



如需要数据及源码,关注微信公众号【爱敲代码的破晓】,后台私信【20260107】
一、LightGBM时间序列预测原理:
-
特征工程转换:将时间序列问题转化为监督学习问题,通过创建滞后特征(lag features)将时间依赖性转换为特征空间。
-
梯度提升框架:使用决策树集成方法,通过迭代训练多个弱学习器(决策树),每棵树学习前序模型的残差。
-
直方图算法:将连续特征离散化为直方图,大大减少内存使用和计算复杂度。
-
Leaf-wise生长策略:与传统的level-wise生长不同,选择具有最大增益的叶子节点进行分裂,提高精度但可能过拟合。
-
类别特征处理:可以直接处理类别特征,无需one-hot编码,特别适合包含星期、月份等类别特征的时间序列。
-
自动特征选择:通过特征分数(feature importance)自动识别最重要的时间滞后特征。
二、与其他时间序列算法的优势
-
计算效率高:
-
相比传统GBDT,训练速度提升10倍以上
-
内存使用减少70-90%
-
支持并行学习和大规模数据
-
-
处理复杂模式能力强:
-
能够捕捉非线性关系
-
自动处理特征交互
-
对异常值鲁棒
-
-
灵活性高:
-
支持自定义损失函数
-
可处理缺失值
-
内置正则化防止过拟合
-
-
与传统统计方法对比:
-
相比ARIMA,无需平稳性假设
-
相比Prophet,能更好地处理多个季节性
-
相比RNN/LSTM,训练更快,超参数更少
-
-
特征重要性分析:
-
提供特征重要性评分
-
可解释性比深度学习模型好
-
-
部署简便:
-
模型文件小
-
预测速度快
-
支持多种编程语言
-
三、使用示例
1.数据准备
2.导入第三方库
import pandas as pd
import numpy as np
import lightgbm as lgb
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
import joblib
import warnings
warnings.filterwarnings('ignore')
3.绘图设置
# 设置中文字体和样式
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
# sns.set_style("whitegrid")
4.构造LightGBM模型
class LightGBMTimeSeriesPredictor:
"""LightGBM时间序列预测器"""
def __init__(self, test_size=0.2, n_lags=5, random_state=42):
self.test_size = test_size
self.n_lags = n_lags
self.random_state = random_state
self.model = None
self.feature_cols = None
# LightGBM参数
self.params = {
'boosting_type': 'gbdt',
'objective': 'regression',
'metric': 'rmse',
'num_leaves': 31,
'learning_rate': 0.05,
'feature_fraction': 0.9,
'bagging_fraction': 0.8,
'bagging_freq': 5,
'verbose': -1,
'random_state': random_state
}
def load_data(self, file_path):
"""加载CSV数据"""
df = pd.read_csv(file_path)
df['Date'] = pd.to_datetime(df['Date'])
df.set_index('Date', inplace=True)
return df
def create_features(self, df, target_col='Open'):
"""创建时间序列特征"""
data = df.copy()
# 创建滞后特征
for lag in range(1, self.n_lags + 1):
data[f'lag_{lag}'] = data[target_col].shift(lag)
# 创建时间特征
data['day_of_week'] = data.index.dayofweek
data['day_of_month'] = data.index.day
data['month'] = data.index.month
data['quarter'] = data.index.quarter
data['year'] = data.index.year
# 创建滚动统计特征
data['rolling_mean_7'] = data[target_col].rolling(window=7).mean()
data['rolling_std_7'] = data[target_col].rolling(window=7).std()
# 删除包含NaN的行
data = data.dropna()
return data
def prepare_data(self, data, target_col='Open'):
"""准备训练数据"""
self.feature_cols = [col for col in data.columns if col != target_col]
X = data[self.feature_cols]
y = data[target_col]
# 按时间顺序划分训练集和测试集
split_idx = int(len(X) * (1 - self.test_size))
X_train, X_test = X.iloc[:split_idx], X.iloc[split_idx:]
y_train, y_test = y.iloc[:split_idx], y.iloc[split_idx:]
# 进一步划分训练集为训练和验证集
X_train, X_val, y_train, y_val = train_test_split(
X_train, y_train, test_size=0.2, random_state=self.random_state, shuffle=False
)
return X_train, X_val, X_test, y_train, y_val, y_test
def train(self, X_train, y_train, X_val, y_val):
"""训练模型"""
train_data = lgb.Dataset(X_train, label=y_train)
val_data = lgb.Dataset(X_val, label=y_val, reference=train_data)
self.model = lgb.train(
self.params,
train_data,
valid_sets=[train_data, val_data],
num_boost_round=1000,
callbacks=[
lgb.early_stopping(stopping_rounds=50),
lgb.log_evaluation(period=100)
]
)
return self.model
def predict(self, X):
"""进行预测"""
if self.model is None:
raise ValueError("模型未训练,请先调用train方法")
return self.model.predict(X)
def evaluate(self, y_true, y_pred):
"""评估预测结果"""
metrics = {
'RMSE': np.sqrt(mean_squared_error(y_true, y_pred)),
'MAE': mean_absolute_error(y_true, y_pred),
'R2': r2_score(y_true, y_pred),
'MAPE': np.mean(np.abs((y_true - y_pred) / y_true)) * 100
}
return metrics
def save_model(self, filepath):
"""保存模型"""
if self.model is None:
raise ValueError("模型未训练,无法保存")
joblib.dump(self.model, filepath)
def load_model(self, filepath):
"""加载模型"""
self.model = joblib.load(filepath)
return self.model
5.加载数据并构造特征
print("\n1. 加载数据...")
