户移动性下的边缘云选择
我们设计了一种算法,以在动态网络状态、服务器工作负载状态和用户移动性存在的情况下,高效地确定边缘云服务的部署与迁移位置(初始的边缘云选择也可泛化为一种迁移操作)。在EC+中,我们将部署/迁移算法建模为一个马尔可夫决策过程(MDP)[47],因为部署/迁移决策仅受当前状态和用户移动性的影响。我们注意到,已有文献研究了若干基于马尔可夫决策过程的选择方法[11, 48–51],,但我们发现虚拟现实大型多人在线游戏(VR‐MMOGs)带来了新的挑战,即随时间变化的网络状态、玩家间的相互影响,以及通信中额外存在的实体(中央服务器)。在本节中,我们提出改进的边缘选择算法。
5.1 使用MDP建模边缘选择问题
在我们的选择算法中,我们考虑了总共M个边缘云,以及N个移动用户通过其连接到互联网的接入点。正如我们在第4节中讨论的那样,我们将连续时间划分为相等长度的离散时间槽。
在一个时隙τ,移动用户连接到接入点nτ ∈[1, N],并从边缘云mτ ∈[1,M]接收游戏服务。我们将此定义为一个状态Sτ=mτnτ。玩家可能在时隙结束时移动并连接到一个新的接入点。由于用户移动性和边缘上工作负载的变化,我们可能需要将游戏服务迁移到合适的边缘,以满足用户的QoS需求。为了实现这一点,对状态采取的动作aτ,将服务从边缘云mτ迁移至mτ+1。动作aτ由可能的边缘云位置mτ+1表示,因此aτ ∈[1,M]。预期位于 mτ+1的新边缘云通过考虑玩家在下一个时隙中可能出现的任何位置(nτ+1),具有最小网络成本。请注意,在时间 τ计算MDP时,我们假设迁移发生在 τ+ 1,正如我们在前一节中所描述的那样。因此,在时隙τ+1,系统可能进入一个转移状态:Sτ+1=mτ+1nτ+1,其转移概率为p(Sτ, aτ, Sτ+1)。我们假设转移概率是作为算法的已知参数给出的,因为已有大量关于移动性预测的研究,包括[52–54]以及我们早期的工作[55],这些研究基于聚合的网络层统计来计算用户移动的概率。
为了确定目标边缘云 mτ+1,定义了一个成本函数 C(Sτ, aτ, Sτ+1),用于衡量从状态Sτ到状态Sτ+1时,在执行动作aτπ的情况下整体的网络传输成本以及迁移成本。我们在§5.2中详细描述该成本函数。我们的目标是为每个用户在每个时隙找到一个最优动作(aτπ),以最小化长期成本。
长期成本函数由以下公式给出
$$
V(S_0)=
\sum_{\tau=0}^{\infty}
\gamma^\tau \cdot
\sum_{S_{\tau+1}=1}^{M\times N} p(S_\tau, a_\tau^\pi, S_{\tau+1}) \cdot C(S_\tau, a_\tau^\pi, S_{\tau+1}),\quad(1)
$$
其中 $\gamma \in[0, 1]$是一个折扣因子,用于控制未来状态对从当前状态计算的长期成本的影响。我们将公式1给出的长期成本的累积和转换为递归定义:
$$
V^
(S_\tau)= \min_{a_\tau}
\left{ \sum_{S_{\tau+1}} p(S_\tau, a_\tau, S_{\tau+1}) \cdot \left[C(S_\tau, a_\tau, S_{\tau+1})+ \gamma \cdot V^
(S_{\tau+1})\right] \right}, \quad (2)
$$
众所周知,每个状态Sτ的最优动作aτπ= mτ+1 ∈[1, M]可以通过贝尔曼值迭代获得,该方法通过迭代更新公式2,直到V ∗ (Sτ)的值收敛。
5.2 特定游戏成本函数
在建模放置算法时,我们力求最小化动作的“成本”,以提供最佳的游戏体验。我们认为,成本函数应考虑不同的特征,包括延迟、带宽,etc.。在此,为了提出一个能够满足所有需求的通用框架,各种虚拟现实大型多人在线游戏,我们不对不同功能的应用需求做强制规定。相反,我们假设游戏提供商可以根据[56–59]中的研究及其策略获得其成本函数。
