




一、SVM分类预测原理
-
最大间隔分类器:
-
SVM的核心思想是寻找一个最优的超平面,使得不同类别的数据点之间的间隔最大化
-
这个超平面被称为"决策边界",它尽可能远离两个类别的数据点
-
-
支持向量:
-
定义决策边界的关键数据点称为"支持向量"
-
这些是距离决策边界最近的数据点,决定了边界的位置
-
只有支持向量对模型有影响,其他点可以忽略
-
-
核技巧:
-
对于线性不可分的数据,SVM使用核函数将数据映射到高维空间
-
在高维空间中,数据可能变得线性可分
-
常用的核函数包括线性核、多项式核、RBF核(高斯核)等
-
-
软间隔分类:
-
在现实数据中,允许一些样本被错误分类,以提高模型的泛化能力
-
通过参数C控制对误分类的惩罚程度
-
-
决策函数:
-
对新样本的预测基于其与支持向量的相对位置
-
通过计算样本点到决策边界的距离和方向来确定类别
-
二、SVM与其他分类算法的优势
-
高维空间有效性:
-
在高维特征空间中表现良好,特别适合特征数多于样本数的情况
-
通过核技巧,可以有效处理非线性问题
-
-
泛化能力强:
-
基于结构风险最小化原则,具有较好的泛化能力
-
对过拟合相对不敏感,特别是当参数选择恰当时
-
-
内存效率高:
-
只需要存储支持向量,而不是整个训练集
-
预测时只与支持向量有关,计算效率较高
-
-
全局最优解:
-
凸优化问题,总能找到全局最优解
-
不像神经网络可能陷入局部最优
-
-
鲁棒性强:
-
对噪声数据相对鲁棒
-
对特征的缩放不敏感(特别是使用RBF核时)
-
-
适用性广泛:
-
可以处理线性和非线性分类问题
-
通过核函数的选择,可以适应各种复杂的数据分布
-
-
解释性相对较好:
-
支持向量提供了对决策边界的直观理解
-
可以分析哪些样本对决策最重要
-
-
参数相对较少:
-
主要参数只有C(正则化参数)和核函数参数
-
相比神经网络等复杂模型,调参相对简单
-
三、SVM算法的应用实例
1.导入第三方库:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split, learning_curve
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
import joblib
import seaborn as sns
from config import SVM_CONFIG, DATA_CONFIG
import warnings
warnings.filterwarnings('ignore')
2.脚本参数配置
# config.py
# SVM配置参数
SVM_CONFIG = {
'random_state': 42,
'test_size': 0.2,
'C': 1.0,
'kernel': 'rbf',
'gamma': 'scale'
}
# 数据配置
DATA_CONFIG = {
'data_path': None, # 使用内置数据集
'target_column': 'target'
}
3.加载数据
def load_and_split_data(self):
"""加载并划分数据"""
print("=" * 60)
print("SVM乳腺癌分类预测系统")
print("=" * 60)
# 加载数据
data = load_breast_cancer()
X = data.data
y = data.target
self.feature_names = data.feature_names
self.target_names = data.target_names
# 划分训练集和测试集
self.X_train, self.X_test, self.y_train, self.y_test = train_test_split(
X, y,
test_size=SVM_CONFIG['test_size'],
random_state=SVM_CONFIG['random_state'],
stratify=y
)
print(f"✓ 数据集加载完成")
print(f" 训练集: {self.X_train.shape[0]} 个样本")
print(f" 测试集: {self.X_test.shape[0]} 个样本")
print(f" 特征数: {self.X_train.shape[1]}")
print(f" 类别: {self.target_names}")
return self
4.训练模型
def train(self):
"""训练SVM模型"""
print("\n" + "=" * 60)
print("训练阶段")
print("=" * 60)
# 创建SVM分类器
self.model = SVC(
C=SVM_CONFIG['C'],
kernel=SVM_CONFIG['kernel'],
gamma=SVM_CONFIG['gamma'],
random_state=SVM_CONFIG['random_state'],
probability=True
)
# 训练模型
self.model.fit(self.X_train, self.y_train)
# 训练集评估
y_train_pred = self.model.predict(self.X_train)
train_accuracy = accuracy_score(self.y_train, y_train_pred)
print(f"✓ SVM模型训练完成")
print(f" 核函数: {SVM_CONFIG['kernel']}")
print(f" 正则化参数 C: {SVM_CONFIG['C']}")
print(f" 训练集准确率: {train_accuracy:.4f}")
return self
5.训练模型
def predict(self):
"""进行预测"""
print("\n正在进行预测...")