try:
df = predictor.load_data('data.csv')
print(f"数据加载成功,形状: {df.shape}")
print(f"数据时间范围: {df.index.min()} 到 {df.index.max()}")
except FileNotFoundError:
print("错误:未找到数据文件 'stock_data.csv'")
print("请确保数据文件在当前目录下")
return
# 2. 创建特征
print("\n2. 创建时间序列特征...")
data = predictor.create_features(df, target_col='Open')
print(f"特征创建完成,特征数量: {data.shape[1] - 1}")
# 3. 准备数据
print("\n3. 准备训练数据...")
X_train, X_val, X_test, y_train, y_val, y_test = predictor.prepare_data(data)
print(f"训练集大小: {len(X_train)}")
print(f"验证集大小: {len(X_val)}")
print(f"测试集大小: {len(X_test)}")
6.训练并保存模型
# 4. 训练模型
print("\n4. 训练LightGBM模型...")
model = predictor.train(X_train, y_train, X_val, y_val)
print("模型训练完成!")
# 5. 保存模型
predictor.save_model('lightgbm_model.pkl')
print("模型已保存为 'lightgbm_model.pkl'")
7.模型预测
# 6. 进行预测
print("\n5. 进行预测...")
y_train_pred = predictor.predict(X_train)
y_test_pred = predictor.predict(X_test)
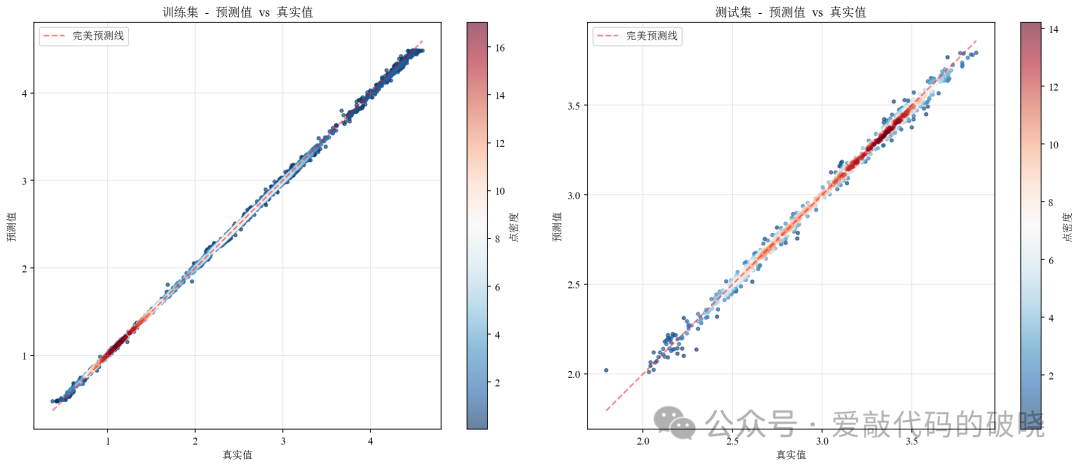
# 7. 评估结果
print("\n6. 评估预测结果...")