在本节中,我们列出了一组考虑中的特性。它们分为两类:迁移成本和传输成本。迁移成本是指迁移边缘服务时产生的成本。由于我们已有机制避免应用停机时间,因此该成本仅限于带宽成本(i.e.,即游戏世界的大小)。传输成本是指边缘云与玩家之间通信所产生的成本。传输成本可进一步分为两种子类型:无相互影响的成本和有相互影响的成本。无相互影响的成本仅通过网络延迟、带宽和服务器负载来衡量,而有相互影响的成本还需额外考虑游戏世界共享的次数(因为一个玩家的迁移决策可能同时影响正在共享同一游戏世界的其他玩家的决策)。重要的是,我们强调了有相互影响的成本,其目的在于将多个用户共置在同一边缘云中,以促进游戏世界共享并降低整体迁移开销。
5.3 最优联合迁移决策
许多早期基于MDP的迁移方法为每个用户计算个体迁移决策,假设用户的迁移决策对其他用户影响较小。然而,在考虑共置时,这一假设不再成立。因此,我们必须在每一步考虑所有可能的迁移决策组合,并找到最优的联合迁移方案。
假设每一步需要联合考虑的迁移决策总数为K,这也等于系统中的用户数量,并将每个决策表示为dk,k ∈[0, K。然后我们将状态重新定义为Sдlobal(t) ={Sd1(t), Sd2(t), …, SdK− 1(t)},联合动作定义为aдlobal(t) ={ad1(t), ad2(t), …,adK− 1(t)}。新的奖励函数是每个单独决策的奖励函数之和。最后,我们求解公式1以计算最优联合迁移动作a ∗ дlobal(t)。
尽管该方法能够提供全局最优的迁移决策,但搜索最优联合解的时间复杂度远高于独立处理每个迁移决策的方法。具体而言,后者的 时间复杂度为O(M 3 N 2 ),而全局解的时间复杂度为O((M 3 N 2 ) K )。这一成本过高,导致我们无法实时找到最优的联合解。
5.4 启发式联合迁移决策——最高迁移概率优先
在为每位玩家计算最优迁移决策时,我们假设所有其他玩家均保持连接至其当前的边缘云,因此整个边缘云服务状况不会发生变化。只有在此假设下,最优迁移决策才能持续保持最优。然而,若考虑多个玩家的一系列迁移决策,则无法维持此假设。为了尽可能接近该假设,我们可以对所有玩家的迁移概率进行排序,并优先为迁移可能性更高的玩家计算最优迁移决策。通过这种方式,在做出一个迁移决策后,后续的迁移决策更有可能使得玩家仍连接至当前的边缘云。为了估计迁移可能性,我们采用总成本函数值减去迁移成本的方法。我们认为,这种具有时间复杂度O(kM3N2)的启发式方法能够最小化全局迁移成本。
5.5 运行时优化以减少执行时间
我们发现了边缘放置问题中MDP计算的一些特性,这些特性可用于优化运行时间。我们发现的第一个特性是
$$
\forall a_\tau, m_{\tau+1}: p(m_\tau n_\tau, a_\tau, m_{\tau+1}n_{\tau+1})= 0, \text{ where } a_\tau \neq m_{\tau+1}.
$$
这表明迁移动作对下一状态是确定性的。因此,我们可以将状态转移概率从 p(mτnτ, aτ, mτ+1nτ+1) 简化为 p(mτnτ,mτ+1nτ),同时将成本函数从 C(mτnτ, aτ, mτ+1nτ+1) 简化为 C(mτnτ, mτ+1nτ+1)。相应地,我们可以将 p 和 C 的空间复杂度从 O(M3N2) 降低到 O(M2N2)。
我们发现的第二个特征是
$$
\forall m_\tau, m’
\tau, m
{\tau+1}, m’
{\tau+1}: p(m
\tau n_\tau, m_{\tau+1}n_{\tau+1})= p(m’
\tau n
\tau, m’
{\tau+1}n
{\tau+1}).
$$
这表明状态转移概率仅与关联的接入点有关,而与服务器部署无关。因此,我们可以将转移概率从p(mτ nτ,mτ+1nτ) 简化为 p(nτ, nτ+1), 并相应地将 p 的空间复杂度从 O(M2N2) 降低至 O(N2)。
我们发现的第三个特征是
$$
\forall n_\tau, n’
\tau: C(m
\tau n_\tau, m_{\tau+1}n_{\tau+1})= C(m_\tau n’
\tau, m
{\tau+1}n_{\tau+1}).
