







目录
深度学习训练是将数据输入到模型中,调整模型的参数(例如神经网络中的权重)以使其能够准确预测或分类新数据的过程。模型训练的主要目标是通过不断优化模型参数来最小化损失函数(例如,交叉熵、均方误差等),从而提高模型在测试数据上的泛化能力。常用的训练方式包括CPU训练、GPU训练以及多GPU训练。
1.CPU训练
在全连接神经网络中,CPU会按照顺序依次计算每个神经元的输入,通过矩阵乘法计算权重与输入的乘积,然后加上偏置,再应用激活函数得到输出。这种顺序执行的方式对于大规模的深度学习计算来说效率较低,因为深度学习中的计算任务通常包含大量的并行计算机会,而CPU的核心数量相对较少,且每个核心的计算能力有限。在CPU训练时,这些运算会按顺序依次执行。例如,对于一个简单的全连接层,CPU会逐个计算神经元的输入和输出。
在MATLAB中,深度学习工具箱默认会根据系统配置自动选择合适的计算设备(CPU 或 GPU)。如果要明确指定使用CPU进行训练,可以通过设置训练选项来实现。以下是一个简单的示例,展示如何使用 MATLAB进行CPU训练。
% 设置训练选项
options = trainingOptions('sgdm', ...
'MaxEpochs', 100, ...
'MiniBatchSize', 10, ...
'Verbose', false, ...
'ExecutionEnvironment', 'cpu'); % 指定使用 CPU 进行训练2.GPU训练
GPU(图形处理器)最初设计用于处理图形渲染任务,其具有大量的计算核心(数以千计),能够实现高度并行计算。在深度学习中,GPU利用其并行计算能力来加速神经网络的训练。GPU 的架构允许同时处理多个数据元素,例如在矩阵乘法中,可以同时计算多个矩阵元素的乘积,大大提高了计算效率。
GPU通常采用SIMT(单指令多线程)架构,即一条指令可以同时应用于多个线程。每个线程可以处理不同的数据元素,从而实现并行计算。在深度学习中,GPU将神经网络的计算任务分解为多个小任务,分配给不同的线程进行处理。例如,在卷积神经网络(CNN)中,GPU可以同时计算多个卷积核与输入特征图的卷积操作,从而加快训练速度。
相较于CPU(中央处理单元),GPU在并行处理和浮点运算上具有显著优势,使得深度学习模型的训练速度大大提升。以下是GPU和CPU的对比:

以下是一个简单的示例,展示如何使用MATLAB进行GPU训练。
% 设置训练选项
options = trainingOptions('sgdm', ...
'MaxEpochs', 100, ...
'MiniBatchSize', 10, ...
'Verbose', false, ...
'ExecutionEnvironment', 'gpu'); % 指定使用 CPU 进行训练GPU训练的流程如下所示:
数据传输:将训练数据从主机内存(CPU 内存)传输到GPU内存。这是因为GPU计算需要数据在其本地内存中进行处理。数据传输通常通过PCIe总线进行,虽然传输速度相对较快,但仍然会带来一定的开销。
