






这里写目录标题
5. Experimental Evaluation 实验评价
第一段(介绍本文是在什么条件下进行评估)
The main motivation behind our work was to develop a local features approach that is able to better handle challenging conditions.
我们工作背后的主要动机是开发一种能够更好地处理具有挑战性条件的局部特征方法。
Firstly, we evaluate our method on a standard image matching task based on sequences with illumination or viewpoint changes.
首先,我们对基于光照或视点变化序列的标准图像匹配任务进行了评估。
Then, we present the results of our method in two more complex computer vision pipelines: 3D reconstruction and visual localization.
然后,我们在两个更复杂的计算机视觉管道:三维重建和视觉定位中展示了我们的方法的结果。
In particular, the visual localization task is evaluated under extremely challenging conditions such as registering nighttime images against 3D models generated from day-time imagery [46, 48] and localizing images in challenging indoor scenes [59] dominated by weakly textured surfaces and repetitive structures.
特别是,视觉定位任务是在极具挑战性的条件下进行评估的,例如根据白天图像生成的三维模型注册夜间图像 [46, 48],以及在以弱纹理表面和重复结构为主的极具挑战性的室内场景中定位图像 [59]。
Qualitative examples of the results of our method are presented in Fig. 1. Please see the supplementary material for additional qualitative examples.
我们的方法结果的定性例子如图1所示。请参阅补充材料中更多的定性例子。

Figure 1: Examples of matches obtained by the D2-Net method. The proposed method can find image correspondences
even under significant appearance differences caused by strong changes in illumination such as day-to-night, changes in depiction style or under image degradation caused by motion blur.
图1:使用D2-Net方法获得的匹配示例。该方法可以在强烈光照变化(如日夜变化)、描绘风格变化或运动模糊导致图像退化的情况下找到图像对应。
5.1. Image Matching 图像匹配
第一段(选择的数据集)
In a first experiment, we consider a standard image matching scenario where given two images we would like to extract and match features between them.
在第一个实验中,我们考虑一个标准的图像匹配场景,给定两幅图像,我们想要提取并匹配它们之间的特征。
For this experiment, we use the sequences of full images provided by the HPatches dataset [5].
在本实验中,我们使用HPatches数据集提供的完整图像序列[5]。
Out of the 116 available sequences collected from various datasets [1, 5, 11, 23, 33, 63, 67], we selected 108.
从各种数据集[1,5,11,23,33,63,67]收集的116个可用序列中,我们选择了108个。
Each sequence consists of 6 images of progressively larger illumination (52 sequences without viewpoint changes) or viewpoint changes (56 sequences without illumination changes).
每个序列由6幅逐渐变大的照度图像(52幅序列无视点变化)或视点变化图像(56幅序列无照度变化)组成。
For each sequence, we match the first against all other images, resulting in 540 pairs.
对于每个序列,我们将第一个与所有其他图像进行匹配,得到540对。
第二段(评估指标)
Evaluation protocol. For each image pair, we match the features extracted by each method using nearest neighbor search, accepting only mutual nearest neighbors.
评估协议。对于每个图像对,我们使用最近邻搜索来匹配每种方法提取的特征,只接受相互最近邻。
A match is considered correct if its reprojection error, estimated using the homographies provided by the dataset, is below a given matching threshold.
如果使用数据集提供的同形词估计的重投影误差低于给定的匹配阈值,则认为匹配是正确的。
We vary the threshold and record the mean matching accuracy (MMA) [33] over all pairs, i.e., the average percentage of correct matches per image pair.
我们改变阈值并记录所有图像对的平均匹配精度(MMA)[33],即每对图像对正确匹配的平均百分比。
第三段(与基线模型的比较)
As baselines for the classical detect-then-describe strategy, we use RootSIFT [4, 30] with the Hessian Affine keypoint detector [32], a variant using a learned shape estimator (HesAffNet [36] - HAN) and descriptor (HardNet++ [35] - HN++2 ), and an end-to-end trainable variant (LF-Net [39]).