$$
这意味着成本函数仅与时隙 τ+ 1 的连接接入点 nτ+1 相关。因此,我们可以将成本函数从C(mτ nτ,mτ+1nτ+1)简化为C(mτ,mτ+1nτ+1),并相应地将C的空间复杂度从 O(M 2 N 2 )降低到O(M 2 N)。
dt)。)
通过综合考虑上述3个命题,我们可以将公式1简化为
$$
V(m_0n_0)=
\sum_{\tau=0}^{\infty} \gamma^\tau \cdot
\sum_{n_{\tau+1}=1}^{N} p(n_\tau, n_{\tau+1}) \cdot C(m_\tau, m^\pi_{\tau+1}n_{\tau+1}),\quad(3)
$$
其中 mπ τ+1是我们时隙 τ 的决策,该决策在时隙 τ+1 生效。因此,我们可以将总空间复杂度从 O(M3N 2) 降低到 O(M2N +N 2),并将每次 MDP 迭代的时间复杂度从 O(M3N2) 降低到 O(M2N2)。由于公式3的计算可以转化为向量乘法 p(nτ, ∗)·[C(mτ, aτ ∗)+γV (aτ,γ)],, 因此我们可以利用并行计算(多线程和 GPU)进一步减少执行时间。我们在第6节中评估了所提出的优化的性能提升。
5.6 进一步优化
除了在VR‐MMOG迁移中应用MDP的上述优化之外,我们还考虑了以下优化:1) 每个玩家在其常规活动范围内移动,并且可能(除非不可能)从不链接到部分远程接入点。因此,概率表是稀疏的。我们可以压缩该概率表以及代价表,以进一步降低时空复杂度。2) 在许多情况下,由于严格的延迟和带宽要求,玩家只能连接到附近的几个边缘云。我们可以识别并排除无法满足要求的远程边缘云,将其从可能的迁移目的地中去除。然后可以移除与这些迁移目的地相关的状态,并消除针对这些状态的成本和效用表的计算。由于所提出的边缘放置算法是一个普遍适用于所有(虚拟现实‐)大型多人在线游戏的框架,我们将特定应用程序的优化留作未来工作。
6 评估
我们对所提出的EC+架构以及基于MDP的服务放置/迁移算法进行了详细的基于仿真的评估。本节总结了仿真结果。
6.1 EC+与其他游戏架构的比较
我们使用详细仿真研究来比较我们的 EC+ 架构与传统的客户端为中心的游戏架构以及云中心化视频流架构。
6.1.1 仿真设置
我们首先介绍用于比较研究的仿真设置。
网络拓扑 :我们使用先前工作中开发的旧金山AP地图[55]作为网络拓扑。我们利用沃罗诺伊图元估算每个接入点的覆盖范围(见图3)。进一步地,我们将接入点分配到不同的域中,以表示更真实的网络拓扑。具体而言,我们构建了一个如图4所示的三级分层拓扑。
在仿真中,游戏玩家通过接入点连接到互联网,边缘云假设与域路由器共址。中心云位于C(见图4)。我们仔细选择了网络中不同链路的带宽和延迟参数。例如,我们假设在域内网络中,节点通过千兆交换机连接,具有毫秒级延迟。ISP间连接的实际容量通常要高得多,但由于核心网络与其他流量共享,且互联网服务提供商之间可能没有直接连接,因此我们选择200Mbps的带宽(共享带宽)和50毫秒的延迟(由于两个ISP之间的跳数较多)。因此,我们在图4中总结了不同类型链路所选的带宽和延迟值。
玩家位置轨迹 : 为了模拟移动游戏玩家,我们使用了在早期工作 [60]中采用的旧金山出租车轨迹。该轨迹包含了2008年5月17日至2008年6月10日期间500多辆出租车的位置信息。我们观察到轨迹中明显的日常移动模式。在本研究中,我们选择2008年 5月31日星期六的数据集作为我们的轨迹数据。由于模拟的接入点主要位于旧金山市中心区域(见图3中的地图),我们重点关注在该区域内行驶的66辆出租车。我们假设这66名玩家正在玩同一款大型多人在线游戏。图3显示了每个接入点的 “热度”。接入点a的热度计算公式为H(a) =∑u∈Ut u(a), 其中tu(a)表示用户u与接入点a关联的总时间。
