




1、简介
scikit-learn是Python的科学计算工具,主要提供以下功能:
- 分类(Classification)
- 回归(Regression)
- 聚类(Clustering)
- 降维(Dimensionality reduction)
- 模型评估(Model selection and evaluation)
- 数据预处理(Preprocessing)
- 内置样本集(Data set)
附上sklearn官网链接:https://scikit-learn.org/stable/

2、使用示例
import numpy as np
from sklearn.cluster import KMeans
# 编制数据
X = np.array([0, 1, 2, 7, 8, 9])
# 建模
model = KMeans(n_clusters=2)
# 训练
model.fit(X.reshape(-1, 1))
# 获取标签
labels = KMeans(n_clusters=2).fit(X.reshape(-1, 1)).labels_
-
print(X, labels, sep=’\n’)
-
[0 1 2 7 8 9]
[0 0 0 1 1 1]
3、各算法接口
| 分类 | Classification |
|---|---|
| 逻辑回归 | from sklearn.linear_model import LogisticRegression |
| 朴素贝叶斯 | from sklearn import naive_bayes |
| 决策树与随机森林 | from sklearn.tree import DecisionTreeClassifierfrom sklearn.ensemble import RandomForestClassifier |
| 支持向量机 | from sklearn.svm import SVC |
| 回归 | Regression |
|---|---|
| 线性回归 | from sklearn.linear_model import LinearRegression |
| 聚类 | Clustering |
|---|---|
| 聚类 | from sklearn import cluster |
| 降维 | Dimensionality reduction |
|---|---|
| 主成分分析 | from sklearn.decomposition import PCA |
| 线性判别分析 | from sklearn.discriminant_analysis import LinearDiscriminantAnalysis |
| 模型选择与评估 | Model selection and evaluation |
|---|---|
| 数据切分 | from sklearn.model_selection import train_test_split |
| 交叉验证 | from sklearn.model_selection import cross_val_score |
| 评分 | from sklearn import metrics |
| 混淆矩阵 | from sklearn.metrics import confusion_matrix |
| 召回率 | from sklearn.metrics import recall_score |
| 轮廓系数 | from sklearn.metrics import silhouette_score |
| 数据预处理 | Preprocessing |
|---|---|
| 数据标准化 | from sklearn.preprocessing import MinMaxScaler, StandardScaler |