模型初始化:在GPU内存中初始化神经网络模型的参数。GPU会为权重和偏置分配内存空间,并设置初始值。
前向传播:利用GPU的并行计算能力,同时计算神经网络中各个层的输出。例如,在卷积层中,GPU可以同时计算多个卷积核与输入特征图的卷积操作,然后将结果相加并应用激活函数。在全连接层中,GPU可以并行计算矩阵乘法和激活函数,大大提高了计算效率。
损失计算:在GPU上计算损失函数的值。由于GPU具有强大的计算能力,可以快速地计算大规模数据的损失值。
反向传播:通过链式法则计算损失函数对模型参数的梯度。GPU利用并行计算能力,同时计算多个参数的梯度,从而加速反向传播过程。例如,在计算卷积层的梯度时,GPU可以同时计算多个卷积核的梯度。
参数更新:根据计算得到的梯度,使用优化算法更新模型的参数。GPU会在其内存中更新权重和偏置的值,并将更新后的参数传输回主机内存(如果需要)。
重复训练:重复以上步骤,直到达到预定的训练次数或满足停止条件。在每次训练迭代中,GPU 不断地进行前向传播、反向传播和参数更新操作,逐步优化模型的性能。
3.多GPU训练
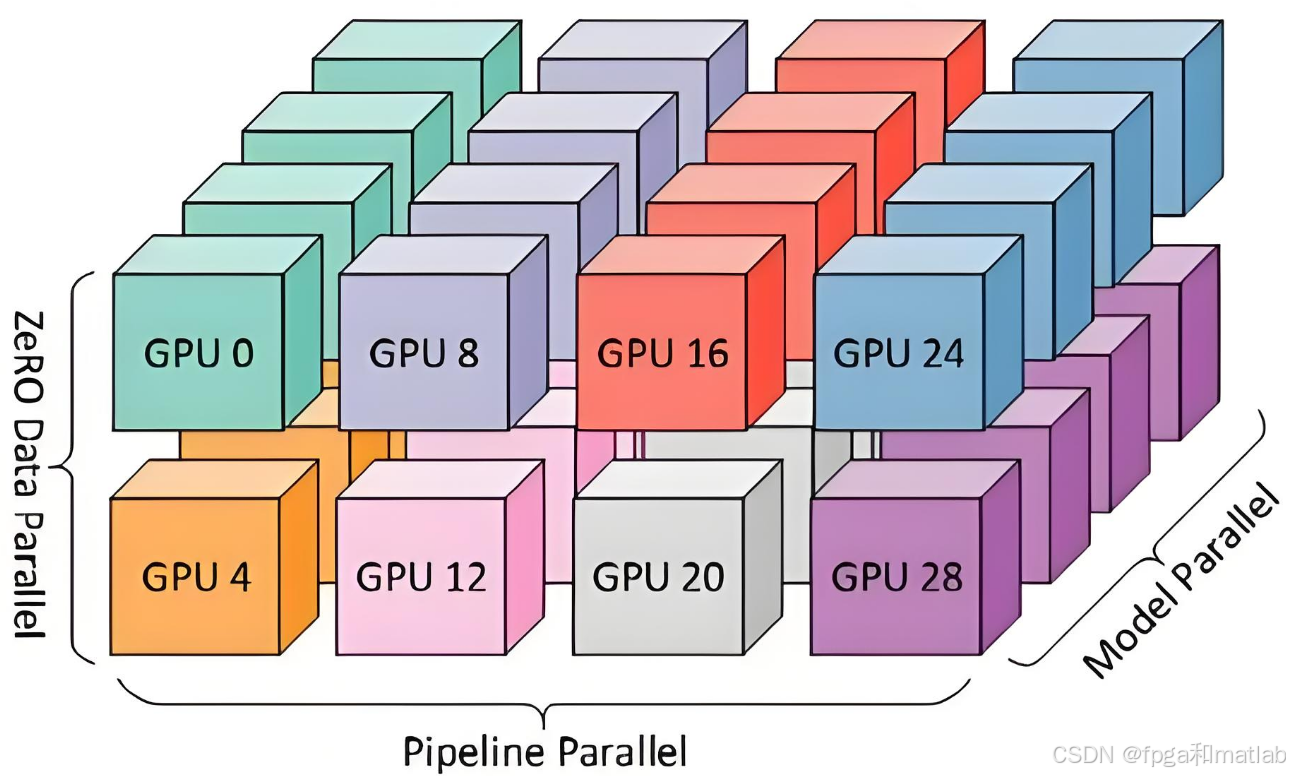
多GPU训练是为了进一步加速深度学习模型的训练过程,通过将计算任务分配到多个GPU上并行执行,从而提高计算效率和处理大规模数据的能力。多GPU训练的核心思想是利用多个GPU 的计算资源,同时处理不同的部分或不同的数据样本,以加快训练速度。多GPU间的通信通常通过高速互联网络(如 NVLink)进行,这种网络能够提供高带宽和低延迟的数据传输,确保多个GPU之间能够有效地协同工作。在多GPU训练中,需要解决数据同步、负载均衡和通信开销等问题,以充分发挥多个GPU的性能优势。
多GPU训练的流程如下所示:
环境设置:配置多GPU环境,包括安装相应的GPU驱动、深度学习框架(如 TensorFlow、PyTorch 等)以及设置多 GPU 支持的相关参数。确保多个GPU能够正常工作并相互通信。
数据划分:根据不同的多GPU训练方式(如数据并行、模型并行等),将训练数据划分为多个部分,分配给不同的GPU进行处理。例如,在数据并行中,将数据样本平均分配到各个GPU上;在模型并行中,根据模型的结构将不同的层分配给不同的GPU。
模型初始化:在每个GPU上初始化神经网络模型的参数。可以选择在一个GPU上初始化模型,然后将参数复制到其他GPU上,或者在每个GPU上独立初始化相同的模型参数。
训练迭代:在每次训练迭代中,根据选择的多GPU训练方式,各个GPU分别执行相应的计算任务。例如,在数据并行中,各个GPU同时对分配到的数据样本进行前向传播、反向传播和参数更新操作;在模型并行中,各个GPU分别计算模型的不同部分,然后通过通信将中间结果传递给其他GPU,以完成整个模型的计算。