游戏轨迹 :我们考虑了一个1小时的合成游戏轨迹,参数取自研究[43]。每位玩家的用户事件以泊松分布到达(λ介于 9.5到15之间),其中一部分被随机选为游戏事件。每位玩家每分钟的操作数在30到300之间。总共我们有 18,686,459个用户事件(平均:每个用户每秒78.642个用户事件),以及287,567个(1.53%)游戏事件(平均:每个用户每分钟72.618次操作)。用户事件大小:泊松分布 (λ=40);更新大小(在传统架构和边缘架构中):泊松分布(λ=130)[43];帧大小(在视频流和边缘架构中): (60Mbps / 60fps)=∼1Mb/f。游戏以60fps刷新。
指标 : 我们使用的指标包括事件延迟(事件发生到客户端看到相关更新之间的时间),涵盖用户和游戏事件、核心及边缘网络流量,以及帧率。
6.1.2 与静止玩家的比较结果
为了研究不同架构之间的基本差异,我们在假设玩家静止的情况下进行比较。具体而言,我们选取每位用户在 5月31日0:30、1:30、⋯以及23:30的位置,生成24条不同的轨迹。我们使用这些轨迹对每种架构进行评估,并将结果展示在图5中。
传统的客户端为中心的游戏在用户配备带有强大 GPU的台式机(平均渲染延迟为10ms)时表现良好。在这种情况下,视图切换响应延迟非常低,为∼20 ms。总网络流量也很低(∼400Mb),因为服务器和客户端之间仅交换少量的游戏更新数据包。客户端,支持多播。最终可实现60fps的刷新率。当使用移动设备(GPU每秒可渲染5帧)的用户尝试采用传统游戏时,渲染性能显著下降。平均视图切换渲染延迟为300ms,平均刷新率仅为5 fps左右。
以客户端为中心的视频流游戏在核心网络中面临性能瓶颈,因为它必须向每个客户端单播帧(消耗超过 1Tb的核心网络流量)。帧丢失率很高,因此客户端的实际帧率仅为约7 fps。为了缓解频繁的丢帧问题,我们采用前向纠错(FEC),使得每个帧包含在该帧被渲染之前到达的所有事件。然而,即使使用该技术,渲染延迟仍然较高(对于视角变化和游戏事件均为>1s),因为事件只能通过下一个成功传递的帧进行传递。我们注意到,由于回传链路上的复用,实际场景中的性能可能更差。
EC+可以提供与传统游戏(台式机)相似的事件更新延迟(视图切换事件为< 30ms,游戏事件约100ms)和刷新率(56fps),因为边缘云中的渲染器性能强大且与客户端距离较近。由于非游戏事件的更新延迟如此之低,我们的架构能够很好地支持VR应用,使用户在发生非游戏事件时获得即时反馈(e.g.,看向另一个方向)。尽管与传统游戏相比,我们的方案在边缘网络中消耗了更多的流量 (>10Tb),但我们认为这是可行且稳定的,因为互联网服务提供商通常对边缘网络具有完全控制权,以确保服务质量。
6.2 边缘放置验证
为了验证我们的边缘选择方案,我们进行了一系列基于合成拓扑和少量用户的模拟。
6.2.1 仿真设置
我们考虑一个 7× 7网格(如图 6a所示),其中24个最外层网格单元中的每一个代表一个接入点以及连接到该接入点的用户。我们认为所有边缘云位于最外层圆圈旁边的灰色网格单元中,而中心云位于中央网格单元中。我们假设链路延迟与两个端点之间的距离成正比,而其带宽与距离成反比。
6.2.2 单玩家场景的验证
我们首先使用单个玩家并改变迁移成本来验证我们的算法。我们注意到,迁移成本因游戏而异,取决于游戏世界大小。
我们首先考虑一种简单的移动模式,玩家沿最外圈顺时针从一个网格单元移动到下一个网格单元。图6a显示,当迁移成本较小时,放置算法始终尝试在玩家移动时将服务放置在最近的边缘云上。在此示例中,玩家位置变化了24次,相应地服务位置变化了16次。当迁移成本增加时,算法决定减少迁移频率(见图6b)。例如,当迁移成本约为当前传输成本的两倍时——在此情况下,传输延迟使每个时隙的帧大小翻倍——玩家位置变化 24次时,服务位置仅变化4次。当我们进一步提高迁移成本时,玩家总共发生24次位置变化,而服务位置仅有两次变化(见图6c)。最后,当迁移成本变得过大(超过当前传输成本四倍以上)时,该算法根本不进行迁移(图中未显示)。
