




一、理论
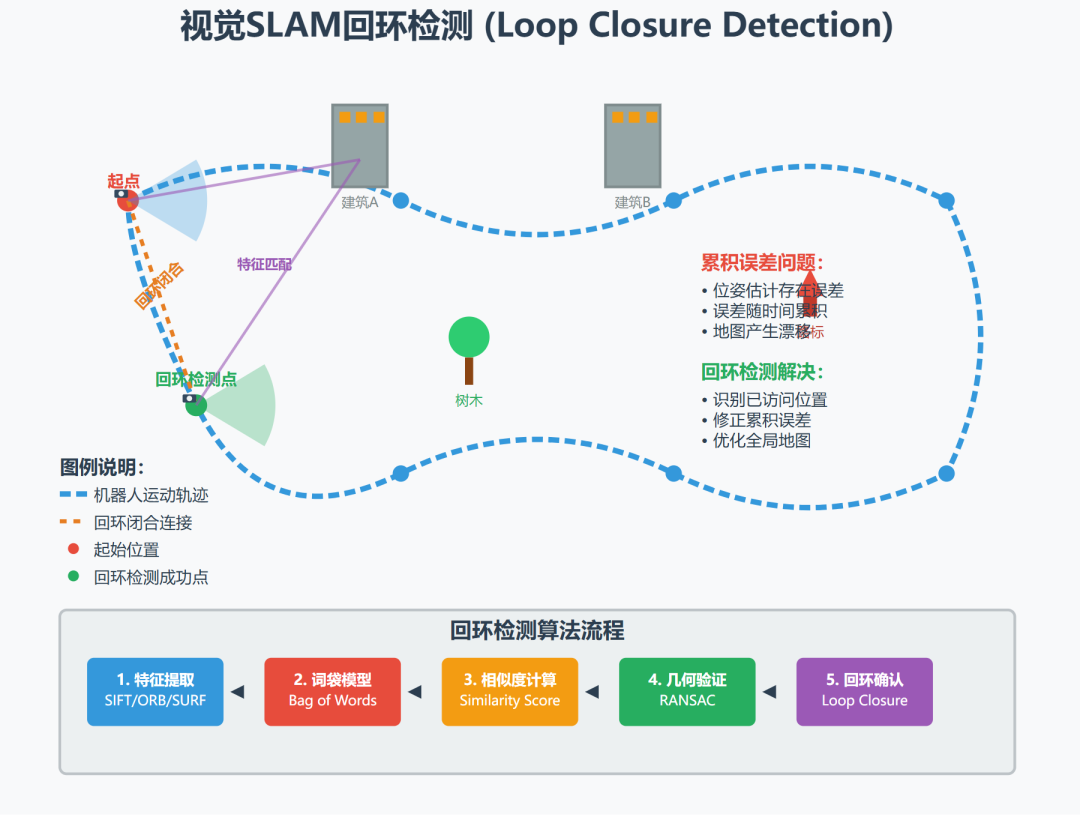
1. 回环检测的意义
我们来详细探讨一下视觉SLAM中回环检测(Loop Closure Detection)的意义。
简单来说,回环检测是视觉SLAM系统中的一个关键模块,它负责回答一个问题:“我以前来过这个地方吗?”
如果能正确回答这个问题,将给整个SLAM系统带来质的飞跃。它的意义主要体现在以下几个核心方面:
1. 消除累积误差(最核心的意义)
这是回环检测最根本、最重要的作用。
问题所在:
SLAM系统通过连续处理图像来估计相机的位姿(位置和姿态),这个过程被称为“里程计”(Odometry)。无论是视觉里程计(VO)还是视觉惯性里程计(VIO),相邻帧之间的位姿估计都存在微小的误差。随着相机不断移动,这些微小的误差会像滚雪球一样不断累积,导致所谓的 “累积漂移”(Accumulated Drift)。
一个直观的例子:
想象一下,你闭着眼睛在操场上走一圈。你每走一步,都对自己当前的位置做一个估计。即使你每一步的估计都很准,但当你走完一圈回到起点时,你心目中“终点”的位置很可能已经偏离了真正的起点。这就是累积漂移。
回环检测的作用:
当相机回到一个曾经经过的位置时,回环检测模块能够识别出“嘿,当前看到的场景和我之前在A点看到的场景是同一个地方!”。
这个识别提供了一个强大的 “全局约束”(Global Constraint)。它相当于在时间上相距很远(比如第10帧和第1000帧)的两个位姿之间建立了一条“零漂移”的连接。系统得知,第10帧和第1000帧的真实物理位置是相同的。
利用这个信息,系统可以进行图优化(Pose Graph Optimization),将整个轨迹和地图进行一次全局调整,把累积的误差“摊平”到整个路径上,从而消除漂移。
2. 实现地图的全局一致性
漂移不仅影响定位,更会破坏地图的质量。一个带有严重漂移的地图是不一致的、扭曲的,甚至会出现“鬼影”(同一个物体在地图上出现两次)。
通过回环检测和后续的图优化,可以确保地图的全局一致性(Global Consistency)。这意味着:
地图不会自我矛盾。
地图的拓扑结构是正确的(例如,一个闭合的走廊在地图上也应该是闭合的)。
地图的几何尺寸在全局范围内更加准确。
一个全局一致的地图对于导航、路径规划等高级任务至关重要。
3. 提升定位精度(Relocalization)
回环检测技术不仅用于“闭环”,还能用于 “重定位”(Relocalization)。
场景:
- 跟踪丢失(Tracking Lost):
当相机移动过快、场景中出现剧烈光照变化或动态物体过多时,SLAM系统可能会跟丢,不知道自己在哪。
- 系统初始化:
当一个带有预构建地图的机器人被放置在地图的任意位置时,它需要先确定自己的初始位姿。
回环检测如何帮助:
在这种情况下,系统可以利用当前看到的图像,在整个历史地图数据库中进行搜索(这本质上就是回环检测的过程)。一旦找到一个匹配度极高的历史位置,系统就能瞬间“找回”自己的位置,恢复跟踪。这大大增强了SLAM系统的鲁棒性(Robustness)。
4. 构建可长期维护的地图
对于需要在同一环境中长期运行的机器人(如扫地机器人、仓库机器人),回环检测是必不可少的。
机器人每次启动任务时,可以通过重定位在现有地图上继续工作,而不是每次都重新建图。
在日复一日的工作中,机器人会反复经过相同的区域。回环检测能不断地将新的观测信息融合到旧的地图中,持续优化和更新地图,使其越来越精确。
没有回环检测,地图会因为不断累积的漂移而最终变得无法使用。
回环检测的工作流程简述
为了更好地理解其意义,我们简单看一下它是如何工作的:
- 候选帧检测:
当相机捕获新的一帧时,系统不会去和所有历史帧一一比较(计算量太大)。而是使用高效的**词袋模型(Bag of Words, BoW)**等方法,将图像转换成一个紧凑的向量。然后,在历史数据库中快速检索出视觉上最相似的几个“候选帧”。
- 几何验证:
视觉相似不代表是同一个地方(比如两面相似的白墙)。因此,需要进行几何验证。通过匹配当前帧和候选帧之间的特征点,计算它们之间的相对位姿。如果能找到一个具有足够多匹配点(inliers)的稳定变换关系,就确认这是一个有效的回环。
- 闭环融合/图优化:
一旦确认回环,就在位姿图中添加一条回环边(Loop Edge),然后触发后端优化器(如g2o, Ceres)对整个轨迹和地图进行全局优化。
总结
总而言之,回环检测是视觉SLAM从一个只能进行局部、短时定位和建图的“里程计”系统,蜕变为一个能够构建全局一致、大规模、高精度地图的完整SLAM系统的关键。
它就像一个“上帝之眼”,能跳出时间和空间的限制,发现那些被累积误差掩盖的真相,从而校正整个系统,使其更加准确、鲁棒和实用。没有回环检测的SLAM系统,其应用场景会受到极大的限制。
2. 准确率和召回率计算
我们来详细讲解一下在回环检测中,准确率(Precision)和召回率(Recall)是如何计算和理解的。
这两个指标是评估回环检测算法性能最核心的工具,它们帮助我们量化算法的可靠性和效率。
1. 基础概念:四个基本分类
为了计算准确率和召回率,我们首先需要将回环检测的每一次“决策”分为四种情况。这里的“决策”是指,对于任意一个当前帧和历史候选帧的组合,算法给出的判断。
假设我们拥有**“地面真实值”(Ground Truth)**,即我们通过某种方式(如高精度GPS、人工标注)确切地知道哪些帧之间构成了真正的回环。
