







目录
贪吃蛇(Snake)是一款经典的电子游戏,玩家通过控制一条不断变长的蛇来吃掉地图上的食物,同时避免撞到墙壁或自己的身体。近年来,随着深度学习和强化学习技术的发展,利用算法自动玩游戏已经成为一个热门的研究方向。Actor是一个神经网络,Critic也是一个神经网络,他们是不同的神经网络,Actor用于预测行为的概率,Critic是预测在这个状态下的价值。结合了Policy Gradient(Actor)和Function Approximation(Critic)的方法,Actor基于概率选行为,Critic(可以用Q-learning或者Value-based)估计每一个状态的价值,用这个状态的价值减去下个状态的价值,(TD-error),Critic就告诉actor下一个动作要被加大更新的,TD-error如果是正的,下个动作就要加大更新,如果是负的,就减小actor的更新幅度,Criric基于Actor的行为评判行为的得分,Actor根据Critic的评分修改选行为的概率。本文将探讨如何使用基于Actor-Critic结构的强化学习方法来设计贪吃蛇游戏的智能控制策略。
1.Actor-Critic架构理论基础
强化学习是一种机器学习方法,它使代理能够在环境中通过与环境交互来学习最优的行为策略。其核心思想是代理通过观察环境状态、采取行动并获得奖励或惩罚来学习如何最大化累积奖励。强化学习是一种通过试错方式让智能体(Agent)在与环境交互的过程中学习最佳行为策略的方法。其基本框架包含三个核心元素:智能体、环境以及奖励机制。
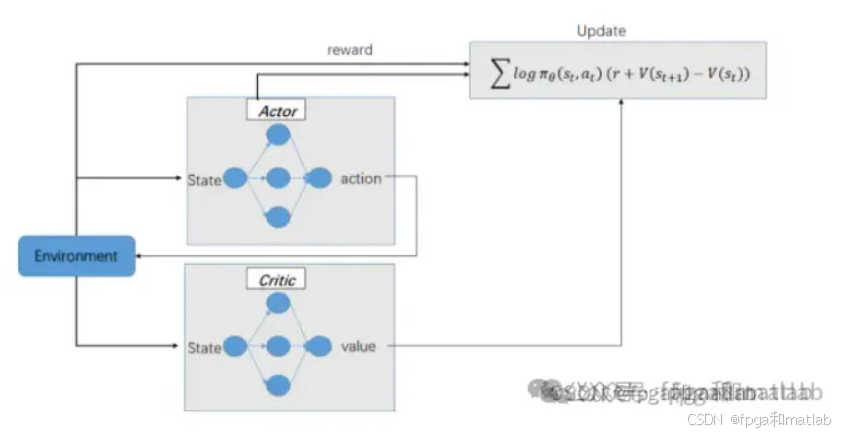
Actor-Critic方法结合了策略梯度(Policy Gradient)和价值函数(Value Function)两种方法的优点,通过两个网络协同工作来优化策略。 Actor-Critic结构的网络模型如下图所示:

