




 微生物组学研究揭示了微生物对人体健康的关键作用,但商业化进程缓慢,面临科学理解、模型验证和转化难题。文章探讨了微生物组研究的现状、临床前模型的局限、微生物组与疾病关联的深入研究需求,以及如何从相关性走向因果关系。同时,提出在肠道之外,其他身体部位的微生物组研究也日益重要。微生物组疗法进入临床需要考虑药物动力学、药效学和个性化治疗策略。
微生物组学研究揭示了微生物对人体健康的关键作用,但商业化进程缓慢,面临科学理解、模型验证和转化难题。文章探讨了微生物组研究的现状、临床前模型的局限、微生物组与疾病关联的深入研究需求,以及如何从相关性走向因果关系。同时,提出在肠道之外,其他身体部位的微生物组研究也日益重要。微生物组疗法进入临床需要考虑药物动力学、药效学和个性化治疗策略。
微生物组学研究的机遇与挑战

导读
在过去的几年中,微生物组的研究大大地改变了我们对人类生物学的理解。人体内存在着数以万亿计的微生物,远高于人体细胞的数目,这些微生物对人体健康不可或缺。随着微生物组学研究的深入,人们逐渐了解微生物如何介导消化和疾病过程到发现与癌症,帕金森氏症,自闭症和抑郁症相关的新观点。微生物组学研究的兴起,似乎为人类对疾病的认知打开了另一扇大门。虽然微生物组学研究火热,为什么商业化产品的推出却少之又少且疗效参差不齐呢?微生物组学商业化究竟遇到了什么样的挑战?
文献信息
- 英文标题: Translating microbiome futures
- 中文标题:微生物组学转化研究的未来
- 作者: Gaspar Taroncher-Oldenburg, Susan Jones, Martin Blaser, Richard Bonneau, Peter Christey, José C Clemente, Eran Elinav, Elodie Ghedin, Curtis Huttenhower, Denise Kelly, David Kyle, Dan Littman, Arpita Maiti, Alexander Maue, Bernat Olle, Leopoldo Segal, Johan E T van Hylckama Vlieg & Jun Wang
- 期刊: Nature Biotechnology; 影响因子:【35.724】
- Doi号: https://doi.org/10.1038/nbt.4287
背景
人类微生物组研究开发治疗性或营养性产品所提供的机遇与解密其背后的科学机理的艰巨任务相当。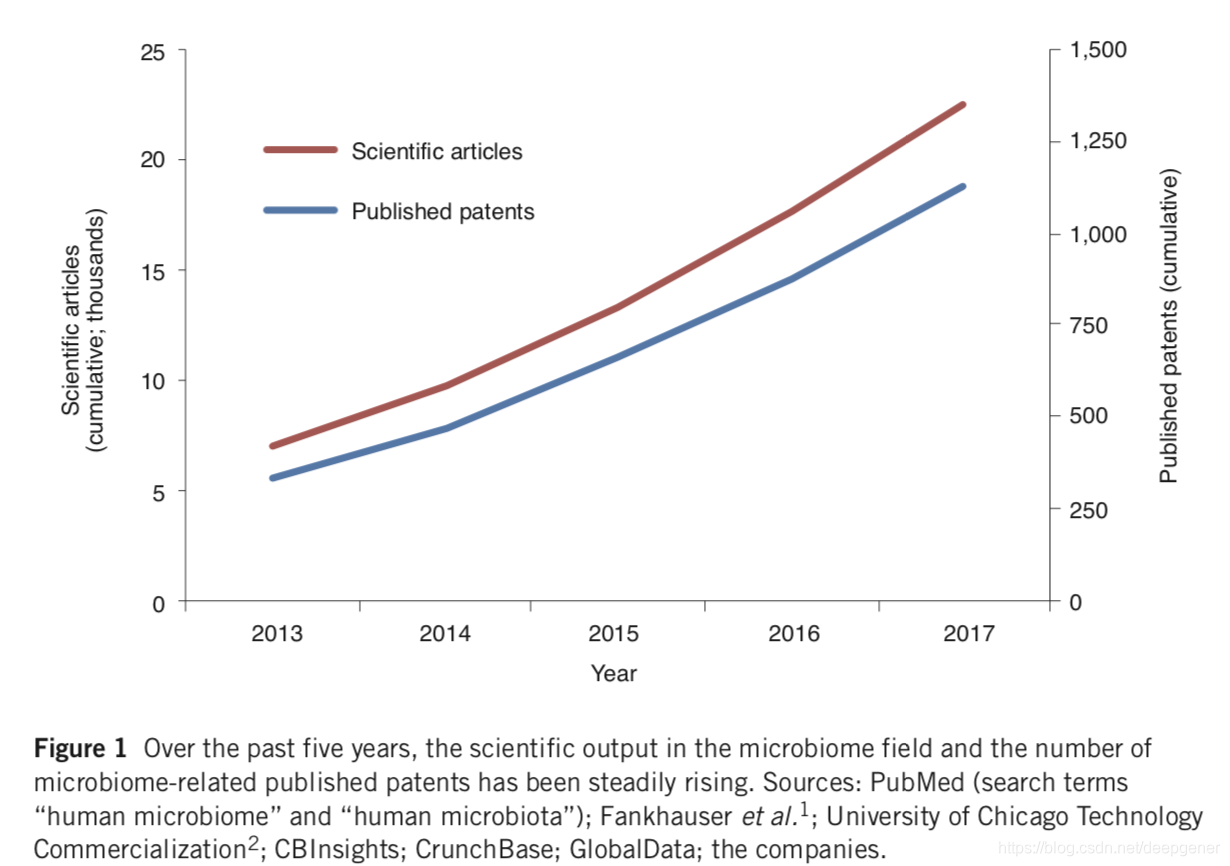 研究人员目前正在深入研究微生物组与人类健康问题之间的关联(Fig.1)
研究人员目前正在深入研究微生物组与人类健康问题之间的关联(Fig.1) 。微生物组学与人类健康问题的之间的联系也引起了食品,生物技术,制药和投资者群体的广泛兴趣。然而,迄今为止,还没有美国食品药物管理局批准可用于人类的微生物组疗法的产品诞生。会议组织者Global和自然生物技术(Box1)最近召开了圆桌会议,讨论人类微生物组研究的现状及其在医疗中的转化问题
。微生物组学与人类健康问题的之间的联系也引起了食品,生物技术,制药和投资者群体的广泛兴趣。然而,迄今为止,还没有美国食品药物管理局批准可用于人类的微生物组疗法的产品诞生。会议组织者Global和自然生物技术(Box1)最近召开了圆桌会议,讨论人类微生物组研究的现状及其在医疗中的转化问题
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









