




 探讨CVPR2020论文,介绍无监督强化学习如何克服深度学习数据效率低和迁移能力弱的问题,通过meta-learning使模型在少量训练环境下掌握视觉导航技能。
探讨CVPR2020论文,介绍无监督强化学习如何克服深度学习数据效率低和迁移能力弱的问题,通过meta-learning使模型在少量训练环境下掌握视觉导航技能。
链接:CVPR 2020 | 用无监督强化学习方法来获得迁移能力
CVPR2020文章---无监督强化学习获得迁移能力
引出问题
首先在3d仿真环境中给agent指定一个自然语言的输入,比如冰箱,agent需要在环境中完整一系列原子动作,从而找到目标,需要完成这个任务,视觉导航能力必不可少。
深度强化学习任务存在的问题
1、通常是data inefficient,需要大量的训练数据;
2、就算是两个相似的任务,模型都需要从头开始训练。
人类之所以能够从广泛的任务中快速学习,是因为可以学到很多meta-skills,这些meta-skills通常具有迁移能力。具体可以是,直线行驶,绕开障碍物等。
我们的目标
关注视觉导航在少量训练环境中的应用;
设计一种无监督的学习方法可以让机器可以掌握这些mata-skills,从而只提供少量样本让机器人将meta-skills迁移到视觉导航的任务中来。
meta-learning
什么是meta-learning
是所谓的learning to learning
不直接直接优化在单个任务上的性能;而是优化模型能够快速学习任务的能力。
主要分为三种类型:

这里主要看第三种类型,基于梯度的方法。
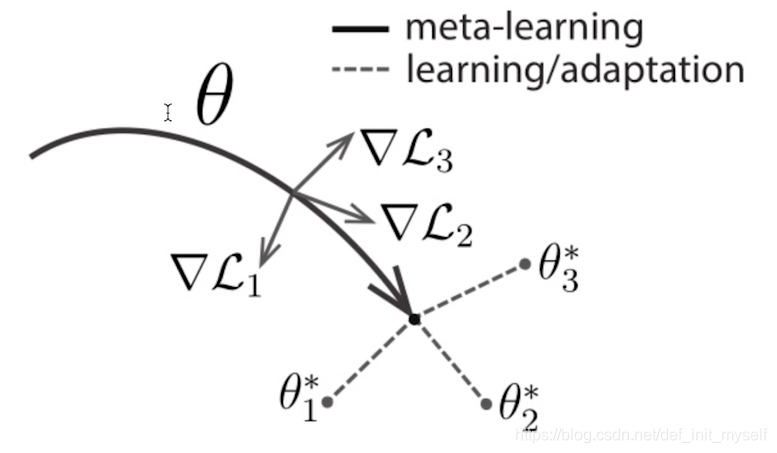
基于梯度的方法
需要找到模型的初始化,可以让模型快速适应新的任务。
th
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3022
3022

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