2.基于强化学习的贪吃蛇游戏控制策略
传统的贪吃蛇游戏中,玩家通常根据直觉和经验来操作。然而,基于强化学习的方法试图让计算机通过与环境交互来学习最优策略。DQN(Deep Q-Network)、A3C(Asynchronous Advantage Actor-Critic)等算法已被应用于各种游戏场景中,并取得了显著成果。Actor-Critic方法因其良好的性能表现和相对简单的实现过程而受到广泛关注。它结合了价值函数估计(Critic)和直接优化策略(Actor),能够在保持稳定训练的同时提高样本效率。
贪吃蛇游戏环境设置
1. 游戏规则
-
贪吃蛇初始长度为固定值,每吃到一个食物后长度增加。
-
蛇头碰到墙壁或自身身体时游戏结束。
-
每次移动可以获得一定分数,吃到食物得分更高。
2. 状态空间与动作空间
-
状态空间:可以选择使用游戏屏幕的像素矩阵作为输入,也可以设计更紧凑的状态表示,比如蛇头的位置、速度以及最近的食物位置等。
-
动作空间:常见的四个离散动作——上、下、左、右。
3. 奖励函数设计
合理的奖励函数对于引导智能体学习至关重要。对于贪吃蛇游戏,可以考虑以下几种奖励机制:
-
吃到食物时给予正向奖励。
-
随着时间推移给予轻微负向奖励,鼓励快速行动。
-
碰撞墙壁或自身时给予较大惩罚。
3.MATLAB程序
定义A2C网络结构:
criticNetwork = [
imageInputLayer([numObservations 1 1],'Normalization','none','Name','state')
fullyConnectedLayer(32,'Name','CriticStateFC1')
reluLayer('Name','CriticRelu1')
fullyConnectedLayer(32,'Name','CriticStateFC2')
reluLayer('Name','CriticRelu2')
fullyConnectedLayer(32,'Name','CriticStateFC3')
reluLayer('Name','CriticRelu3')
fullyConnectedLayer(1, 'Name', 'CriticFC')];
criticOpts = rlRepresentationOptions('LearnRate',learnrate,'GradientThreshold',1);
critic = rlRepresentation(criticNetwork,obsInfo,'Observation',{'state'},criticOpts);
actorNetwork = [
imageInputLayer([numObservations 1 1],'Normalization','none','Name','state')
fullyConnectedLayer(32, 'Name','ActorStateFC1')
reluLayer('Name','ActorRelu1')
fullyConnectedLayer(32, 'Name','ActorStateFC2')
reluLayer('Name','ActorRelu2')
fullyConnectedLayer(32, 'Name','ActorStateFC3')
reluLayer('Name','ActorRelu3')
fullyConnectedLayer(numActions,'Name','action')];
actorOpts = rlRepresentationOptions('LearnRate',learnrate,'GradientThreshold',1);
actor = rlRepresentation(actorNetwork,obsInfo,actInfo,...
'Observation',{'state'},'Action',{'action'},actorOpts);定义贪吃蛇:
classdef snake_class < snake_env
methods
function this = snake_class()
ActionInfo = rlFiniteSetSpec([1 2 3 4]);
this = this@snake_env(ActionInfo);
updateActionInfo(this);
end
end
methods (Access = protected)
function force = getForce(this,action)
if ~ismember(action,this.ActionInfo.Elements)
error(message('bad direction'));
end
force = action;
end
function updateActionInfo(this)
this.ActionInfo.Elements = [1 2 3 4];
end
end
end定义训练器:
agent = rlACAgent(actor,critic,agentOpts);
trainOpts = rlTrainingOptions(...
'MaxEpisodes',10000000,...
'MaxStepsPerEpisode',999999999,...
'Verbose',false,...
'SaveAgentCriteria',"EpisodeReward",...
'SaveAgentValue',300,...
'SaveAgentDirectory', pwd + "test4batch1\Agents",... % refresh the batch! %%%%%%%%%%%%%
'Plots','training-progress',...
'StopTrainingCriteria','AverageReward',...
'StopTrainingValue',2000,...
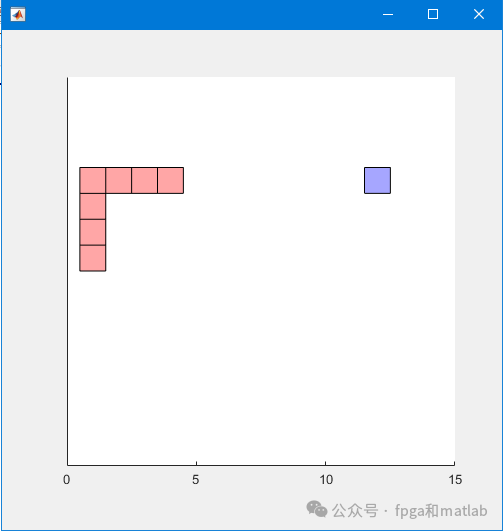
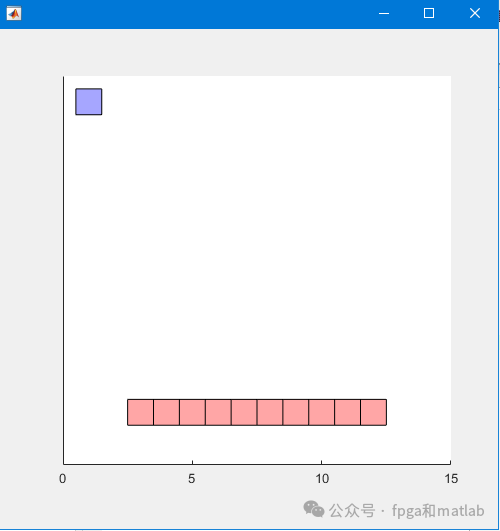
'ScoreAveragingWindowLength',100);测试效果如下图所示:



















 997
997

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