作为经典检测-然后描述策略的基线,我们使用RootSIFT[4,30]与Hessian仿射关键点检测器[32],使用学习形状估计器(HesAffNet [36] - HAN)和描述符(hardnet++ [35] hn++ 2)的变体,以及端到端可训练变体(LF-Net[39])。
We also compare against SuperPoint [13] and DELF [38], which are conceptually more similar to our approach.
我们还比较了SuperPoint[13]和DELF[38],它们在概念上更类似于我们的方法。
第四段(使用图表与基线模型比较性能)
Results. Fig. 4 shows results for illumination and viewpoint changes, as well as mean accuracy over both conditions.
结果。图4显示了光照和视点变化的结果,以及两种条件下的平均精度。
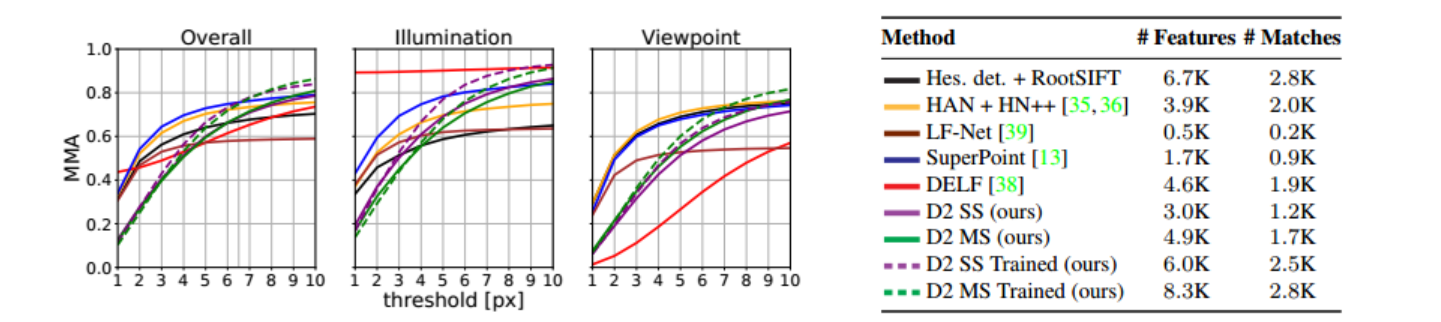
Figure 4: Evaluation on HPatches [5] image pairs. For each method, the mean matching accuracy (MMA) as a function of the matching threshold (in pixels) is shown. We also report the mean number of detected features and the mean number of mutual nearest neighbor matches. Our approach achieves the best overall performance after a threshold of 6:5px, both using a single (SS) and multiple (MS) scales.
图4:HPatches[5]图像对的评价。对于每种方法,显示了平均匹配精度(MMA)作为匹配阈值(以像素为单位)的函数。我们还报告了检测到的特征的平均数量和相互最近邻匹配的平均数量。我们的方法在使用单个(SS)和多个(MS)尺度的阈值为6:5px之后实现了最佳的整体性能。
For each method, we also report the mean number of detected features and the mean number of mutual nearest neighbor matches per image.
对于每种方法,我们还报告了每幅图像检测到的特征的平均数量和相互近邻匹配的平均数量。
As can be seen, our method achieves the best overall performance for matching thresholds of 6:5 pixels or more.
可以看到,我们的方法在匹配6:5像素或更高的阈值时达到了最佳的整体性能。
第五段(其他方法的缺点)
DELF does not refine its keypoint positions - thus, detecting the same pixel positions at feature map level yields perfect accuracy for strict thresholds.
DELF不细化其关键点位置-因此,在特征图级别检测相同的像素位置可以为严格的阈值提供完美的精度。
Even though powerful for the illumination sequences, the downsides of their method when used as a local feature extractor can be seen in the viewpoint sequences.