真阳性 (True Positive, TP):
- 情况:
两个帧确实是同一个地方(是真回环),算法也成功检测出了这是一个回环。
- 解读:
这是我们想要的结果,检测正确。
- 情况:
假阳性 (False Positive, FP):
- 情况:
两个帧实际上不是同一个地方(不是回环),但算法错误地认为它们是一个回环。
- 解读:
这是最危险的错误。一个错误的全局约束会导致地图严重扭曲,甚至系统崩溃。我们称之为“误报”。
- 情况:
假阴性 (False Negative, FN):
- 情况:
两个帧确实是同一个地方(是真回环),但算法没有检测出来。
- 解读:
这是一次“错过的机会”。算法没能利用这个回环来消除累积误差,导致漂移继续存在。我们称之为“漏报”。
- 情况:
真阴性 (True Negative, TN):
- 情况:
两个帧实际上不是同一个地方,算法也正确地判断它们不是回环。
- 解读:
这是算法在绝大多数情况下的正常、正确的行为。
- 情况:


5. 准确率与召回率的权衡 (Trade-off)
在实践中,准确率和召回率往往是相互制约的。
如果我们把判断回环的门槛设得非常高(例如,要求BoW相似度得分极高,并且几何验证的内点数非常多),那么FP会减少,准确率会提高。但同时,一些不是那么“完美”的真回环可能会被拒绝,导致FN增加,召回率会下降。
反之,如果我们降低门槛,算法会变得更“敏感”,能找出更多潜在的回环,FN会减少,召回率会提高。但同时,误判的风险也增加了,FP会增加,准确率会下降。
这种权衡关系可以用P-R曲线(Precision-Recall Curve)来可视化。曲线下的面积(Area Under Curve, AUC)越大,说明算法的综合性能越好。对于SLAM来说,我们通常追求在保证接近100%准确率的前提下,尽可能地提高召回率。
总结
指标 | 计算公式 | 关注点 | 在SLAM中的重要性 |
|---|---|---|---|
| 准确率 (Precision) | TP / (TP + FP) | 检测结果有多可信?(别误报) | 极高优先级 。低准确率是致命的,会导致地图被毁。 |
| 召回率 (Recall) | TP / (TP + FN) | 发现能力有多强?(别漏报) | 高优先级 。高召回率是消除漂移、提升精度的关键。 |
理解并计算这两个指标,是评价和优化回环检测算法性能的基础。
3. 回环检测的方法
回环检测的目标是在保证 高召回率(Recall) 和 高精确率(Precision) 的前提下,高效地完成任务。
- 高召回率
:不错过任何一次真正的回环。
- 高精确率
:不把不是回环的地方误判为回环(避免错误的全局优化,这可能是灾难性的)。
为了实现这一目标,回环检测通常被设计为一个多阶段的流程,从粗略的筛选到精细的验证。主流方法可以概括为以下流水线:
回环检测标准流程:候选帧选择 -> 几何验证 -> 闭环融合
第一阶段:候选帧选择 (Candidate Selection)
这是回环检测的第一步,也是效率的关键。目标是从成千上万的历史关键帧中,快速地找出几个与当前帧在视觉上最相似的候选帧。如果每次都将当前帧与所有历史帧进行暴力比较,计算量是无法承受的。
方法1:词袋模型 (Bag of Words, BoW) - 最经典、最主流的方法
词袋模型是目前应用最广泛的方法,尤其是在以ORB-SLAM系列为代表的开源方案中。它借鉴了自然语言处理中的思想,将“图像”类比为“文档”,将图像中的“视觉特征”类比为“单词”。
核心流程:
离线构建字典 (Vocabulary Training):
从大量不同场景的图像数据集中提取海量的局部特征(如SIFT, SURF, ORB)。
使用聚类算法(如K-Means)对这些特征进行聚类。每一个聚类中心就代表一个“视觉单词(Visual Word)”。
所有这些“视觉单词”的集合就构成了“字典(Vocabulary)”。一个实用的字典通常包含10万到100万个单词。
在线查询 (Online Query):
- 图像转为BoW向量:
对于一个新的关键帧,提取其所有局部特征。然后,将每个特征匹配到字典中最近的那个“视觉单词”。最后,统计该帧图像中每个“视觉单词”出现的频率,形成一个稀疏的词袋向量(BoW Vector)。这个向量就代表了这张图像的内容。
- 相似度评分:
当需要进行回环检测时,计算当前帧的BoW向量与数据库中所有历史关键帧的BoW向量之间的相似度得分(通常用L1范数或余弦相似度)。
- 高效索引:
为了加速查询,通常会使用“倒排索引(Inverted Index)”。该结构存储了每个“视觉单词”出现在哪些历史关键帧中。这样,我们只需要关注那些与当前帧共享较多相同“单词”的历史帧,而无需遍历整个数据库。
- TF-IDF加权:
为了增加区分度,通常会使用TF-IDF(Term Frequency–Inverse Document Frequency)对BoW向量进行加权。核心思想是:一个在很多图像中都出现的常见特征(如白墙上的一个点)权重较低,而一个只在少数图像中出现的稀有特征(如一个独特的雕塑)权重更高。
优点:
速度极快,可以实现实时查询。
不受视角变化和旋转的影响。
技术成熟,有非常优秀的开源实现(如
DBoW2,DBoW3)。
缺点:
对光照变化和场景外观的剧烈变化比较敏感。
字典的质量对最终效果影响很大。
不包含特征点的几何信息。
方法2:基于深度学习的方法