# 预测类别
y_pred = self.model.predict(self.X_test)
# 预测概率(如果模型支持)
if hasattr(self.model, 'predict_proba'):
y_pred_proba = self.model.predict_proba(self.X_test)[:, 1]
else:
y_pred_proba = None
return y_pred, y_pred_proba
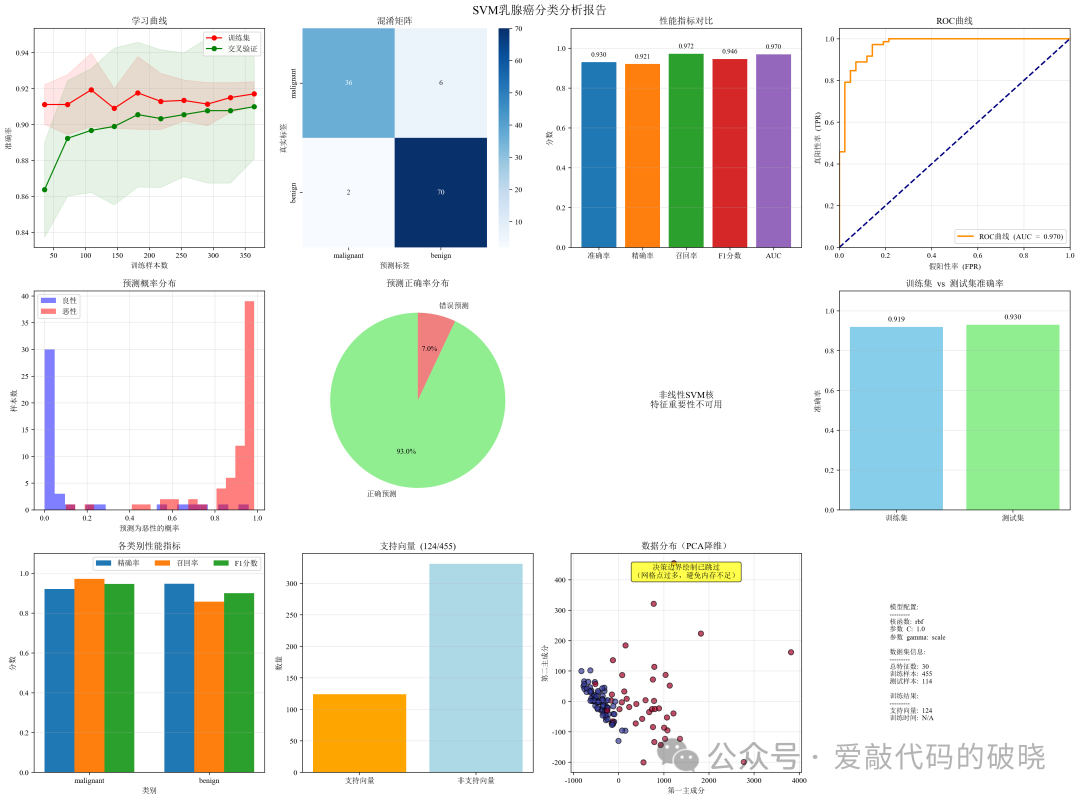
6.模型评估
def evaluate(self, y_pred, y_pred_proba):
"""评估预测结果"""
print("\n模型评估结果:")
print("=" * 50)
# 基本指标
accuracy = accuracy_score(self.y_test, y_pred)
precision = precision_score(self.y_test, y_pred)
recall = recall_score(self.y_test, y_pred)
f1 = f1_score(self.y_test, y_pred)
print(f"准确率 (Accuracy): {accuracy:.4f}")
print(f"精确率 (Precision): {precision:.4f}")
print(f"召回率 (Recall): {recall:.4f}")
print(f"F1分数 (F1-Score): {f1:.4f}")
# ROC-AUC(如果可计算概率)
if y_pred_proba is not None:
roc_auc = roc_auc_score(self.y_test, y_pred_proba)
print(f"ROC-AUC分数: {roc_auc:.4f}")
# 分类报告
print("\n详细分类报告:")
print(classification_report(self.y_test, y_pred,
target_names=self.metadata['target_names']))
return {
'accuracy': accuracy,
'precision': precision,
'recall': recall,
'f1': f1,
'roc_auc': roc_auc if y_pred_proba is not None else None
}
7.绘图
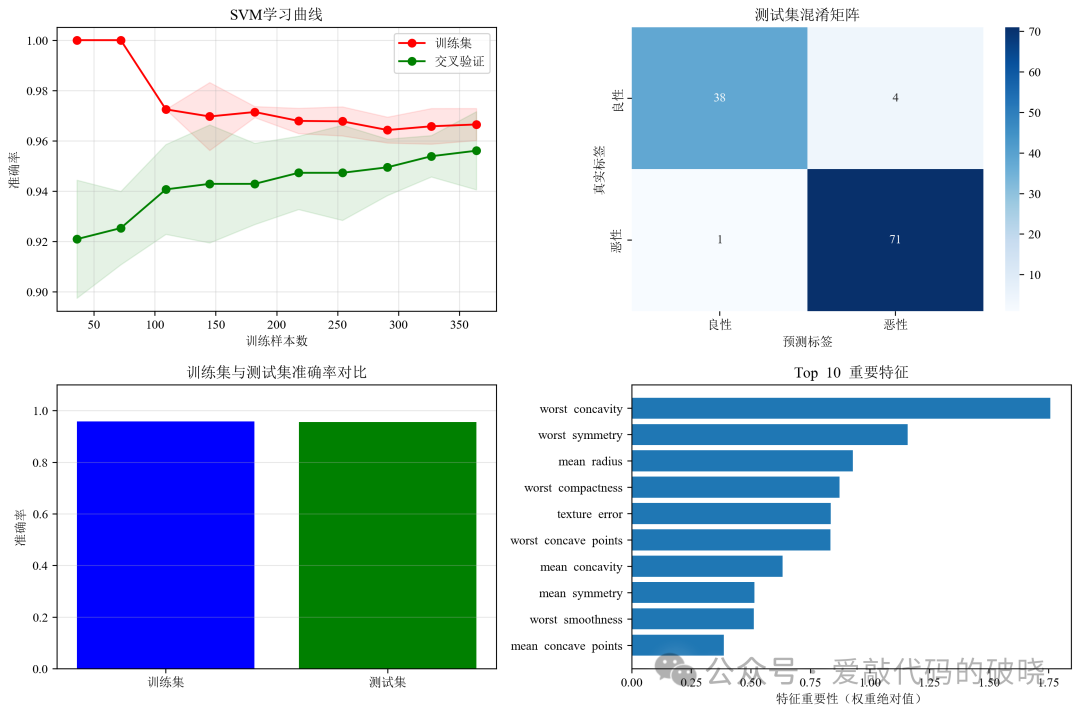
def plot_learning_curve(self):
"""绘制学习曲线"""
print("\n正在绘制学习曲线...")
