




如需要数据及源码,关注微信公众号【爱敲代码的破晓】,后台私信【20260103】
在时间序列预测分析中,颜色渐变密度散点图是一种重要的可视化工具,用于评估预测模型的性能。以下从绘制原因、机器绘制原理和相对优势三个方面进行分点描述:
一、为什么需要绘制颜色渐变密度散点图?
-
直观展示预测值与真实值的整体关系:标准散点图虽能显示每个数据点的位置,但在数据量较大或点重叠严重时,难以识别密集区域。颜色渐变密度散点图通过颜色深浅反映点的分布密度,帮助快速识别预测值与真实值匹配程度高的区域。
-
揭示误差分布模式:时间序列预测中,误差可能呈现系统性偏差或异方差性(如误差随数值增大而增加)。密度散点图能通过颜色梯度展示误差的集中趋势,例如若高密度区域偏离对角线,表明模型存在系统性高估或低估。
-
区分训练集与测试集性能:通过将训练集和测试集数据以不同标记(如点与三角形)叠加在同一图中,颜色渐变能分别显示两者的密度分布,便于比较模型在训练和测试阶段的拟合一致性,评估过拟合或欠拟合问题。
-
增强视觉辨识度:使用渐变色彩(如中国传统色)替代单一颜色,不仅提升图表的审美价值,还通过色彩对比强化密度差异的感知,使学术图表更易于理解和传播。
二、机器绘制的原理简述
-
数据生成与准备:机器首先生成模拟或真实的预测值与真实值数据,通常包括训练集和测试集。数据被处理为二维数组(真实值数组和预测值数组),用于后续绘图。
-
密度计算:机器使用核密度估计(KDE)算法计算每个数据点在二维空间中的局部密度。该算法通过高斯核函数平滑数据,估计每个点周围的数据集中程度,输出归一化的密度值(范围0到1)。
-
颜色映射:根据预设或自定义的渐变色方案,机器将密度值映射到颜色梯度上。低密度区域对应浅色或起始色,高密度区域对应深色或结束色,实现颜色随密度渐变的效果。
-
可视化绘制:机器调用绘图库(如Matplotlib)创建散点图,其中每个点的颜色由其密度值决定。同时添加辅助元素:如对角线(表示完美预测线)、颜色条(解释密度与颜色关系)、图例(区分训练/测试集)和评估指标文本框(显示R²、RMSE等统计量)。
-
图形优化:自动调整坐标轴比例保持正方形(确保横纵刻度一致),添加网格线、标题和标签,最终输出高分辨率图像,适用于学术出版或报告。
三、相对于其他图表的优势
1.导入第三方库
import numpy as np
import matplotlib.pyplot as plt
from statistics import mean
from matplotlib.colors import LinearSegmentedColormap
from scipy.stats import gaussian_kde
from sklearn.metrics import r2_score, mean_squared_error, mean_absolute_error, mean_absolute_percentage_error
import warnings
warnings.filterwarnings('ignore')
2.自定义颜色
def _register_builtin_colormaps(self):
"""注册内置的20种顶级期刊常用渐变色"""
# 预定义的20种渐变色配置 (序号: [颜色列表], 名称)
self.preset_colormaps = {
1: (['#2E3192', '#f7f7f7', '#1BFFFF'], "蓝绿渐变"),
2: (['#FF512F', '#DD2476'], "火焰渐变"),
3: (['#DA22FF', '#9733EE'], "紫粉渐变"),
4: (['#00C9FF', '#92FE9D'], "青绿渐变"),
5: (['#FF5F6D', '#FFC371'], "珊瑚渐变"),
6: (['#654EA3', '#EAAFC8'], "紫红渐变"),
7: (['#2193B0', '#6DD5ED'], "海洋渐变"),
8: (['#CC2B5E', '#753A88'], "红酒渐变"),
9: (['#FF8008', '#FFC837'], "日落渐变"),
10: (['#1A2980', '#26D0CE'], "深海渐变"),
11: (['#FF512F', '#F09819'], "橙红渐变"),
12: (['#1D976C', '#93F9B9'], "森林渐变"),
13: (['#C33764', '#1D2671'], "暮色渐变"),
14: (['#3A1C71', '#D76D77', '#FFAF7B'], "三色日落"),
15: (['#0F2027', '#203A43', '#2C5364'], "夜空渐变"),
16: (['#834D9B', '#D04ED6'], "紫罗兰渐变"),