近年来,随着深度学习的发展,研究者们开始使用卷积神经网络(CNN)来提取图像的全局描述子(Global Descriptor),用于场景识别。
核心流程:
- 模型训练:
训练一个CNN模型,其任务是输入一张图像,输出一个紧凑的浮点数向量(如256维或4096维)。训练的目标是让在物理上相近的地点所拍摄的图像,其输出的向量在向量空间中也相近;反之,物理上遥远的地点,其向量也应该遥远。
- 在线查询:
对于每个新的关键帧,通过预训练好的CNN模型提取其全局描述子向量。
通过计算当前帧向量与历史帧向量之间的欧氏距离或余弦相似度,来寻找最相似的候选帧。
可以使用一些近似最近邻搜索算法(如FAISS, Annoy)来加速查询。
代表性工作:
- NetVLAD:
一个非常著名的工作,通过一个可微的“VLAD层”来聚合CNN的局部特征,生成对视角变化非常鲁棒的全局描述子。
- DenseVLAD, AP-GeM等:
NetVLAD的各种改进版本。
优点:
对光照、天气、季节等外观变化具有更强的鲁棒性。
端到端学习,可能比手工设计的BoW模型效果更好。
缺点:
需要大量的标注数据进行训练。
计算通常需要GPU支持,计算成本高于BoW。
泛化能力依赖于训练集的多样性。
第二阶段:几何验证 (Geometric Verification)
第一阶段选出的候选帧仅仅是“看起来像”,但可能出现误判(比如两个长得一模一样的办公室走廊)。因此,必须通过几何关系来做最终确认。
核心流程:
特征匹配: 在当前帧和候选帧之间进行局部特征匹配(如ORB特征的暴力匹配)。
模型估计与验证: 使用RANSAC(Random Sample Consensus,随机采样一致性) 算法来估计两帧之间的几何变换模型,并剔除误匹配点。
- 2D-2D 验证:
如果只有两张图像的信息,可以估计它们之间的本质矩阵(Essential Matrix)或基础矩阵(Fundamental Matrix)。然后计算支持这个模型的内点(Inliers)数量。
- 3D-2D 验证 (PnP求解):
这是更常用、更可靠的方式。因为SLAM系统在构建地图时,已经存储了历史关键帧中特征点对应的3D地图点。所以,当候选帧被选出时,我们已经知道了它上面特征点的3D坐标。验证过程就变成了:将当前帧的2D特征点与候选帧的3D地图点进行匹配,然后使用PnP(Perspective-n-Point)算法来求解一个相机的位姿。RANSAC被用来寻找能够最大化内点数量的PnP解。
- 图像转为BoW向量:
判定: 如果通过RANSAC找到的内点数量超过一个设定的阈值(例如30个点),并且计算出的相对位姿误差在合理范围内,就认为这次回环检测成功了。
第三阶段(附加步骤):时序一致性检验 (Temporal Consistency Check)
为了进一步提高精确率,很多现代SLAM系统(如ORB-SLAM2/3)还引入了时序一致性检验。
核心思想: 一个真正的回环不太可能只发生在一瞬间。如果当前帧
k与历史帧i形成了回环,那么接下来的几帧k+1,k+2... 也很可能与i附近的帧i+1,i+2... 形成回环。做法: 系统不会在检测到一次匹配后就立即宣布回环,而是会等待。只有当连续几帧都与同一个区域的历史帧成功匹配时,才最终确认这是一个稳定、有效的回环。这极大地过滤掉了那些偶然发生的、短暂的错误匹配。
第四阶段:闭环融合与优化 (Loop Fusion and Optimization)
一旦回环被最终确认,系统就会执行以下操作:
- 计算回环约束:
精确计算当前帧与回环帧之间的相对位姿变换(通常是一个
Sim(3)变换,包含旋转、平移和尺度)。这个变换就构成了一个新的回环约束。 - 位姿图优化(Pose Graph Optimization):
将这个回环约束作为一条新的边,添加到后端的位姿图中。这条边连接了两个在时间上相距很远的节点。然后,触发全局的图优化算法(如g2o, Ceres Solver),以这个新的强约束为基准,对整个轨迹上的所有关键帧位姿和地图点进行调整,从而消除累积误差。
- 地图点融合:
将回环处的地图点进行融合和更新,剔除冗余点,确保地图的一致性。
总结对比
特性
词袋模型 (BoW)
深度学习方法 (e.g., NetVLAD)
基本原理 局部特征聚类,统计视觉单词频率
CNN提取图像全局描述子向量
鲁棒性 对视角变化鲁棒,对光照、外观敏感
对视角、光照、季节变化都较鲁棒
计算成本 低,CPU友好,查询速度快
高,通常需要GPU,查询速度较慢
依赖 需要预先训练好的通用字典
需要针对性的训练数据和模型
几何信息 不包含,纯视觉相似度
不包含,纯视觉相似度
应用 ORB-SLAM系列 ,VINS-Mono等,工业界应用广泛
学术研究热点,在长期定位、机器人重定位领域有优势
总的来说,一个优秀的回环检测模块是多种方法的结合,通过层层筛选,最终以极高的置信度找到真正的回环,为构建全局一致的地图和实现高精度定位提供保障。
4. 词袋模型 与 字典
这是一个非常核心且重要的概念。我们用一个生动形象的比喻来彻底讲清楚**词袋模型(Bag of Words, BoW)和字典(Vocabulary)**的关系。
想象一下,你想判断两篇英文文章的主题是否相似。
字典(Vocabulary)是什么?
它就是一本真正的《牛津英文字典》。这本字典是预先编纂好的,包含了所有可能出现的单词(比如 "apple", "economy", "love", "politics" 等)。它是静态的、权威的、作为基础参考的存在。词袋模型(Bag of Words Model)是什么?