参数同步:在多GPU训练过程中,需要确保各个GPU上的模型参数保持一致。对于数据并行,通常在每次迭代结束后,将各个GPU上计算得到的梯度进行汇总和平均,然后更新所有GPU上的模型参数;对于模型并行,需要在不同GPU之间传递中间结果和参数更新信息,以保证模型的一致性。
目前,多GPU训练模式包括:模型并行,数据并行,张量并行,序列并行。
3.1 模型并行
模型并行是将神经网络模型的不同部分分配到不同的GPU上进行计算。这种方式适用于模型规模较大,单个 GPU 的内存无法容纳整个模型的情况。通过将模型划分为多个部分,每个GPU负责计算模型的一部分,然后通过通信将中间结果传递给其他GPU,以完成整个模型的计算。
例如,在一个深度神经网络中,可以将网络的前几层分配给一个GPU,后几层分配给另一个 GPU。在前向传播过程中,第一个GPU计算前几层的输出,并将结果传递给第二个GPU;第二个 GPU接收结果后,继续计算后几层的输出。在反向传播过程中,第二个GPU计算后几层的梯度,并将结果传递给第一个GPU;第一个GPU接收结果后,计算前几层的梯度。
3.2 数据并行
数据并行是将训练数据划分为多个部分,分配给不同的GPU上同时进行计算。每个GPU上都有相同的模型副本,对分配到的数据部分进行前向传播、反向传播和参数更新操作。在每次迭代结束后,将各个GPU上计算得到的梯度进行汇总和平均,然后更新所有GPU上的模型参数,以保证模型的一致性。
数据并行的优点是实现相对简单,适用于大多数深度学习模型,尤其是当数据量较大时,可以充分利用多个GPU的计算资源加速训练过程。缺点是当模型规模较大时,每个GPU都需要存储完整的模型副本,可能会导致GPU内存不足的问题。
3.3 张量并行
张量并行是一种更细粒度的并行方式,它将张量(如矩阵)的计算任务分解为多个部分,分配给不同的GPU上进行并行计算。这种方式可以进一步提高计算效率,尤其是对于大规模的张量计算任务。
例如,在矩阵乘法中,可以将矩阵的行或列划分到不同的GPU上,每个GPU分别计算分配到的部分的乘积,然后通过通信将结果合并得到最终的矩阵乘积。张量并行需要更复杂的通信和同步机制,以确保各个GPU之间的计算结果能够正确合并。
3.4 序列并行
序列并行主要适用于处理序列数据(如文本、语音等)的神经网络模型,如循环神经网络(RNN)、长短期记忆网络(LSTM)等。它将序列数据的不同时间步分配到不同的GPU上进行计算,从而实现并行处理。
例如,在处理一段文本序列时,可以将序列的前几个时间步分配给一个GPU,后几个时间步分配给另一个GPU。在前向传播过程中,第一个GPU计算前几个时间步的输出,并将结果传递给第二个GPU;第二个GPU接收结果后,继续计算后几个时间步的输出。在反向传播过程中,第二个GPU计算后几个时间步的梯度,并将结果传递给第一个GPU;第一个GPU 接收结果后,计算前几个时间步的梯度。


















 1315
1315

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