17: (['#11998E', '#38EF7D'], "翡翠渐变"),
18: (['#FF0099', '#493240'], "霓虹渐变"),
19: (['#FC466B', '#3F5EFB'], "粉蓝渐变"),
20: (['#00B4DB', '#0083B0'], "科技蓝渐变"),
21: (['#ff0000', '#ffffff', '#0000ff'], "红白蓝渐变"),
22: (['#fac03d', '#ffffff', '#007175'], "自定义渐变1"),
23: (['#84A729', '#ffffff', '#E7609E'], "自定义渐变2"),
24: (['#8076a3', '#ffffff', '#fbda41'], "自定义渐变3"),
}
# 注册所有预设颜色映射
for idx, (colors, name) in self.preset_colormaps.items():
self.register_colormap(idx, colors, name)
内置了20种渐变色供选择
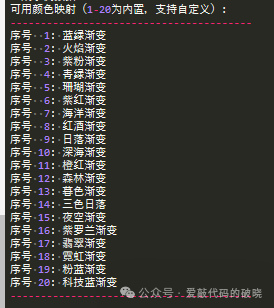
当然你也可以在代码中自定义颜色
3.数据准备
此处为随机生成的数据
# 使用示例
def generate_sample_data(n_samples=1000, train_ratio=0.7, noise_level=0.1):
"""生成示例数据"""
np.random.seed(42)
# 生成真实值
x = np.linspace(0, 10, n_samples)
y_true = np.sin(x) + 0.5 * np.cos(2*x) + 0.3 * np.random.randn(n_samples)
# 生成带噪声的预测值(模拟预测效果)
y_pred = y_true + noise_level * np.random.randn(n_samples)
# 添加一些系统性偏差
y_pred = 0.95 * y_pred + 0.05 * np.mean(y_pred)
# 创建训练/测试集掩码
train_mask = np.zeros(n_samples, dtype=bool)
train_indices = np.random.choice(n_samples, size=int(n_samples * train_ratio), replace=False)
train_mask[train_indices] = True
return y_true, y_pred, train_mask
4.计算模型参数
def calculate_metrics(self, y_true, y_pred):
"""计算模型评估指标"""
metrics = {}
# R² 决定系数
metrics['R2'] = r2_score(y_true, y_pred)
# RMSE 均方根误差
metrics['RMSE'] = np.sqrt(mean_squared_error(y_true, y_pred))
# MAE 平均绝对误差
metrics['MAE'] = mean_absolute_error(y_true, y_pred)
# MAPE 平均绝对百分比误差
metrics['MAPE'] = mean_absolute_percentage_error(y_true, y_pred) * 100
# MSE 均方误差
metrics['MSE'] = mean_squared_error(y_true, y_pred)
# 偏差 (Bias)
metrics['Bias'] = np.mean(y_pred - y_true)
# NSE (Nash-Sutcliffe效率系数)
y_mean = np.mean(y_true)
ss_res = np.sum((y_true - y_pred) ** 2)
ss_tot = np.sum((y_true - y_mean) ** 2)
metrics['NSE'] = 1 - (ss_res / (ss_tot + 1e-8))
# KGE (Kling-Gupta效率系数)
r = np.corrcoef(y_true, y_pred)[0, 1]
alpha = np.std(y_pred) / (np.std(y_true) + 1e-8)
beta = np.mean(y_pred) / (np.mean(y_true) + 1e-8)
metrics['KGE'] = 1 - np.sqrt((r - 1)**2 + (alpha - 1)**2 + (beta - 1)**2)
return metrics
5.绘制单个颜色渐变密度散点图
print("\n使用内置颜色映射绘制...")