它是一种描述文章内容的方法。具体做法是:
拿来一篇文章。
彻底忽略文章的语法、句子顺序、段落结构。
准备一个“袋子”(Bag)。
阅读文章,每遇到一个在《牛津字典》里存在的单词,就在袋子里放一个对应的标签。
最终,你得到一个“袋子”,里面装着这篇文章所有单词的清单和它们出现的次数。比如:{"economy": 15次, "politics": 10次, "sports": 0次, ...}。
这个“装满单词频率的袋子”,就是这篇文章的词袋表示(BoW Representation)。通过比较两篇文章的“袋子”内容,如果它们都高频出现了 "economy" 和 "politics",而很少出现 "sports",你就可以快速判断这两篇文章的主题很可能都是关于财经政治的。
现在,我们把这个比喻无缝对接到视觉SLAM中。
字典 (Vocabulary) 在视觉SLAM中
在视觉SLAM中,字典不再是英文单词的集合,而是一个**“视觉单词”(Visual Words)的集合**。
- 本质:
一个预先计算好的、巨大的、有代表性的视觉特征描述子的数据库。
- 如何创建(离线训练):
- 收集数据:
从成千上万张各种场景(室内、室外、街道、办公室等)的图片中,提取数百万甚至上亿个局部特征(如ORB, SIFT, SURF的特征描述子)。
- 聚类:
使用像K-Means这样的聚类算法,将这上亿个特征描述子进行分组。比如,所有看起来像“尖锐墙角”的特征被聚为一类,所有看起来像“圆形门把手”的特征被聚为另一类。
- 生成视觉单词:
每个聚类的中心点(Centroid)就被定义为一个**“视觉单词”**。这个中心点本身也是一个特征描述子,它代表了这一类视觉模式。
- 形成字典:
所有这些“视觉单词”(聚类中心)的集合,就构成了我们的视觉字典。一个典型的字典可能包含10万个视觉单词。这个字典通常以一个文件的形式存在(例如,在ORB-SLAM中著名的
ORBvoc.txt文件)。
所以,视觉字典是一个“标准参照物”,它定义了世界上可能存在哪些基础的、可识别的视觉模式。
词袋模型 (Bag of Words Model) 在视觉SLAM中
词袋模型是一种用“视觉字典”来表示一张图像内容的方法。
- 本质:
一种将复杂图像转换成一个简单、固定长度的向量(或直方图)的数学模型。
- 如何工作(在线使用):
- 加载字典:
SLAM系统启动时,首先加载那个预先训练好的视觉字典文件。
- 处理新图像:
当系统捕获一个新的关键帧时,它会从这张图像中提取出几百个局部特征(比如500个ORB特征)。
- 特征量化:
对于图像中的每一个特征,系统都会在字典中找到与它最相似的那个“视觉单词”。这个过程就像查字典,把一个具体的特征“归类”到字典里最接近的那个标准模式上。
- 生成BoW向量:
系统创建一个长度与字典大小相等的向量(比如10万维的向量)。然后统计每个“视觉单词”在这张图像中出现了多少次,并填入向量的对应位置。例如,如果字典里的第54321号视觉单词(可能代表某种窗户角点)在这张图中出现了3次,那么BoW向量的第54321个元素就是3。
所以,词袋模型将一张充满像素的、复杂的图像,变成了一个高维但稀疏的、标准化的数字向量。这个向量就是这张图像的“指纹”。
关系总结与对比
特性
字典 (Vocabulary)
词袋模型 (Bag of Words, BoW)
本质 基础参照物 ,是所有“视觉单词”的集合。
一种表示方法 ,用于描述一张图像的内容。
形态 一个巨大的、预先计算好的数据库(通常是一个文件)。
一个描述单张图像的、固定长度的稀疏向量/直方图。
创建方式 离线训练 ,通过对海量数据进行聚类得到。
在线计算 ,通过查询字典来实时生成。
作用 定义了“什么是视觉单词”,为BoW模型提供基础。
将图像转换为可快速比较的数字向量,用于回环检测的候选帧筛选。
比喻 《牛津英文字典》
统计一篇文章中每个单词出现次数的方法。
结论
字典是基础,词袋模型是应用。
没有字典,我们就不知道“视觉单词”有哪些,也就无法进行后续的描述和比较。
有了字典后,词袋模型提供了一种高效的方法,将每一张图像转换成一个标准化的“BoW向量”。SLAM系统通过比较当前帧的BoW向量和历史关键帧的BoW向量的相似度,就可以极快地(通常是毫秒级)找出那些在视觉上最相似的候选帧,从而启动后续更精确的几何验证。这个“字典+词袋模型”的组合,是经典视觉SLAM实现高效回环检测的基石。
5. 相似度计算
我们来深入探讨视觉SLAM中一个非常关键的计算环节:如何计算两张图像(由它们的BoW向量表示)的相似度。
这是回环检测候选帧筛选的核心。我们的目标是,给定当前帧的BoW向量和历史数据库中所有关键帧的BoW向量,快速找到相似度最高的那个。
我们先从一个简单的例子入手,然后引入更高级、更实用的方法。
场景设定:一个微型字典
假设我们的视觉字典非常小,只有6个“视觉单词”:
w1: 代表“尖锐的墙角”
w2: 代表“圆形的窗户”
w3: 代表“办公椅的滚轮”
w4: 代表“显示器屏幕”
w5: 代表“盆栽绿植”
w6: 代表“普通白墙上的一个点”
现在,我们有三张图像,并已将它们转换成了BoW向量(这里我们先用最简单的词频来表示):
- 图像A (办公室场景):
v_A = [4, 2, 8, 2, 0, 50] (4个墙角, 2个窗户, 8个椅轮, 2个屏幕, 0个绿植, 50个白墙点)
- 图像B (同一个办公室,不同角度):
v_B = [3, 2, 7, 3, 1, 45] (看起来和A很像,可能是个回环)
- 图像C (公园场景):
v_C = [0, 0, 0, 0, 15, 10] (0个办公室元素, 15个绿植, 10个白墙点)
我们的任务是,通过计算,得出“A和B很相似”以及“A和C不相似”的结论。


6. 相似性评分
这是一个非常关键的实践性问题。我们已经知道了如何计算两个BoW向量的“距离”(如L1范数),但如何将这个“距离”转换成一个有意义的、可用于决策的**“相似性评分”(Similarity Score)**呢?
