




 文章介绍了一种名为D2-Net的新型网络,通过MD-Stage的模态解耦和TD-Stage的肿瘤区域解耦,处理MRI数据中脑肿瘤分割,特别强调在缺少模态时的性能。方法包括空间频率联合学习和ADT-KD知识蒸馏。然而,模型的复杂性和对特定模态的依赖性可能限制其在资源有限环境中的应用。
文章介绍了一种名为D2-Net的新型网络,通过MD-Stage的模态解耦和TD-Stage的肿瘤区域解耦,处理MRI数据中脑肿瘤分割,特别强调在缺少模态时的性能。方法包括空间频率联合学习和ADT-KD知识蒸馏。然而,模型的复杂性和对特定模态的依赖性可能限制其在资源有限环境中的应用。
Yang Q, Guo X, Chen Z, et al. D2-Net: Dual disentanglement network for brain tumor segmentation with missing modalities[J]. IEEE Transactions on Medical Imaging, 2022, 41(10): 2953-2964. 【代码开源】
论文概述
本文介绍了一种名为D2-Net(双重解耦网络)的新型网络架构,用于在缺少某些模态的情况下进行脑肿瘤分割。这个网络的核心思想是通过两个阶段的解耦来处理多模态磁共振成像(MRI)数据中的脑肿瘤分割问题,特别是在缺少某些成像模态的情况下。
- 模态解耦阶段(MD-Stage):在这一阶段,D2-Net使用一种名为空间频率联合模态对比学习(SFMC)的方案来解耦MRI数据中的模态特定信息。这个过程在空间和频率域中进行,旨在直接从MRI图像中分离出模态特定信息,从而使模型能够直接学习多种模态之间的关联。
- 肿瘤区域解耦阶段(TD-Stage):在这一阶段,网络利用一种称为亲和引导的密集肿瘤区域知识蒸馏(ADT-KD)机制来分解各种肿瘤特定知识,并获取全面的特征以用于分割。这个阶段旨在解耦肿瘤特定特征,并利用这些特征获得更好的分割结果。
方法模型
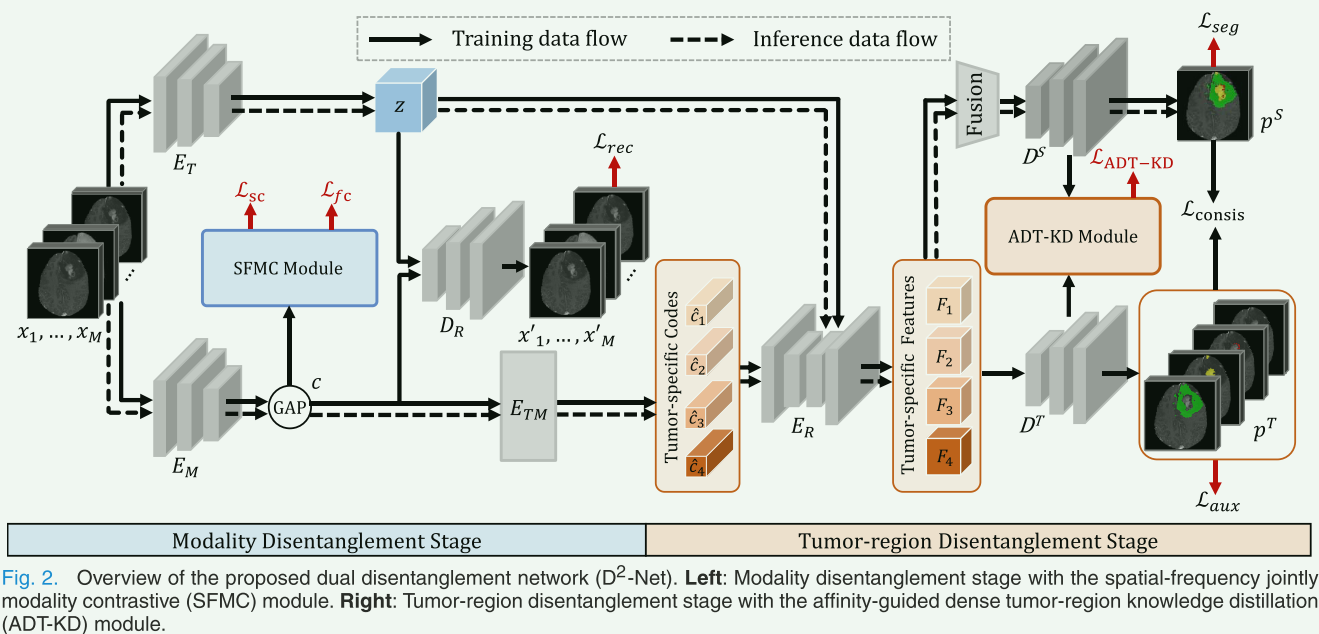
step1😗*ModalityDisentanglementStage(MD-Stage):**MD-Stage的主要目标是解耦MRI数据中的模态特定信息,使模型能够在缺少某些模态的情况下仍然有效地进行脑肿瘤分割。
是MD-Stage的核心组成部分。SFMC通过结合空间域和频率域的对比学习,从MRI图像中直接分离出模态特定信息。这种方法考虑了MRI图像的空间特征(如形状、边缘等)和频率特征(如纹理、模式等)。使用编码器 E T E_T E
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3470
3470

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