接下来,我们考虑一种不同的玩家移动模式:在每个时隙,玩家以60%的概率向顺时针方向的下一个网格单元移动,以10%的概率向逆时针方向的下一个网格单元移动,并以30%的概率停留在当前单元格。这种新的移动模式导致了不同的迁移决策(如图6d所示)。此处,我们使用与图6b中相同的迁移成本。结果表明,由于玩家存在向后移动的概率,放置算法变得更加保守。尽管仍然有4个不同的服务位置,但位置切换比图6b晚了一个时隙发生。
在所考虑的单玩家场景中,算法结果符合我们的预期。因此,我们验证了其在单玩家情况下的正确性。
6.2.3 多玩家场景的验证
接下来,我们在考虑同一 7× 7 网格拓扑中的两名玩家时,验证我们的算法。这里我们改变了两名玩家之间的距离。图7a显示,当两名玩家彼此靠近时(即他们分别位于2号和5号单元格),我们的算法决定将他们放置在同一边缘云上,以利用共享游戏世界。在图7b中,当考虑迁移到何处时,我们的算法尝试将一名玩家迁移到正在托管其他玩家的边缘云,以复用游戏世界并降低迁移成本。在此示例中,即使原始玩家(位于6号单元格)即将离开红色边缘云,我们的算法仍将23号单元格的玩家迁移到红色边缘云。
6.2.4 最优放置方案与启发式放置方案在多玩家情况下的比较
接下来,我们在 7× 7网格拓扑中拥有两名玩家时,比较最优放置方案vs.启发式放置方案。在每个时隙,玩家顺时针移动到下一个网格单元格,或停留在同一网格单元格,并以各自1/3的概率逆时针移动到下一个网格单元格。图8报告了以下方案的迁移成本结果:(1) MDP‐最优,即全局最优部署;(2)MDP‐MMLF, 即启发式MDP部署方案,我们优先部署具有最大迁移可能性的用户;(3)MDP‐随机,即启发式MDP部署方案,我们随机排序玩家;(4)始终,即始终迁移方案;(5)从不,即从不迁移方案。
在这五种方案中,MDP‐最优的性能最佳,但同时也消耗最多的内存和CPU资源。在 24 × 24个客户端位置和 16 × 16个边缘云位置的情况下,为两名玩家计算迁移决策需要超过1分钟。当玩家数量较多时,计算开销将高得无法接受。我们还观察到,所有三种基于 MDP的解决方案相比简单的始终迁移或从不迁移方案,性能要好得多。最后,我们发现所提出的 MDP‐MMLF比MDP‐随机更接近最优解。
6.2.5 评估运行时开销
最后,我们测量了 MDP‐MMLF实现的三个版本的运行时开销:(1)原始版本, (2)优化版本。我们的硬件平台包含一台Intel Core i7‐4790 CPU,主频为3.60GHz [61],,运行Ubuntu 14.04。
在我们的实验中,我们考虑了1个用户,并改变了边缘云和客户端位置的数量。图9显示了所有三种实现的计算时间。结果表明,原始版本的执行时间随着边缘/客户端位置数量的增加而快速上升(其内存消耗也相应增加)。优化版本在相同的边缘/客户端数量下具有低得多的执行时间。我们认为该版本可用于用户数量更多的场景,因为在实际网络中,用户通常可以随时使用 ∼10个可能的边缘云。
7 结论
本文中,我们强调了虚拟现实大型多人在线游戏( VR‐MMOGs)面临的主要挑战,并提出了两种解决方案。EC+架构将所需处理任务无缝分布在用户设备、边缘云和中心云之间,以实现超低延迟响应、高频刷新以及支持大量并发玩家。为配合该架构,我们的游戏服务部署算法通过将玩家的服务动态放置在性能最优的边缘云上,从而最大化所有玩家的游戏性能。最后,我们进行了详细仿真研究,以评估所提出的边缘云辅助的游戏架构和动态服务放置算法。结果表明,该方法是支持虚拟现实大型多人在线游戏的一种可行方案。

















 265
265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