这涉及到归一化、阈值设定和策略选择,是回环检测从理论走向实践的核心环节。我们以ORB-SLAM系列中的实现为例,因为它非常经典且有效。
1. 原始距离分数的问题
直接使用L1范数(
Σ|V_A(i) - V_B(i)|)作为最终评分有一个问题:它不具有可比性。例子:
- 图像A
:场景复杂,提取了1000个特征点。它的BoW向量
V_A中有很多非零项。 - 图像B
:场景简单,只提取了100个特征点。它的BoW向量
V_B中非零项很少。
假设现在有一张与B非常相似的图像C。
Score(B, C)的L1距离值天生就会比较小,因为它们的向量本身就“短”。而A与另一张相似图像D的L1距离Score(A, D)可能会很大,仅仅因为它们向量的“尺度”更大。我们无法设定一个固定的L1距离阈值来判断所有情况。我们需要一个与尺度无关的、归一化的评分。

7. 关键帧的处理
这是一个非常核心的问题。**关键帧(Keyframe)**是视觉SLAM系统中信息管理和计算优化的基石。可以说,如何高效地处理关键帧,直接决定了SLAM系统的性能、精度和可扩展性。
我们将从以下几个方面来全面解析关键帧的处理:
- 为什么需要关键帧?
(The "Why")
- 何时创建新的关键帧?
(The Selection Strategy)
- 关键帧创建时的处理流程是什么?
(The Processing Pipeline)
- 关键帧创建后如何被使用和管理?
(The Usage and Management)
1. 为什么需要关键帧?—— 解决冗余与效率问题
SLAM系统接收的视频流通常是每秒30帧或更多。如果对每一帧都进行完整的处理(特征提取、匹配、后端优化),会带来两个致命问题:
- 计算量爆炸:
实时处理是不可能的。后端优化的规模会随着帧数线性增长,很快就会崩溃。
- 信息高度冗余:
相邻的视频帧之间视角变化极小,包含的场景信息和位姿信息几乎完全相同。存储和处理所有这些冗余信息是巨大的浪费。
关键帧就是解决方案。 它不是每一帧都处理,而是从视频流中稀疏地选取一部分具有代表性的帧。
核心思想:
关键帧就像是你旅行相册中的精选照片,而不是你拍下的所有照片。它们记录了路径上的关键位置和视角,足以重建整个旅程,同时又大大减少了数据量。2. 何时创建新的关键帧?—— 关键帧选择策略
系统不能随意选择关键帧,必须遵循一套严格的策略,以确保所选的帧既不冗余,也不至于太稀疏而丢失跟踪。ORB-SLAM中的策略非常经典,通常包含以下几个条件(需要同时满足):
距离上足够远: 自上一个关键帧被插入以来,相机必须已经移动了一段最小的平移或旋转。这确保了关键帧在空间上是分散的。
跟踪质量良好,但不能太好:
- ORB-SLAM的经典规则:
如果当前帧能够观测到的地图点中,有超过90%也同时被上一个关键帧观测到,那么说明这两帧的视角太相似了,不应该创建新的关键帧。只有当这个共视比例下降到一定程度(例如,当前帧看到了一些上一个关键帧看不到的新东西),才满足插入条件。这确保了新关键帧能为地图带来新的信息。
- 跟踪不能太差:
当前帧必须跟踪到足够数量的地图点(Map Points),保证位姿估计是可靠的。如果跟踪即将丢失,系统会强制插入一个关键帧。
- 视差足够大(关键!):
这是最重要的条件。当前帧看到的场景必须与上一个关键帧有显著的不同。这个“不同”通常用共视地图点的比例来衡量。
- 计算回环约束:
时间间隔: 作为一个兜底策略,如果距离上一个关键帧已经过去了很长时间,但相机可能移动缓慢导致其他条件不满足,系统也可能会插入一个新的关键帧。
系统状态: 当系统正在进行重定位时,或者地图中关键帧数量很少时,插入策略会变得更加宽松。
3. 关键帧创建时的处理流程
一旦系统决定将当前帧提升为关键帧,一系列复杂的处理流程就会被触发。这可以看作是“给这张精选照片添加详细的注释和索引”。
分配唯一ID,存储位姿:
为新的关键帧分配一个独一无二的ID。
将其当前的位姿(位置和姿态)存储下来。这个位姿将成为后端**位姿图(Pose Graph)**中的一个新节点。
计算词袋(BoW)向量:
提取该关键帧的所有特征点。
利用预加载的视觉字典,将这些特征点转换成一个高维、稀疏的BoW向量。
这个BoW向量是该关键帧的**“视觉指纹”,将被存入数据库,用于未来的回环检测和重定位**。
创建新的地图点(Triangulation):
关键帧的核心价值之一是构建地图。
系统会查找这个新关键帧与它之前的一些关键帧之间的特征匹配。
对于那些匹配上的、但尚未形成3D地图点的特征,系统会利用这两个关键帧的位姿和2D特征位置,通过三角化(Triangulation)来计算出这些特征点在三维空间中的坐标,从而创建新的地图点。
更新图结构(Covisibility Graph & Essential Graph):
- 作用:
圈定了“局部范围”,为**局部优化(Local BA)**提供了依据。
- 共视图(Covisibility Graph):
这是一个非常重要的图结构。图中的节点是关键帧,如果两个关键帧能观测到大量相同的地图点(例如超过15个),就在它们之间连接一条边。这条边的权重就是共视点的数量。
- 本质图(Essential Graph):
这是共视图的简化版,只保留连接性强、但不一定是邻居的边,主要用于回环检测后的图优化。
- 作用:
执行局部优化(Local Bundle Adjustment, Local BA):
新插入的关键帧。
在共视图中与它相连的“邻居”关键帧。
所有被这些关键帧观测到的地图点。
这是保证局部精度、抑制漂移的关键一步。
当新关键帧插入后,系统会启动一次小范围的优化。
- 优化对象:
- 优化目标:
调整这些局部关键帧的位姿和局部地图点的3D坐标,使得地图点在这些帧上的重投影误差最小。
4. 关键帧创建后的使用与管理
关键帧一旦被创建并处理完毕,就成为了SLAM系统中长期存在的、有价值的资产。
使用场景:
- 跟踪(Tracking):
最近的一些关键帧所包含的地图点,会被投影到新的相机帧中,以指导特征匹配,从而实现稳定、快速的相机位姿跟踪。
- 回环检测(Loop Closure):
所有关键帧的BoW向量构成了回环检测的数据库。当前帧的BoW向量会与这个数据库进行快速比对。
- 重定位(Relocalization):
当跟踪丢失时,系统会将当前帧转换为一个临时的“查询帧”,在关键帧数据库中搜索最相似的匹配,以找回自己的位置。
- 全局优化(Global BA):
当检测到回环时,所有关键帧的位姿(作为节点)和它们之间的约束(运动约束和回环约束)构成的整个位姿图,会进行一次全局优化,消除累积误差。
管理与剔除(Culling):
关键帧不能无限增加,否则内存和计算负担依然会过重。因此,需要一个剔除机制来移除冗余的关键帧。
- 剔除标准:
如果一个关键帧所观测到的地图点,几乎(例如90%以上)都被至少3个其他的邻居关键帧所观测,那么这个关键帧就被认为是“冗余”的。它的信息已经被其他关键帧充分覆盖了。
- 操作:
系统会从共视图和数据库中安全地移除这个冗余的关键帧,同时确保它所“独有”的信息(如果有的话)被传递给邻居,避免丢失地图信息。
总结
处理环节
核心任务
目标
选择策略 判断当前帧是否值得保留
平衡信息量与数据量,确保稀疏且有代表性
创建流程 建立索引、构建地图、局部优化
将图像信息转化为结构化的地图数据和图模型
后期使用 跟踪、回环、重定位、全局优化
作为整个SLAM系统的骨架,支撑所有高级功能
管理剔除 移除冗-余的关键帧
控制地图规模,保证系统长期稳定运行
可以说,对关键帧的**“选、建、用、管”**,构成了视觉SLAM中端和后端的核心,是实现高精度、高鲁棒性、可扩展的定位与建图系统的关键所在。
7. 检测之后的验证
我们来详细讲解在回环检测中至关重要的一步——几何验证(Geometric Verification)。
在第一阶段,词袋模型(BoW)已经为我们从成千上万的历史关键帧中,筛选出了几个在视觉上最相似的候选帧。但这远远不够,因为“看起来像”不等于“就是同一个地方”。
为什么需要几何验证?