尽管对于照明序列来说功能强大,但当用作局部特征提取器时,它们的缺点可以在视点序列中看到。
For LF-Net, increasing the number of keypoints to more than the default value (500) worsened the results.
对于LF-Net,将关键点的数量增加到超过默认值(500)会使结果恶化。
However, [39] does not enforce that matches are mutual nearest neighbors and we suspect that their method is not suited for this type of matching.
然而,[39]并没有强制要求匹配是相互最近的邻居,我们怀疑他们的方法不适合这种类型的匹配。
第六段(介绍本文方法的优越性)
As can be expected, our method performs worse than detect-then-describe approaches for stricter matching thresholds: The latter use detectors firing at low-level bloblike structures, which are inherently better localized than the higher-level features used by our approach.
正如可以预料的那样,对于更严格的匹配阈值,我们的方法比检测-然后描述的方法执行得更差:后者使用检测器在低级的斑点状结构上发射,这些结构本质上比我们的方法使用的高级特征更好地定位。
At the same time, our features are also detected at the lower resolution of the CNN features
同时,我们的特征也是在CNN特征的较低分辨率下进行检测的
第七段(分析出现问题的原因)
We suspect that the inferior performance for the sequences with viewpoint changes is due to a major bias in our training dataset - roughly 90% of image pairs have a change in viewpoint lower than 20◦ (measured as the angle between the principal axes of the two cameras).
我们怀疑具有视点变化的序列的较差性能是由于我们的训练数据集中的主要偏差-大约90%的图像对的视点变化低于20◦(测量为两个相机主轴之间的角度)。
第八段(分析出现问题的原因)
The proposed pipeline for multiscale detection improves the viewpoint robustness of our descriptors, but it also adds more confounding descriptors that negatively affect the robustness to illumination changes
提出的多尺度检测管道提高了描述子的视点鲁棒性,但也增加了更多的混杂描述子,对光照变化的鲁棒性产生负面影响
5.2. 3D Reconstruction 三维重建
第一段(介绍第二个实验)
In a second experiment, we evaluate the performance of our proposed describe-and-detect approach in the context of 3D reconstruction.
在第二个实验中,我们在3D重建的背景下评估了我们提出的描述和检测方法的性能。
This task requires well-localized features and might thus be challenging for our method.
这项任务需要很好地定位特征,因此可能对我们的方法具有挑战性。
第二段(介绍数据集)
For evaluation, we use three medium-scale internetcollected datasets with a significant number of different cameras and conditions (Madrid Metropolis, Gendarmenmarkt and Tower of London [64]) from a recent local feature evaluation benchmark [52].
为了进行评估,我们使用了三个中等规模的互联网收集的数据集,这些数据集具有大量不同的相机和条件(马德里大都会,宪兵市场和伦敦塔[64]),这些数据集来自最近的本地特征评估基准[52]。
All three datasets are small enough to allow exhaustive image matching, thus avoiding the need for using image retrieval.
这三个数据集都足够小,可以进行详尽的图像匹配,从而避免使用图像检索。
第三段(实验遵守的协议和基准)
Evaluation protocol. We follow the protocol defined by [52] and first run SfM [51], followed by Multi-View Stereo (MVS) [54].
评估协议。我们遵循[52]定义的协议,首先运行SfM[51],然后运行Multi-View Stereo (MVS)[54]。
For the SfM models, we report the number of images and 3D points, the mean track lengths of the 3D points, and the mean reprojection error.
对于SfM模型,我们报告了图像和3D点的数量,3D点的平均轨迹长度和平均重投影误差。
For the MVS models, we report the number of dense points.
对于MVS模型,我们报告了密集点的数量。
Except for the reprojection error, larger numbers are better.
除了重投影误差外,数字越大越好。
We useRootSIFT [4, 30] (the best perfoming method according to the benchmark’s website) and GeoDesc [31], a state-of-theart trained descriptor3 as baselines. Both follow the detectthen-describe approach to local features.