train_metrics = predictor.evaluate(y_train, y_train_pred)
test_metrics = predictor.evaluate(y_test, y_test_pred)
8.模型评估并绘图
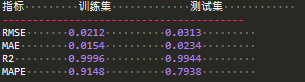
print("\n评估指标对比:")
print(f"{'指标':<10} {'训练集':<15} {'测试集':<15}")
print("-" * 40)
for metric in train_metrics:
print(f"{metric:<10} {train_metrics[metric]:<15.4f} {test_metrics[metric]:<15.4f}")
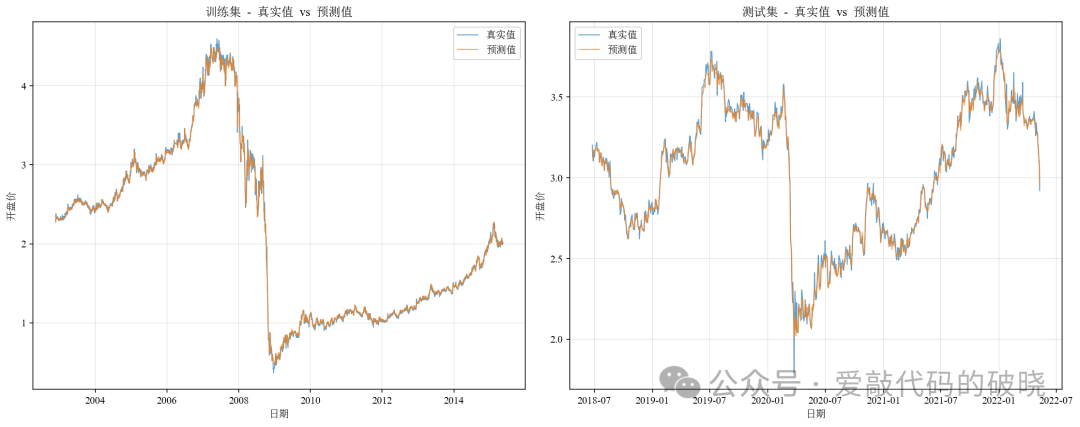
# 8. 绘制结果
print("\n7. 绘制结果图表...")
plot_results(y_train, y_train_pred, y_test, y_test_pred,
X_train.index, X_test.index)
# 9. 绘制特征重要性
if hasattr(model, 'feature_importance'):
feature_importance = pd.DataFrame({
'feature': predictor.feature_cols,
'importance': model.feature_importance()
})
feature_importance = feature_importance.sort_values('importance', ascending=False)
plt.figure(figsize=(10, 6))
plt.barh(feature_importance['feature'][:10], feature_importance['importance'][:10])
plt.xlabel('特征重要性')
plt.title('Top 10 特征重要性')
plt.gca().invert_yaxis()
plt.tight_layout()
plt.savefig('feature_importance_main.png', dpi=150, bbox_inches='tight')
plt.show()
print("\n" + "="*60)
print("LightGBM时间序列预测完成!")
print("="*60)
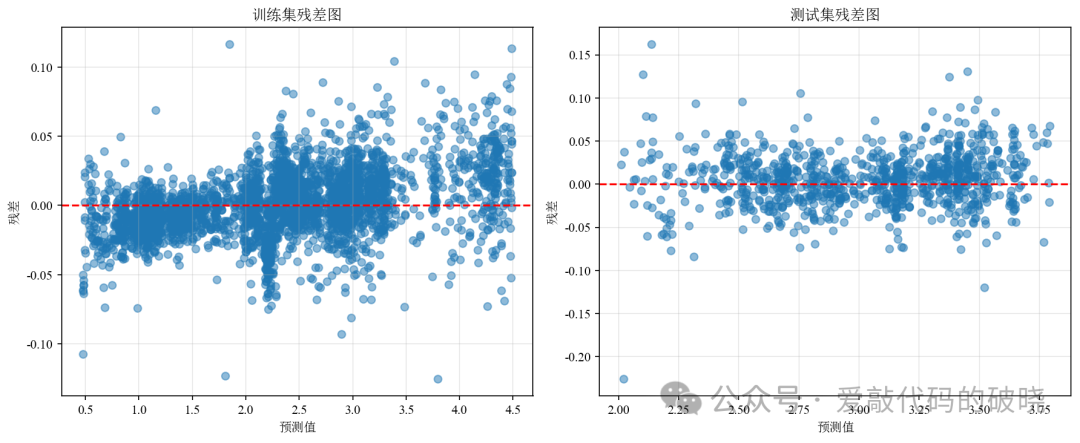
一下是相关图件

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