| 数据集 | Data sets |
|---|---|
| 创建随机样本的函数 | from sklearn.datasets.samples_generator import make_blobs |
| 可直接加载的样本 | from sklearn.datasets import load_boston |
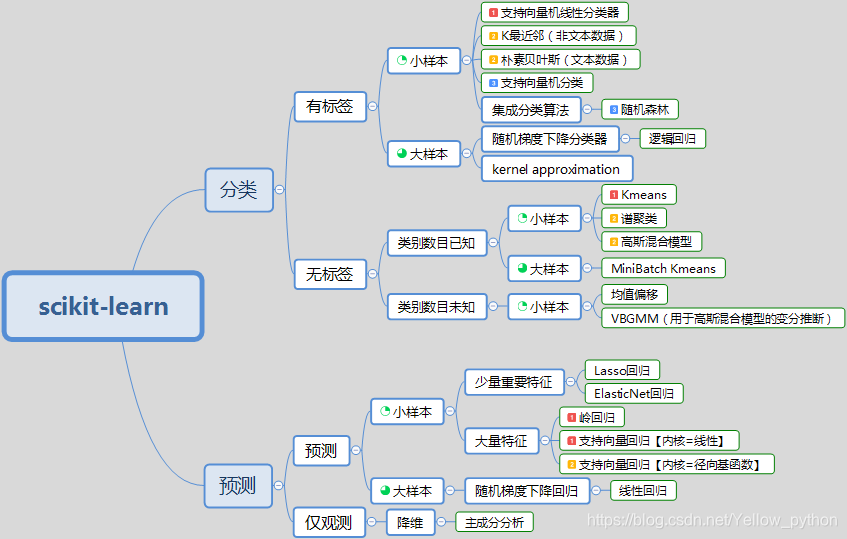
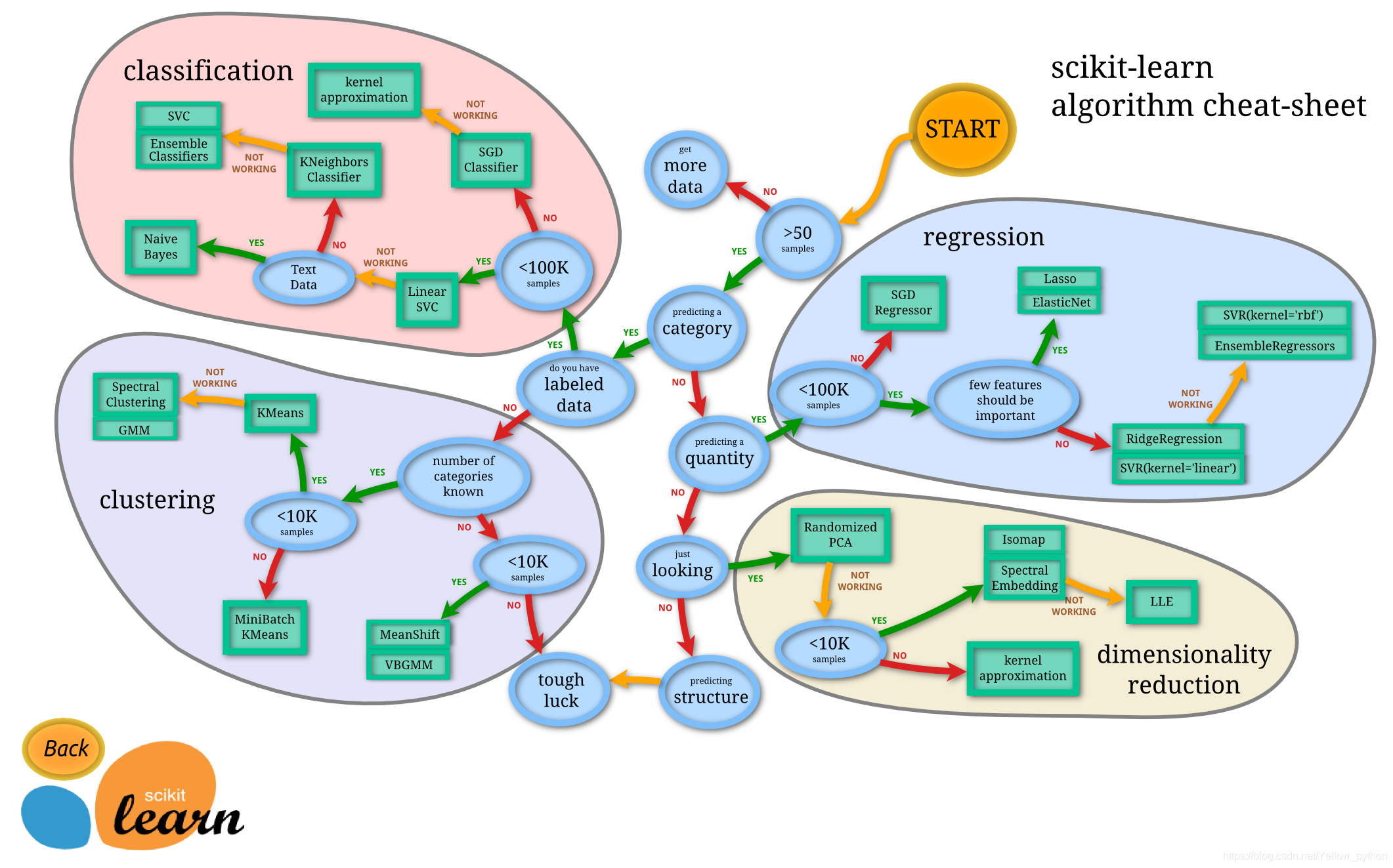
4、模型选择导航
5、附录
sklearn版本:0.19.1
专名
| en | cn |
|---|---|
| 【Classification】 | 【分类】 |
| SGD | 随机梯度下降(stochastic gradient descent) |
| kernel approximation | 核近似 |
| SVM | 支持向量机(support vector machine) |
| Linear SVC | 用于分类的线性可扩展支持向量机 (Scalable Linear Support Vector Machine for classification) |
| Naive Bayes | 朴素贝叶斯 |
| K Nearest Neighbor | K最近邻 |
| 【Regression】 | 【回归】 |
| Lasso | Lasso回归 (Least Absolute Shrinkage and Selection Operator) |
| ElasticNet | ElasticNet回归 |
| SVR | 用于回归的支持向量机 (Support Vector Machine for Regression) |
| RBF | 径向基函数(Radial Basis Function) |
| 【Clustering】 | 【聚类】 |
| GMM | 高斯混合模型(Mixtore of Gaussian) |
| Spectral Clustering | 谱聚类 |
| VBGMM | 用于高斯混合模型的变分推断 (Variational Inference for the Gaussian Mixture Model) |
| Variational Inference | 变分推断 |
| Mean Shift | 均值偏移 |
| 【Dimensionality reduction】 | 【降维】 |
| PCA | 主成分分析(Principal Component Analysis) |
| LDA | 线性判别分析(Linear Discrimination Analysis) |
| Factor Analysis | 因子分析 |
| isomap | 等距映射 |
| Spectral Embedding | 谱嵌入【非线性降维】 (Spectral embedding for non-linear dimensionality reduction) |
| LLE | 局部线性嵌入算法(Locally Linear Embedding) |
注释
| en | cn |
|---|---|
| metric | n. 度量标准 |
| batch | n. 批次;vt. 分批处理 |
| ridge | 山脊 |
| elastic | n. 橡皮圈;adj. 有弹性的 |
| lasso | n. 套索;vt. 拉拢 |
| ensemble | n. 全体、合奏;adv. 同时 |
| scalable | 可称量的 |
| spectral | 光谱的;幽灵的 |


















 1264
1264

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