我们使用RootSIFT4,30和GeoDesc[31],一个最先进的训练描述符3作为基准。两者都遵循检测-描述局部特征的方法。
第四段(用表来对比本文三维重建的实验结果)
Results. Tab. 1 shows the results of our experiment.
结果。表1显示了我们的实验结果。
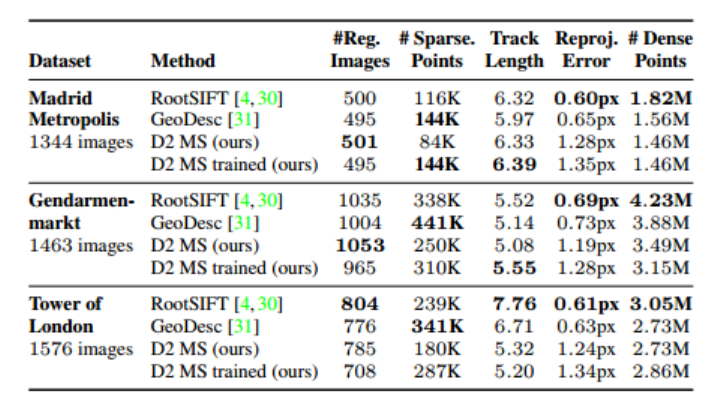
Table 1: Evaluation on the Local Feature Evaluation Benchmark [52]. Each method is used for the 3D reconstruction of each scene and different statistics are reported. Overall, our method obtains a comparable performance with respect to SIFT and its trainable counterparts, despite using less well-localized keypoints.
表1:对局部特征评价基准的评价[52]。每种方法用于每个场景的三维重建,并报告不同的统计数据。总的来说,尽管我们的方法使用了较少的定位良好的关键点,但相对于SIFT和可训练的同类方法,我们的方法获得了相当的性能。
Overall, the results show that our approach performs on par with state-of-the-art local features on this task.
总体而言,结果表明,我们的方法在此任务上与最先进的局部特征相当。
This shows that, even though our features are less accurately localized compared to detect-then-describe approaches, they are suf- ficiently accurate for the task of SfM as our approach is still able to register a comparable number of images.
这表明,尽管与检测-然后描述方法相比,我们的特征定位精度较低,但对于SfM任务来说,它们足够准确,因为我们的方法仍然能够注册相当数量的图像。
第五段(本文出现问题的原因)
Our method reconstructs fewer 3D points due to the strong ratio test filtering [30] of the matches that is performed in the 3D reconstruction pipeline.
由于在3D重建管道中对匹配进行了强比率测试过滤[30],因此我们的方法重建的3D点较少。
While this filtering is extremely important to remove incorrect matches and prevent incorrect registrations, we noticed that for our method it also removes an important number of correct
matches (20%–25%)4 , as the loss used for training our method does not take this type of filtering into account.
虽然这种过滤对于删除不正确的匹配和防止不正确的注册非常重要,但我们注意到,对于我们的方法,它也删除了重要数量的正确匹配(20%-25%)4,因为用于训练的损失我们的方法没有考虑这种类型的过滤。
5.3. Localization under Challenging Conditions 挑战条件下的本地化
第一段(本文实验结果)
The previous experiments showed that our approach performs comparable with the state-of-the-art in standard applications.
先前的实验表明,我们的方法在标准应用中与最先进的方法相当。
In a final experiment, we show that our approach sets the state-of-the-art for sparse features under two very challenging conditions: Localizing images under severe illumination changes and in complex indoor scenes.
在最后的实验中,我们证明了我们的方法在两个非常具有挑战性的条件下为稀疏特征设置了最先进的技术:在剧烈光照变化和复杂室内场景下定位图像。
第二段(昼夜视觉定位)
Day-Night Visual Localization. We evaluate our approach on the Aachen Day-Night dataset [46, 48] in a local reconstruction task [46]: For each of the 98 night-time images contained in the dataset, up to 20 relevant day-time images with known camera poses are given.