# 修改这里:将 n_jobs=-1 改为 n_jobs=None 或 n_jobs=1
train_sizes, train_scores, test_scores = learning_curve(
self.model,
self.X_train,
self.y_train,
cv=5,
n_jobs=None, # 改为None,避免并行计算问题
train_sizes=np.linspace(0.1, 1.0, 10),
scoring='accuracy'
)
train_mean = np.mean(train_scores, axis=1)
train_std = np.std(train_scores, axis=1)
test_mean = np.mean(test_scores, axis=1)
test_std = np.std(test_scores, axis=1)
plt.figure(figsize=(12, 8))
# 学习曲线
plt.subplot(2, 2, 1)
plt.fill_between(train_sizes, train_mean - train_std,
train_mean + train_std, alpha=0.1, color="r")
plt.fill_between(train_sizes, test_mean - test_std,
test_mean + test_std, alpha=0.1, color="g")
plt.plot(train_sizes, train_mean, 'o-', color="r", label="训练集")
plt.plot(train_sizes, test_mean, 'o-', color="g", label="交叉验证")
plt.xlabel("训练样本数")
plt.ylabel("准确率")
plt.title("SVM学习曲线")
plt.legend(loc="best")
plt.grid(True, alpha=0.3)
# 混淆矩阵
plt.subplot(2, 2, 2)
y_pred = self.model.predict(self.X_test)
cm = confusion_matrix(self.y_test, y_pred)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',
xticklabels=['良性', '恶性'],
yticklabels=['良性', '恶性'])
plt.xlabel('预测标签')
plt.ylabel('真实标签')
plt.title('测试集混淆矩阵')
# 训练集和测试集准确率对比
plt.subplot(2, 2, 3)
y_train_pred = self.model.predict(self.X_train)
train_acc = accuracy_score(self.y_train, y_train_pred)
test_acc = accuracy_score(self.y_test, y_pred)
plt.bar(['训练集', '测试集'], [train_acc, test_acc], color=['blue', 'green'])
plt.ylim([0, 1.1])
plt.ylabel('准确率')
plt.title('训练集与测试集准确率对比')
plt.grid(True, alpha=0.3, axis='y')
# 特征重要性(使用SVM的权重,仅适用于线性核)
if SVM_CONFIG['kernel'] == 'linear':
plt.subplot(2, 2, 4)
feature_importance = np.abs(self.model.coef_[0])
top_features = np.argsort(feature_importance)[-10:]
feature_names = load_breast_cancer().feature_names
plt.barh(range(10), feature_importance[top_features])
plt.yticks(range(10), [feature_names[i] for i in top_features])
plt.xlabel('特征重要性(权重绝对值)')
plt.title('Top 10 重要特征')
else:
plt.subplot(2, 2, 4)
plt.text(0.5, 0.5, f"当前使用{SVM_CONFIG['kernel']}核\n特征重要性仅适用于线性核",
ha='center', va='center', fontsize=12)
plt.axis('off')
plt.tight_layout()
plt.savefig('svm_analysis.png', dpi=300, bbox_inches='tight')
plt.show()
return self
以下是绘制的图件
一下是控制台输出的结果:
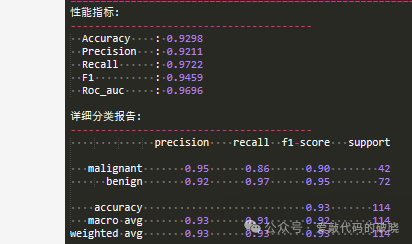

















 1742
1742

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