fig1, ax1 = plotter.plot_density_scatter(
y_true, y_pred,
train_mask=train_mask,
colormap_idx=1, # 使用蓝绿渐变
title='Time Series Prediction Results (Colormap #1)',
how_metrics=True,
metrics_pos='upper left'
)
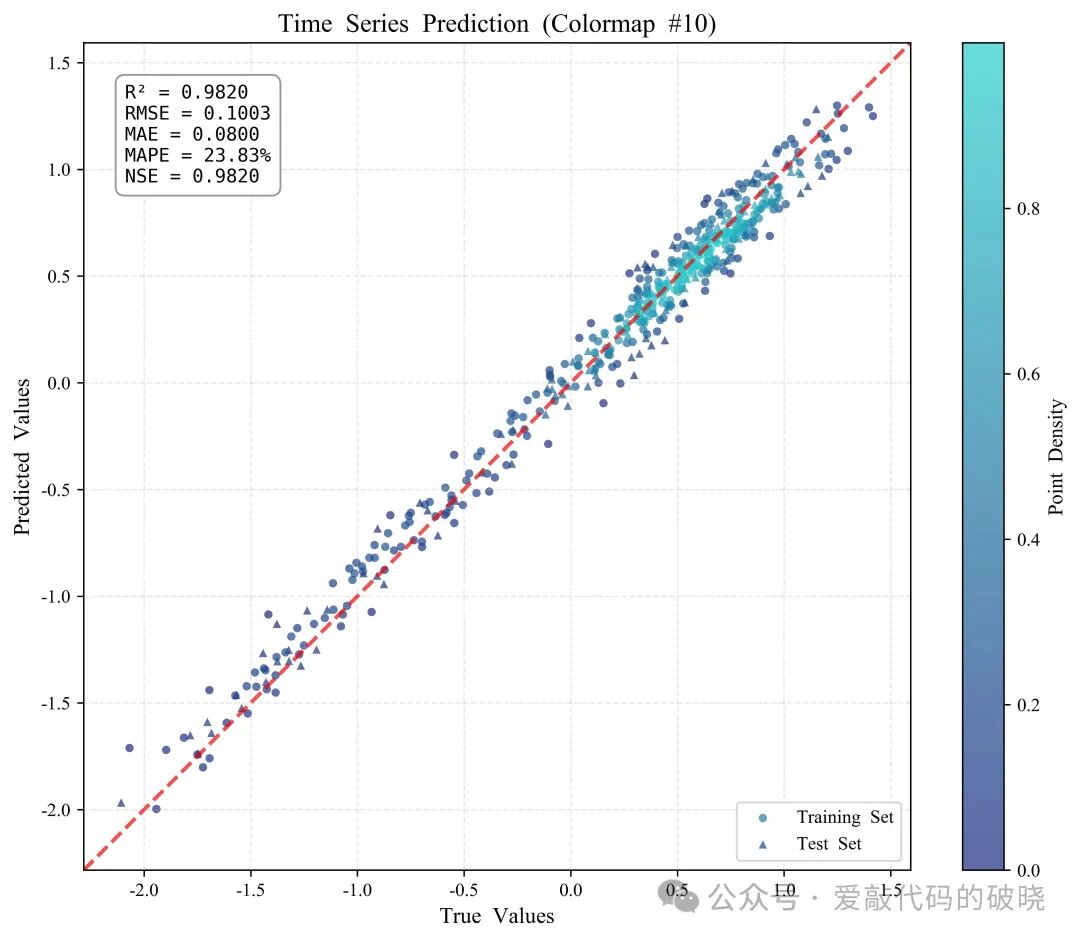
6.绘制多个密度散点图
# # 6. 绘制多个颜色映射对比图
print("绘制颜色映射对比图...")
fig3, axes = plotter.plot_comparison(y_true, y_pred, train_mask, show_metrics=True, metrics_pos='upper left')