**昼夜视觉定位。**我们在一个局部重建任务[46]中对亚琛昼夜数据集[46,48]的方法进行了评估:对于数据集中包含的98张夜间图像中的每一张,给出了多达20张具有已知相机姿势的相关日间图像。
After exhaustive feature matching between the day-time images in each set, their known poses are used to triangulate the 3D structure of the scenes.
在每组白天图像之间进行详尽的特征匹配后,使用已知的姿态对场景的3D结构进行三角测量。
Finally, these resulting 3D models are used to localize the night-time query images.
最后,将得到的三维模型用于夜间查询图像的定位。
This task was proposed in [46] to evaluate the perfomance of local features in the context of long-term localization without the need for a specific localization pipeline.
任务是在[46]中提出的,目的是在不需要特定的定位管道的情况下,评估局部特征在长期定位背景下的性能。
第三段(与多种描述符比较)
We use the code and evaluation protocol from [46] and report the percentage of night-time queries localized within a given error bound on the estimated camera position and orientation.
我们使用了 [46] 中的代码和评估协议,并报告了在给定的摄像机位置和方向估计误差范围内定位的夜间查询的百分比。
We compare against upright RootSIFT descriptors extracted from DoG keypoints [30], HardNet++ descriptors with HesAffNet features [35, 36], DELF [38], SuperPoint [13] and DenseSfM [46]. DenseSfM densely extracts CNN features using VGG16, followed by dense hierarchical matching (conv4 then conv3).
我们比较了从DoG关键点提取的直立RootSIFT描述符[30]、具有HesAffNet特征的hardnet++描述符[35,36]、DELF[38]、SuperPoint[13]和DenseSfM[46]。DenseSfM使用VGG16密集提取CNN特征,然后进行密集分层匹配(conv4然后conv3)
第四段(阈值控制方法)
For all methods with a threshold controlling the number of detected features (i.e. HAN + HN++, DELF, and SuperPoint), we employed the following tuning methodology: Starting from the default value, we increased and decreased the threshold gradually stopping as soon as the results started declining.
对于所有使用阈值控制检测到的特征数量的方法(即HAN + hn++、DELF和SuperPoint),我们采用以下调优方法:从默认值开始,我们增加和减少阈值,当结果开始下降时逐渐停止。
Stricter localization thresholds were considered more important than looser ones.
严格的本地化门槛被认为比宽松的更重要。
We reported the best results each method was able to achieve.
我们报告了每种方法所能达到的最佳结果。
第五段(作图分析本文方法优于基线)
As can be seen from Fig. 5, our approach performs better than all baselines, especially for strict accuracy thresholds for the estimated pose.
从图5可以看出,我们的方法优于所有基线,特别是对于估计姿态的严格精度阈值。
 Figure 5: Evaluation on the Aachen Day-Night dataset [46, 48]. We report the percentage of images registered within given error thresholds. Our approach improves upon state-of-the art methods by a significant margin under strict pose thresholds.
Figure 5: Evaluation on the Aachen Day-Night dataset [46, 48]. We report the percentage of images registered within given error thresholds. Our approach improves upon state-of-the art methods by a significant margin under strict pose thresholds.
图5:对Aachen Day-Night数据集的评估[46,48]。我们报告在给定的错误阈值内注册的图像的百分比。在严格的姿态阈值下,我们的方法比最先进的方法有了很大的改进。
Our sparse feature approach even outperforms DenseSfM, even though the later is using significantly more features (and thus time and memory).
我们的稀疏特征方法甚至胜过DenseSfM,尽管后者使用了更多的特征(从而占用了时间和内存)。
The results clearly validate our describe-and-detect approach as it significantly outperforms detect-then-describe methods in this highly challenging scenario.
结果清楚地验证了我们的描述-检测方法,因为在这个极具挑战性的场景中,它明显优于检测-然后描述方法。
The results also show that the lower keypoint accuracy of our approach does not prevent it from being used for applications aiming at estimating accurate camera poses.
