








目录
在传统监督学习范式中,模型需要大量标注数据才能达到理想性能。然而,在许多现实场景中(如医疗影像分析、稀有物种识别、历史文本分类等),标注数据极度稀缺。小样本学习(Few-Shot Learning, FSL)旨在解决这一问题,其核心目标是通过少量标注样本(通常为 1-5 个)训练模型,使其能够对新类别进行有效分类或回归。本文将深入探讨小样本监督学习的核心原理、数学模型及前沿方法。小样本监督学习通过元学习、生成模型、度量学习等技术,突破了传统监督学习对大规模数据的依赖。随着理论研究的深入和计算能力的提升,其在医疗、金融、智能制造等领域的应用将更加广泛。
1.监督学习的基础框架
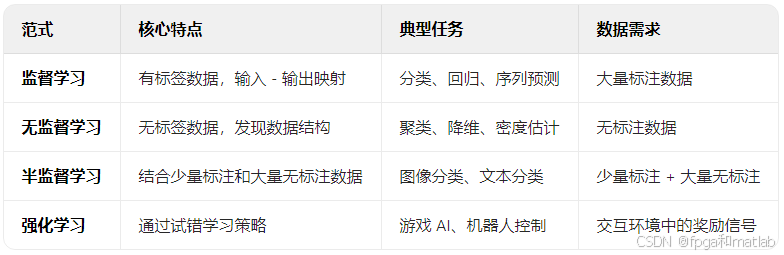
监督学习是机器学习的核心范式之一,其核心目标是通过有标签数据(Labeled Data)构建一个输入到输出的映射函数f:X→Y。在监督学习中,数据样本由特征向量x∈X和对应的标签y∈Y组成,模型通过优化目标函数(如损失函数)来拟合数据中的潜在规律。监督学习的典型任务包括分类(Classification)、回归(Regression)、序列预测(Sequence Prediction)等。
监督学习与其他学习范式的对比
1.1 经验风险最小化

1.2 过拟合与偏差-方差权衡
小样本场景下,模型容易陷入过拟合,表现为训练误差低但泛化能力差。根据偏差 - 方差分解:

小样本导致方差项显著增大,需通过正则化、数据增强等手段控制。
2.小样本学习的核心挑战

对于无限假设空间(如深度神经网络),需用VC维或Rademacher复杂度替代∣H∣。小样本条件下,该不等式右端项可能远大于可用样本数,导致学习不可行。少量样本难以覆盖特征空间的多样性,使得最近邻、支持向量机等基于局部相似性的方法性能下降。
另外一方面,在小样本条件下,模型参数与样本数量的比例失衡引发记忆效应。实验表明,当样本量低于模型容量的1/1000时,深度神经网络会优先记忆噪声而非学习数据本质特征。例如在 5-shot图像分类任务中,ResNet-50模型可能将背景纹理误判为类别区分特征,导致测试集准确率下降20-30%。这种过拟合现象可通过偏差 - 方差分解解释:当样本量不足时,模型方差项主导泛化误差,使模型对训练数据的微小扰动极度敏感。
现有小样本学习方法在域迁移场景中表现出显著局限性。以跨模态医学影像诊断为例,基于 MRI 训练的模型在迁移至 CT 影像时,诊断准确率可能骤降 40% 以上。这种性能衰减源于分布偏移(Distribution Shift)问题,具体表现为:
1.特征空间错位:不同模态数据的底层特征分布存在显著差异;
2.标签空间歧义:同一语义标签在不同模态中的表现形式不同;
3.概念漂移:数据分布随时间或采集设备变化。
3.小样本监督学习
3.1 元学习(Meta-Learning)
元学习旨在让模型从多个任务中学习 “学习能力”,从而快速适应新任务。核心思想是在元训练阶段优化模型参数,使其在新任务上通过少量样本快速收敛。


3.2 数据增强与生成模型
通过生成对抗网络(GAN)或变分自编码器(VAE)合成新样本,缓解数据稀缺问题。
1.GAN

2.基于流形学习的增强

3.3 度量学习
构建特征空间,使得同类样本距离更近,异类样本距离更远。常用方法包括:
原型网络

孪生网络

3.4 迁移学习
将预训练模型在源域上的知识迁移到目标域。核心是通过最小化域间分布差异:



















 1084
1084

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











