




首先,我想说明下问什么要学习SKlearn:
SKlearn是python的机器学习库,它是基于numpy,pandas,scipy,matplotlib上的,
涵盖了机器学习中数据预处理(很重要),模型选择,数据引入,有监督的回归,分类,无监督的聚类和降维,功能非常全面,是传统机器学习库的首选者.
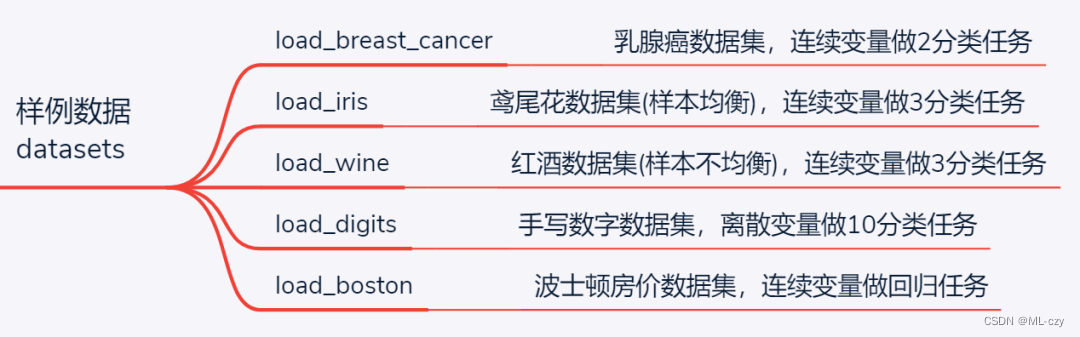
首先,我们看看它是怎样引入数据集的:
from sklearn.datasets import load_iris
iris = load_iris()
iris.keys()#查看键值,方便对数据集进行处理
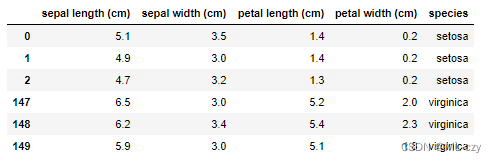
用pandas直观的表示下数据集:
iris_load = pd.DataFrame(iris.data,columns=iris.feature_names)#DataFrame函数合并x和y
iris_load['species'] = iris.target_names[iris.target]#添加一列'species'
核心 API:
可把它不严谨的当成一个模型 (用来回归、分类、聚类、降维),或当成一套流程 (预处理、网格最终)。
本节三大 API 其实都是估计器:
估计器 (estimator) 当然是估计器
预测器 (predictor) 是具有预测功能的估计器
转换器 (transformer) 是具有转换功能的估计器
接下来,我们看看有监督学习中的线性回归:
直接介绍前两个API
from sklearn.linear_model import LinearRegression
import numpy as np
model = LinearRegression()
X = np.array([[1,1],[1,2],[2,2],[2,3]])
y = np.dot(X,np.array([1,2])) + 3
model = LinearRegression().fit(X,y)#--->到这是估计器
model.score(X,y)#返回决定系数,该系数用于观察数据拟合程度
model.predict(np.array([[2,5]]))#输入数据进行预测--->到这是预测器
然后是无监督的Kmeans聚类:
这里继续沿用上面的数据集
from sklearn.cluster import KMeans
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
iris = load_iris()
X_train,X_test,y_train,y_test = train_test_split(iris['data'],
iris['target'],
test_size=0.2)#数据集划分的模版
model = KMeans( n_clusters=3 )#三个簇
X = iris.data[:,0:2]#这里切去前两个特征数据,方便可视化处理
model.fit(X)#训练
idx_pred = model.predict( X_test[:,0:2] )#预测
最后进行可视化处理
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import numpy as np
from matplotlib.colors import ListedColormap, LinearSegmentedColormap
model = KMeans(n_clusters=3)
model.fit(X_train[:,0:2])
idx_pred = model.predict(X_test[:,0:2])
#print(idx_pred)
#print(y_test)
cmap_light = ListedColormap(["#FFAAAA",'#AAFFAA','#AAAAFF'])
cmap_bold1 = ListedColormap(["#FFAAAA",'#AAFFAA','#AAAAFF'])
cmap_bold2 = ListedColormap(["#FFAAAA",'#AAFFAA','#AAAAFF'])
centroid = model.cluster_centers_
true_centroid = np.vstack((X_test[y_test == 0,0:2].mean(axis=0),
X_test[y_test == 1,0:2].mean(axis=0),
X_test[y_test == 2,0:2].mean(axis=0)
))
plt.figure(figsize=(12,6))
plt.subplot(1,2,1)
plt.scatter(X_test[:,0],X_test[:,1],c=idx_pred,cmap=cmap_bold1)
plt.scatter(centroid[:,0],centroid[:,1],marker='o',s=200,
edgecolors='k',c=[0,1,2],cmap=cmap_light)
plt.xlabel('Sepal length(cm)')
plt.ylabel('Sepal length(cm)' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