结果还表明,我们的方法较低的关键点精度并不妨碍它用于旨在估计准确相机姿态的应用。
第六段(在inloc数据集实验)
Indoor Visual Localization. We also evaluate our approach on the InLoc dataset [59], a recently proposed benchmark dataset for large-scale indoor localization.
**室内视觉定位。**我们还在InLoc数据集[59]上评估了我们的方法,InLoc数据集是最近提出的用于大规模室内定位的基准数据集。
The dataset is challenging due to its sheer size (∼10k database images covering two buildings), strong differences in viewpoint and / or illumination between the database and query images, and changes in the scene over time.
由于其庞大的规模(覆盖两栋建筑的约10k数据库图像),数据库和查询图像之间的视点和/或照明差异很大,以及场景随时间的变化,该数据集具有挑战性。
第七段(在数据集上测试)
For this experiment, we integrated our features into two variants of the pipeline proposed in [59], using the code released by the authors.
在这个实验中,我们使用作者发布的代码,将我们的特征集成到[59]中提出的管道的两个变体中。
The first variant, Direct Pose Es-timation (PE), matches features between the query image and the top-ranked database image found by image retrieval [3] and uses these matches for pose estimation.
第一种变体,即直接姿势估计(PE),将查询图像与通过图像检索找到的排名靠前的数据库图像进行特征匹配[3],并利用这些匹配进行姿势估计。
In the second variant, Sparse PE, the query is matched against the top-100 retrieved images, and a spatial verification [40] step is used to reject outliers matches.
在第二种变体稀疏PE中,查询与检索到的前100张图像进行匹配,并使用空间验证[40]步骤来拒绝异常值匹配。
The query camera pose is then estimated using the database image with the largest number of verified matches.
然后使用经过验证匹配次数最多的数据库图像估计查询相机姿态。
第八段(图表表明本文方法优于两个基线)
Tab. 2 compares our approach with baselines from [59]: The original Direct / Sparse PE pipelines are based on affine covariant features with RootSIFT descriptors [4, 30, 32].
表2将我们的方法与[59]中的基线进行了比较:原始的Direct / Sparse PE管道基于具有RootSIFT描述符的仿射协变特征[4,30,32]。
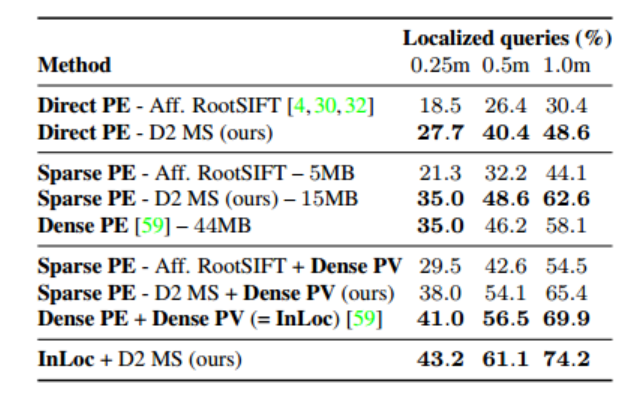
Table 2: Evaluation on the InLoc dataset [59]. Our method outperforms SIFT by a large margin in both Direct PE and Sparse PE setups. It also outperforms the dense matching Dense PE method
when used alone, while requiring less memory during pose estimation. By a combined approach of D2 and InLoc we obtained a new state-of-the art on this dataset.
表2:对InLoc数据集的评估[59]。我们的方法在直接PE和稀疏PE设置中都大大优于SIFT。当单独使用时,它也优于dense PE方法,同时在姿态估计时需要更少的内存。通过D2和InLoc的组合方法,我们在这个数据集上获得了一个新的最先进的方法。
Dense PE matches densely extracted CNN descriptors between the images (using guided matching from the conv5 to the conv3 layer in a VGG16 network).
