




 本文提出了一种基于多模态Transformer的脑肿瘤分割模型,利用U-Net结构,通过模态专用编码器处理每个模态的特征,多模态Transformer学习缺失模态,共享权重解码器融合多模态特征。实验在BraTS数据集上展示了其性能,但方法对模态信息依赖性及训练数据完整性有局限性。
本文提出了一种基于多模态Transformer的脑肿瘤分割模型,利用U-Net结构,通过模态专用编码器处理每个模态的特征,多模态Transformer学习缺失模态,共享权重解码器融合多模态特征。实验在BraTS数据集上展示了其性能,但方法对模态信息依赖性及训练数据完整性有局限性。
Ting H, Liu M. Multimodal Transformer of Incomplete MRI Data for Brain Tumor Segmentation[J]. IEEE Journal of Biomedical and Health Informatics, 2023. 【代码开源】
论文概述
本文提出了一种基于多模态Transformer网络的不完全多模态MRI数据的脑肿瘤分割方法。该网络基于U-Net体系结构,由模态专用编码器、多模态Transformer和多模态共享权重解码器组成。首先,构建一个卷积编码器来提取每个模态的具体特征。然后,提出一种多模态Transformer来建模多模态特征的相关性,并学习缺失模态的特征。最后,提出一种多模态共享权重解码器,将多模态和多级特征与空间和通道自注意模块逐步聚合,用于脑肿瘤分割。
网络结构
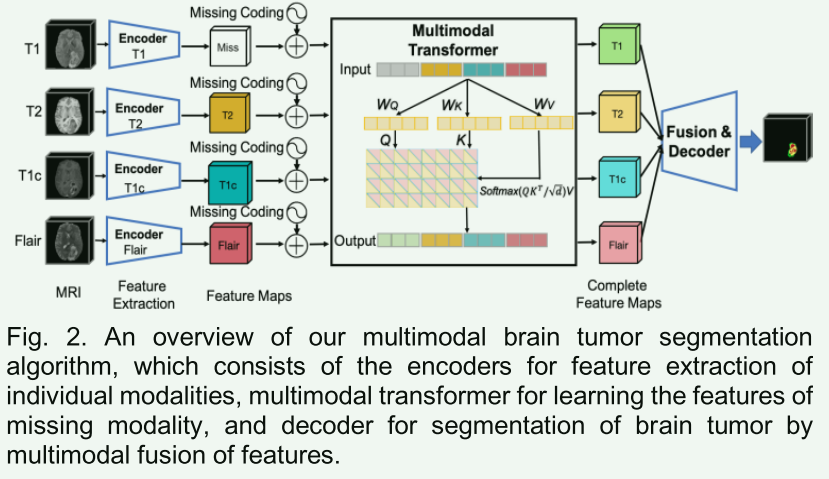
-
Modality specific feature learning
这一步类似MMFormer,每个模态单独编码,然后使用类似dropout机制随机丢弃一些模态来模拟缺失模态。网上有很多关于MMFormer的解读,不再赘述。与MMFormer不同在于,在每个模态的每个特征提取层级都进行了特征拼接和dropout。具体如下:文中定义 S P m , k S P_{m, k} SPm,k为编码器从第 m m m个模态中提取的第 k k k个级别特征,其中 m ∈ { 1 , 2 , 3 , 4 } m \in\{1,2,3,4\} m∈{ 1,2,3,4},对应MRI中的四个模态 { Flair , T 1 , T 2 , T 1 c } \{\text { Flair }, T 1, T 2, T 1 c\} { Flair ,T1,T2,T1c},进行对应特征拼接后得到四种模态在各个层级的特征拼接: S P k = [ S P 1 , k , S P 2 , k , S P 3 , k , S P 4 , k ] S P_{k}=\left[S P_{1, k}, S P_{2, k}, S P_{3, k}, S P_{4, k}\right] SPk=
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 450
450

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