- 重复性结构:
很多环境中充满了重复的纹理和结构,比如办公室里一排排相同的门、走廊、窗户,或者书架上成排的书。这些地方在视觉上可能高度相似,但物理位置完全不同。
- 偶然匹配:
词袋模型只是统计了“视觉单词”的频率,两个完全不相关的场景也可能因为偶然含有一些相同的“视觉单词”而获得较高的相似度评分。
一个错误的“回环”判断(假阳性,False Positive)对SLAM系统是灾难性的,它会引入一个错误的全局约束,导致整个地图被严重扭曲。因此,必须通过严格的几何验证来确认候选帧是否真的与当前帧在三维空间中存在一致的几何关系。
几何验证的核心流程
几何验证的本质是:利用两帧之间的特征点匹配,来求解一个刚体变换模型,并检查这个模型是否得到了足够多匹配点的支持。
这个流程通常使用 RANSAC(Random Sample Consensus,随机采样一致性) 算法来鲁棒地完成。
目前主流的SLAM系统主要采用以下两种几何验证方式:
方式一:3D-2D 验证 (PnP + RANSAC) - 最常用、最可靠
这是当已经存在一个三维地图时最常用、效果最好的方法。
前提:
对于候选的关键帧,我们不仅有它的2D图像,还知道它上面很多特征点所对应的三维地图点(Map Points) 的坐标。这些3D点是在之前的建图过程中通过三角化得到的。
对于当前帧,我们有它提取出的2D特征点。
流程:
特征匹配: 在当前帧的2D特征点和候选帧的2D特征点之间进行匹配。由于我们知道候选帧特征点对应的3D地图点,这样我们就建立了一组 “当前帧2D点 <-> 候选帧3D地图点” 的对应关系。
RANSAC迭代求解位姿:
- a. 随机采样 (Sample):
从这组
(2D, 3D)对应关系中,随机选择一个最小子集。对于PnP问题,最小集通常是3对或4对点(取决于所用的PnP求解器)。 - b. 模型估计 (Hypothesize):
使用这个最小子集,通过PnP(Perspective-n-Point)算法来计算一个从世界坐标系到当前相机坐标系的变换矩阵,即当前帧的位姿(Pose)。
- c. 内点检验 (Verify):
使用刚刚计算出的位姿,将所有的候选帧3D地图点都投影到当前帧的图像平面上。然后,检查投影后的2D点与它们实际匹配的2D点之间的重投影误差。如果误差小于一个阈值(例如2-3个像素),就将这对匹配点标记为 “内点”(Inlier)。
- d. 记录最佳模型:
重复 a-c 步骤N次(例如100次)。记录下哪一次迭代产生的模型拥有最多的内点数量。
最终判定:
在所有RANSAC迭代结束后,如果最佳模型的内点数量超过一个预设的阈值(例如,在ORB-SLAM中通常是15-30个点),那么我们就认为这个几何关系是有效且可信的。
- 几何验证成功!
这个候选帧被确认是一个真正的回环。
最终位姿优化(可选但推荐):
一旦验证成功,我们会使用所有找到的内点(而不仅仅是最初采样的那几个点),再次运行一次PnP求解器。这样可以得到一个更精确、更稳定的相对位姿变换。
方式二:2D-2D 验证 (基本矩阵/本质矩阵 + RANSAC)
当没有预先构建的3D地图时(例如,在纯视觉里程计的初始化阶段,或者一些纯图像检索应用中),我们只能依赖两张2D图像的信息。
前提:
只有当前帧和候选帧这两张2D图像。
流程:
特征匹配: 在两张图像之间进行2D特征点匹配。
RANSAC迭代求解几何关系:
对于基础矩阵(Fundamental Matrix),需要8对点(八点法)或7对点。
对于本质矩阵(Essential Matrix),需要5对点(五点法),并且需要相机的内参。
- a. 随机采样:
从匹配对中随机采样一个最小子集。
- b. 模型估计:
使用采样点计算出基础矩阵
F或本质矩阵E。 - c. 内点检验:
对于所有的匹配对
(p1, p2),检查它们是否满足对极约束:p2^T * F * p1 = 0。如果这个等式的值(考虑到噪声,是它的绝对值)小于一个很小的阈值,就认为这对匹配是内点。 - d. 记录最佳模型:
同样,记录下产生最多内点的那个模型。
最终判定:
如果最佳模型的内点数量超过一个阈值,则认为几何验证成功。
位姿恢复:
从计算出的本质矩阵
E中,可以分解出4组可能的相对旋转R和平移t。需要进一步通过三角化检查,选择那个能让大部分点都在相机前方(深度为正)的解。
对比两种方式:
特性
3D-2D (PnP)
2D-2D (F/E Matrix)
依赖 需要3D地图点
只需要两张2D图像 (+内参 for E)
可靠性 非常高 。3D信息提供了强大的约束。
较低 。更容易受到退化场景(如纯平面)的影响,且解有歧义性。
求解自由度 求解6 DoF的绝对位姿。
求解5 DoF的相对位姿(平移有尺度不确定性)。
应用场景 SLAM回环检测的主流方法。 纯VO初始化、双目SLAM、图像检索等。
总结
几何验证是回环检测的 “最后一道防线” ,它的核心任务是从视觉相似性上升到几何一致性。通过RANSAC算法,它能够鲁棒地从大量的特征匹配中,找到一个能够解释大多数匹配的刚体变换模型,从而以极高的置信度确认回环的真实性,为后续的全局优化提供一个坚实、可靠的基础。在现代SLAM系统中,基于PnP的3D-2D验证是绝对的主流和首选。
8. 回环检测与机器学习的关系
这是一个非常前沿且重要的话题。回环检测与机器学习(特别是深度学习)的关系正在变得越来越紧密,可以说,机器学习正在重新定义高性能回环检测的可能性。
我们可以从两个层面来看待它们的关系:
- 机器学习如何赋能传统回环检测流程?