密集PE匹配图像之间密集提取的CNN描述符(使用VGG16网络中从conv5到conv3层的引导匹配)。
As in [59], we report the percentage of query images localized within varying thresholds on their position error, considering only images with an orientation error of 10◦ or less.
如[59]所述,我们报告了定位在不同位置误差阈值内的查询图像的百分比,仅考虑方向误差小于10◦的图像。
We also report the average memory usage of features per image.
我们还报告每个图像的特性的平均内存使用情况。
As can be seen, our approach outperforms both baselines.
可以看到,我们的方法优于两个基线。
第九段(说明实验结果)
In addition to Dense PE, the InLoc method proposed in [59] also verifies its estimated poses using dense information (Dense Pose Verification (PV)): A synthetic image is rendered from the estimated pose and then compared to the query image using densely extracted SIFT descriptors.
除了 Dense PE,[59] 中提出的 InLoc 方法还使用密集信息验证其估计姿势(密集姿势验证 (PV)):根据估计姿势渲染合成图像,然后使用密集提取的 SIFT 描述符与查询图像进行比较。
A similarity score is computed based on this comparison and used to re-rank the top-10 images after Dense PE.
基于这种比较计算相似度分数,并用于在Dense PE之后重新排列前10个图像。
Only this baseline outperforms our sparse feature approach, albeit at a higher computational cost.
只有这个基线优于我们的稀疏特征方法,尽管计算成本更高。
Combining our approach with Dense PV also improves performance, but not to the level of InLoc.
将我们的方法与Dense PV相结合也提高了性能,但没有达到InLoc的水平。
This is not surprising, given that InLoc is able to leverage dense data.
这并不奇怪,因为InLoc能够利用密集数据。
Still, our results show that sparse methods can perform close to this strong baseline
尽管如此,我们的结果表明,稀疏方法可以执行接近这个强基线
第十段(融合两种算法)
Finally, by combining our method and InLoc, we were able to achieve a new state of the art — we employed a pose selection algorithm using the Dense PV scores for the top 10 images of each method.
最后,通过将我们的方法和InLoc相结合,我们能够实现一个新的艺术状态——我们使用了一种姿态选择算法,使用每种方法的前10张图像的Dense PV分数。
In the end, 182 Dense PE poses and 174 Sparse PE (using D2 MS) poses were selected.
最后,选择了182个密集PE位姿和174个稀疏PE位姿(使用D2 MS)。
6. Conclusions 结论
第一段(本文提出新的方法进行局部特征检测)
We have proposed a novel approach to local feature extraction using a describe-and-detect
methodology.
我们提出了一种利用描述-检测方法提取局部特征的新方法。
The detection is not done on low-level image structures but postponed until more reliable information is available, and done jointly with the image description.
检测不是在底层图像结构上进行,而是推迟到有更可靠的信息可用时,并与图像描述一起进行。
We have shown that our method surpasses the state-of-the-art in camera localization under challenging conditions such as day-night changes and indoor scenes.
我们已经证明,在昼夜变化和室内场景等具有挑战性的条件下,我们的方法在相机定位方面超越了最先进的技术。
Moreover, even though our features are less well-localized compared to classical feature detectors, they are also suitable for 3D reconstruction.
此外,尽管与经典特征检测器相比,我们的特征定位不太好,但它们也适用于3D重建。
第二段(未来工作)
An obvious direction for future work is to increase the accuracy at which our keypoints are detected.
未来工作的一个明显方向是提高关键点检测的准确性。
This could for example be done by increasing the spatial resolution of the CNN feature maps or by regressing more accurate pixel positions.
例如,这可以通过增加CNN特征图的空间分辨率或通过回归更精确的像素位置来实现。
Integrating a ratio test-like objective into our loss could help to improve the performance of our approach in applications such as SfM.
将类似比率测试的目标集成到我们的损失中可以帮助提高我们的方法在SfM等应用程序中的性能。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