(Enhancing the Classic Pipeline)
- 机器学习如何催生全新的端到端回环检测方法?
(Creating New End-to-End Paradigms)
1. 机器学习赋能传统回环检测流程
传统的"词袋(BoW) + 几何验证"流程虽然经典,但在某些环节存在瓶颈,而机器学习恰好能对这些环节进行精准的升级和替换。
A. 替换“候选帧选择”模块 (Feature Extraction & Image Retrieval)
这是机器学习应用最广泛、最成功的领域。传统词袋模型对剧烈的外观变化(如光照、季节、天气变化)非常敏感,而深度学习模型展现出了惊人的鲁棒性。
- 方法:
使用卷积神经网络 (CNN) 来提取图像的全局描述子 (Global Descriptor)。
- 代表性工作:
- NetVLAD:
这是里程碑式的工作。它设计了一个可微的VLAD层,可以插入到任何CNN的末端,将网络提取的局部特征聚合成一个紧凑、强大且对视角变化鲁棒的全局向量。
- GeM (Generalized Mean Pooling):
提出了一种更有效的池化方法,能更好地保留图像的判别性信息。
- SALAD, Patch-NetVLAD 等:
对NetVLAD的各种改进,提升了在更具挑战性场景下的性能。
- NetVLAD:
- 优势 vs. BoW:
- 鲁棒性强:
对光照、天气、季节、昼夜变化具有前所未有的鲁棒性。一张夏天的街道照片和一张冬天的雪景照片,可以通过深度学习模型被正确匹配。
- 语义信息:
CNN能学习到更高层次的语义信息(比如“这是一座桥”),而不仅仅是低级的角点和纹理。
- 端到端学习:
模型可以直接针对“位置识别”任务进行优化,理论上性能上限更高。
- 鲁棒性强:
- 挑战:
需要大量的、带有地理位置标签的数据进行训练(通常使用Google Street View等数据集)。
计算量较大,通常需要GPU加速。
泛化能力依赖于训练数据的多样性。
B. 升级“特征提取与匹配”模块
深度学习不仅能提取全局描述子,还能学习提取和匹配局部特征 (Local Features)。
- 方法:
训练两个协同工作的网络,一个用于检测特征点(Detector),另一个用于生成描述子(Descriptor)。
- 代表性工作:
- SuperPoint:
能同时检测特征点并生成描述子,在重复纹理区域表现优于传统方法。
- SuperGlue:
这不是一个特征提取器,而是一个特征匹配器。它使用图神经网络,并结合视觉信息和几何信息,能以前所未有的精度匹配两张图像的特征点,即使在视角变化极大或动态物体遮挡的情况下。
- SuperPoint:
- 优势:
- 更强的匹配能力:
在困难场景下(大视角变化、弱纹理),能找到比传统方法(如ORB)更多的正确匹配。
- 上下文感知:
SuperGlue这样的方法利用了全局上下文,使得匹配更加智能和鲁棒。
- 更强的匹配能力:
- 在回环检测中的应用:
在“几何验证”阶段,使用SuperPoint+SuperGlue替代传统的ORB特征匹配,可以大大增加找到的**内点(inliers)数量,从而提高回环验证的召回率(Recall)**和鲁棒性。
2. 机器学习催生全新的端到端方法
除了增强传统流程,研究者们也在探索完全基于机器学习的“端到端”方法,直接从图像输入,输出回环信息。
A. 端到端视觉重定位 (End-to-End Visual Relocalization)
这类方法试图训练一个单一的神经网络,直接从一张查询图像回归出它在已知地图中的相机位姿(6-DoF)。
- 代表性工作:
- PoseNet:
第一个用CNN直接回归相机位姿的工作。
- 后续改进 (MapNet, AtLoc, etc.):
引入了几何约束(如重投影误差)到损失函数中,或者结合了注意力机制,来提升精度和鲁棒性。
- PoseNet:
- 工作方式:
- 离线建图与训练:
在一个场景中运行传统的SLAM系统(如ORB-SLAM)构建一个地图,并记录下所有关键帧的图像及其对应的真实位姿。
- 模型训练:
用这些
(图像, 位姿)对来训练一个CNN。网络学习从图像像素直接映射到位姿。 - 在线重定位:
输入一张新的查询图像,网络直接输出一个6-DoF的位姿估计。
- 优势:
- 极快:
一次网络前向传播即可得到结果。
- 概念简单:
省去了复杂的特征匹配、RANSAC等流程。
- 极快:
- 挑战:
- 精度有限:
目前精度还无法与传统的“匹配+几何优化”方法相媲美。
- 泛化性差:
通常只能在训练过的特定场景内工作,对新场景的泛化能力很弱。
B. 语义辅助的回环检测
利用深度学习进行语义分割(Semantic Segmentation),为回环检测提供额外的高层信息。
- 方法:
- 构建语义地图:
将语义信息融入到SLAM地图中,构建一个包含几何和语义双重信息的地图。回环检测可以在语义层面进行,比如匹配“建筑轮廓”或“物体布局”。
- 构建语义地图:
对每个关键帧运行一个语义分割网络,得到一张“语义地图”,其中每个像素都被标记为“天空”、“建筑”、“道路”、“汽车”等。
- 语义一致性检查:
在几何验证之后,可以增加一个“语义验证”步骤。检查当前帧和候选帧的语义标签分布是否一致。例如,如果一个回环匹配中,当前帧看到的是“天空”,而候选帧对应区域是“建筑”,则这个匹配很可能是错误的。
- 精度有限:
- 优势:
- 消除动态物体干扰:
可以轻易地识别并忽略“汽车”、“行人”等动态物体上的特征点,使回环检测更稳定。
- 提供强先验:
语义信息为场景理解提供了强大的先验知识,有助于解决视觉模糊性问题。
总结与未来展望
关系层面
机器学习扮演的角色
优点
挑战
赋能传统流程 “超级组件” :更强的特征提取器、匹配器和图像检索器。
显著提升鲁棒性(尤其是外观变化),提高召回率。
计算成本,需要训练数据。
催生全新范式 “游戏规则改变者” :端到端位姿回归,语义SLAM。
速度快,概念新颖,引入高层理解。
精度瓶颈,泛化能力差,目前尚不成熟。
当前现状:
目前,第一种方式(用机器学习赋能传统流程)是工业界和学术界最为主流和实用的方向。像SuperGlue和NetVLAD这样的技术已经被证明能显著提升SLAM系统的性能,并被集成到了一些先进的SLAM系统中。未来展望:
随着模型性能的提升和计算硬件的发展,机器学习在SLAM中的作用将越来越重要。未来的回环检测可能会是一个混合系统:使用深度学习模型进行快速、鲁棒的候选帧召回。
使用学习到的特征匹配器进行更可靠的几何验证。
同时利用语义信息来剔除动态干扰和解决场景模糊性。
最终仍然依赖于经典的图优化框架来保证全局的几何一致性。
机器学习不是要完全取代传统几何方法,而是与它们相辅相成,各自发挥优势,共同将回环检测推向新的高度。
二、代码笔记
1. feature_training.cpp 基于 g2o types_slam3d 的位姿图优化程序
该C++程序的核心功能是训练一个视觉词袋(Visual Bag-of-Words, BoW)字典。这个字典在视觉SLAM和图像检索等领域中至关重要,主要用于高效地表示和比较图像,特别是用于回环检测 (Loop Closure Detection)。
程序的主要工作流程如下:
收集训练数据:程序首先从一个指定的目录(
./data/)下加载一系列图像。这些图像构成了训练字典所需的基础视觉数据。特征提取:对于每一张加载的训练图像,程序使用ORB算法来提取特征。具体来说,它检测出图像中的关键点,并为每个关键点计算一个ORB描述子。ORB描述子是一个256位的二进制向量,它能够紧凑地描述关键点周围的局部图像区域。最终,程序会得到一个包含成千上万个ORB描述子的集合。
字典训练:这是程序的核心步骤。
程序创建了一个
DBoW3::Vocabulary对象。它将上一步提取出的所有描述子集合作为输入,调用
vocab.create()方法来训练字典。DBoW3库内部会执行一个层次化的k-means聚类算法。它将高维的描述子空间不断地进行划分,形成一个树状结构。这棵树的叶子节点被称为**“视觉单词” (Visual Words)**。每个视觉单词本质上是一个聚类中心,代表了一类相似的局部图像特征。整个树形结构就是所谓的“视觉词典”。
- 消除动态物体干扰:
保存字典:训练完成后,为了避免每次运行时都重新进行耗时的训练过程,程序将构建好的词典序列化并保存到一个文件中(
vocabulary.yml.gz)。在实际应用中,可以直接从这个文件加载预训练好的字典来使用。总而言之,这个程序的功能就像是为视觉世界编写一本“字典”。通过学习大量的“视觉样本”(特征描述子),它总结出了一系列具有代表性的“基本词汇”(视觉单词),为后续的图像理解和比较任务奠定了基础。


2. gen_vocab_large.cpp 基于 DBoW3 的视觉词袋字典训练程序
该C++程序的功能与上一个示例非常相似,都是训练一个视觉词袋(Visual Bag-of-Words, BoW)字典。但它在数据加载方式上有所不同,展示了如何处理一种在SLAM研究中非常常见的数据集格式——TUM RGB-D数据集格式。
程序的主要工作流程如下:
解析数据集文件结构:
程序不再是简单地从一个目录加载编号的图片,而是首先读取一个名为
associate.txt的文件。这个
associate.txt文件是TUM数据集的标准组成部分,它将时间戳相近的RGB图像和深度图像关联起来,并提供了它们的文件路径。程序解析这个文件,将所有RGB图像的完整路径提取出来,存入一个
vector中。虽然它也读取了深度图的信息,但在后续的字典训练中并未使用。
特征提取:
与前一个示例完全相同,程序遍历所有解析出的RGB图像路径。
对于每一张图像,它使用ORB算法来提取关键点和对应的ORB描述子。
所有图像的所有描述子被收集到一个大的
vector<Mat>中。
字典训练与保存:
此步骤也与前一个示例完全相同。
程序使用收集到的所有ORB描述子来训练一个
DBoW3::Vocabulary。训练过程通过层次化k-means聚类构建一个视觉单词树。
训练完成后,将生成的字典保存到文件
vocab_larger.yml.gz中,以供将来在回环检测等任务中直接加载和使用。
核心区别:本程序的核心价值在于展示了如何**适配一个标准的数据集格式(如TUM)**来作为词袋字典的训练数据源。它通过解析
associate.txt文件,实现了对更复杂、更贴近实际研究场景的数据集的处理,而不仅仅是处理简单的、按顺序编号的图片。

3. loop_closure.cpp
该C++程序演示了如何使用预训练好的视觉词袋(BoW)字典来进行图像的相似性比较和检索,这是回环检测的核心功能。
程序的主要工作流程如下:
加载资源:
程序首先从文件中加载一个预先训练好的
DBoW3::Vocabulary字典。这个字典是后续所有操作的基础。然后,它加载一系列待处理的图像。
特征提取与表示转换:
对于每一张待处理的图像,程序使用ORB算法提取特征描述子。
接着,最关键的一步是调用
vocab.transform()函数。这个函数将一张图像的原始描述子集合转换为一个BoW向量 (DBoW3::BowVector)。这个向量是图像的一种高度浓缩、标准化的表示,它记录了图像中出现了字典里的哪些“视觉单词”以及它们的权重(通常是TF-IDF值)。
图像相似性计算:程序展示了两种应用BoW模型的方式:
- 直接两两比较
:程序通过
vocab.score()函数直接计算任意两个图像的BoW向量之间的相似度得分。这个得分通常是基于两个向量的点积或其他相似性度量,得分越高代表两张图像在视觉上越相似。 - 数据库查询与图像检索
:程序创建了一个
DBoW3::Database对象,并将所有图像的BoW表示添加到这个数据库中。DBoW3内部会为这些BoW向量建立倒排索引(Inverted Index)以加速查询。然后,程序可以拿任何一张图像作为查询,通过db.query()在数据库中高效地找出与它最相似的几张图像。这正是SLAM中回环检测所需要的核心功能:当机器人回到一个曾经去过的地方时,能够快速地从历史图像数据库中找到与当前帧最相似的那个历史帧。
总而言之,该程序演示了词袋模型的应用阶段:如何将图像转换为紧凑的BoW向量表示,并利用这种表示来进行高效的相似性度量和大规模图像检索。


- 直接两两比较

















 565
565

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