fig3.suptitle('Comparison of Different Colormaps', fontsize=16, fontweight='bold')
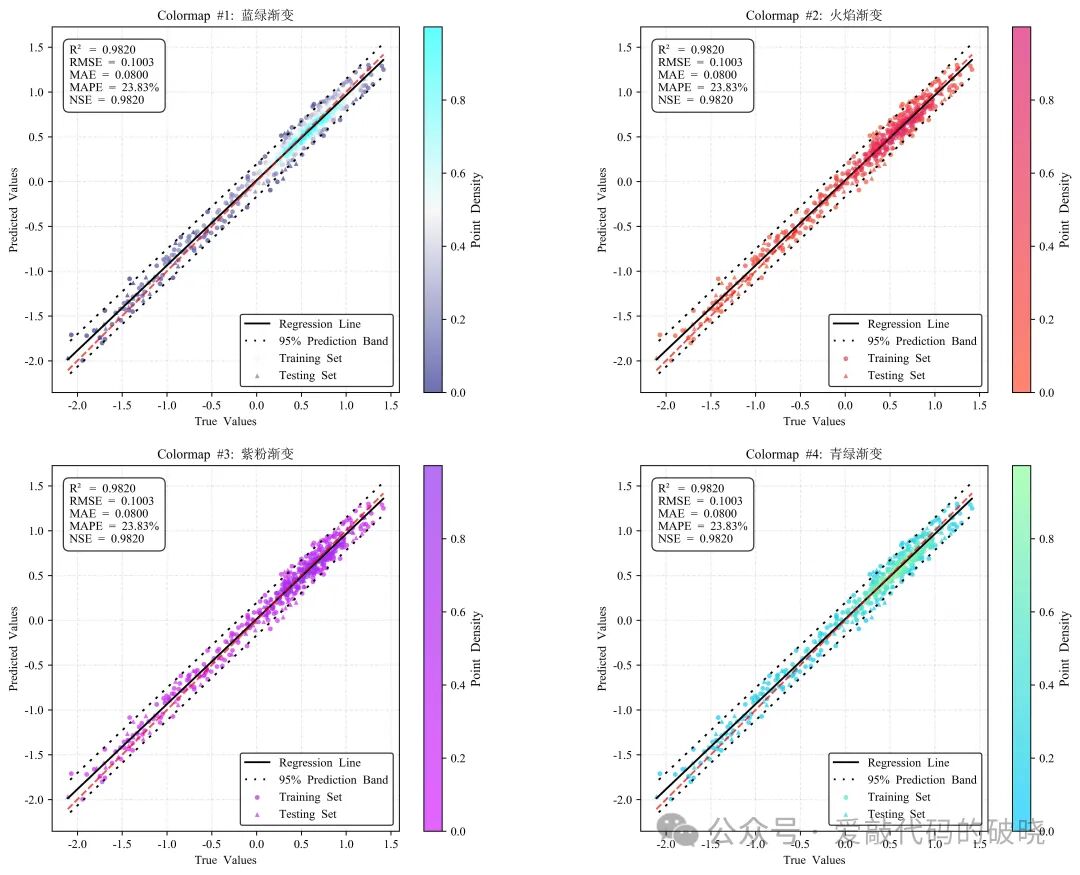
更多配色显示
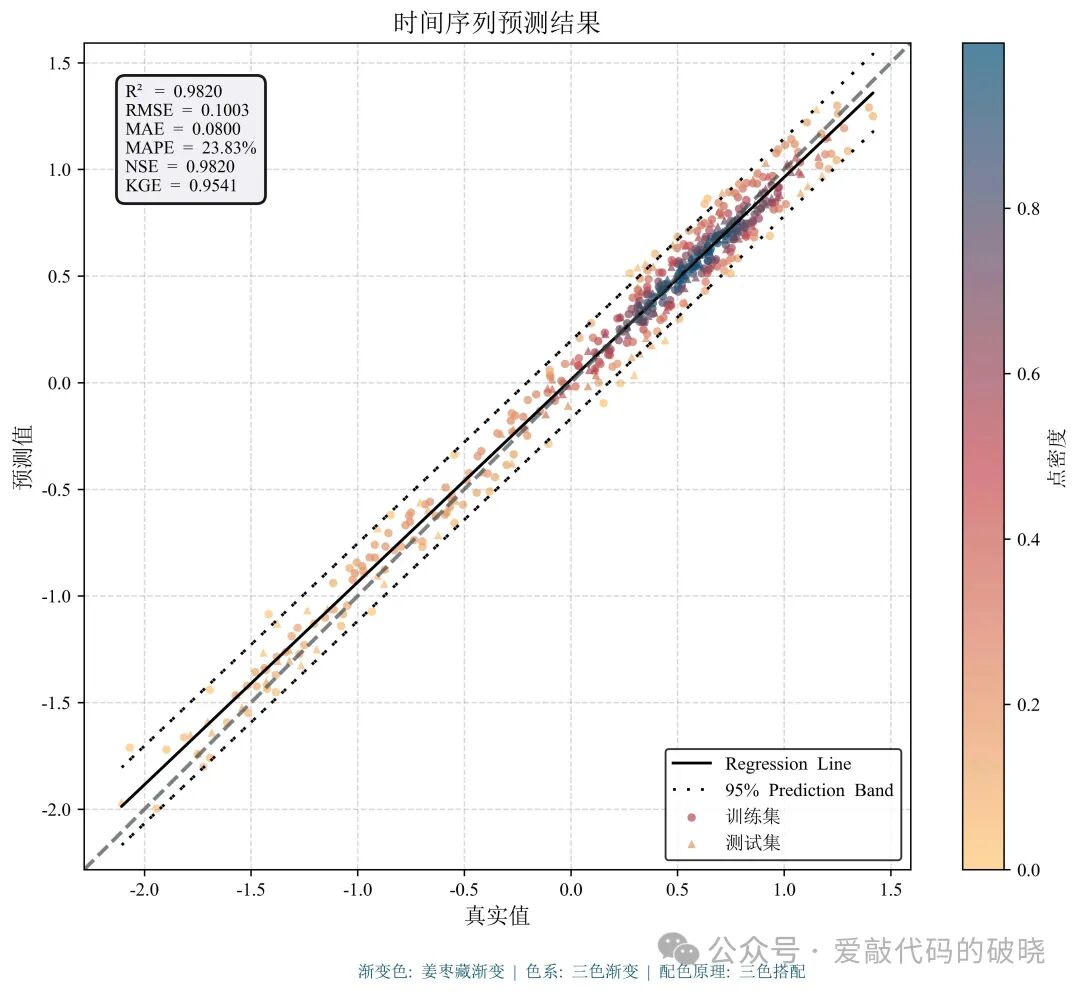
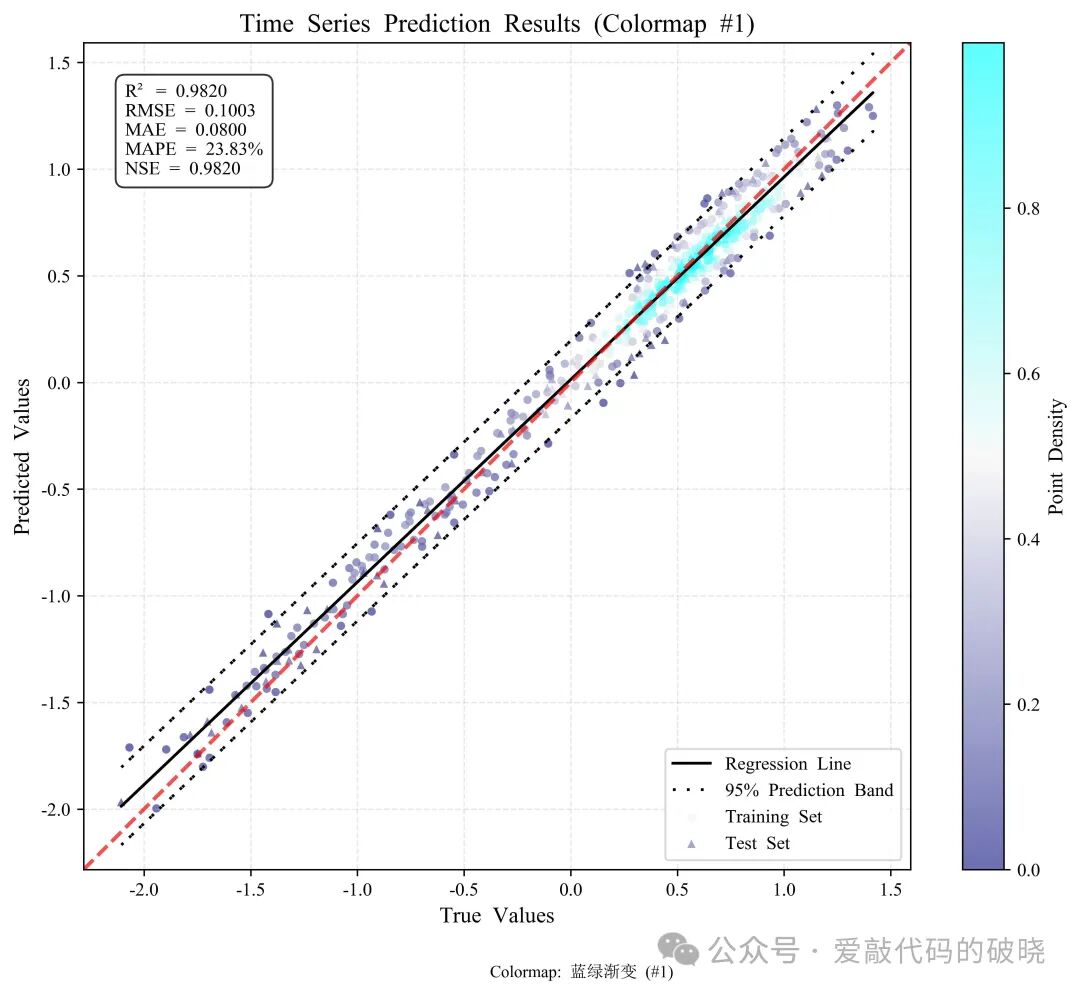
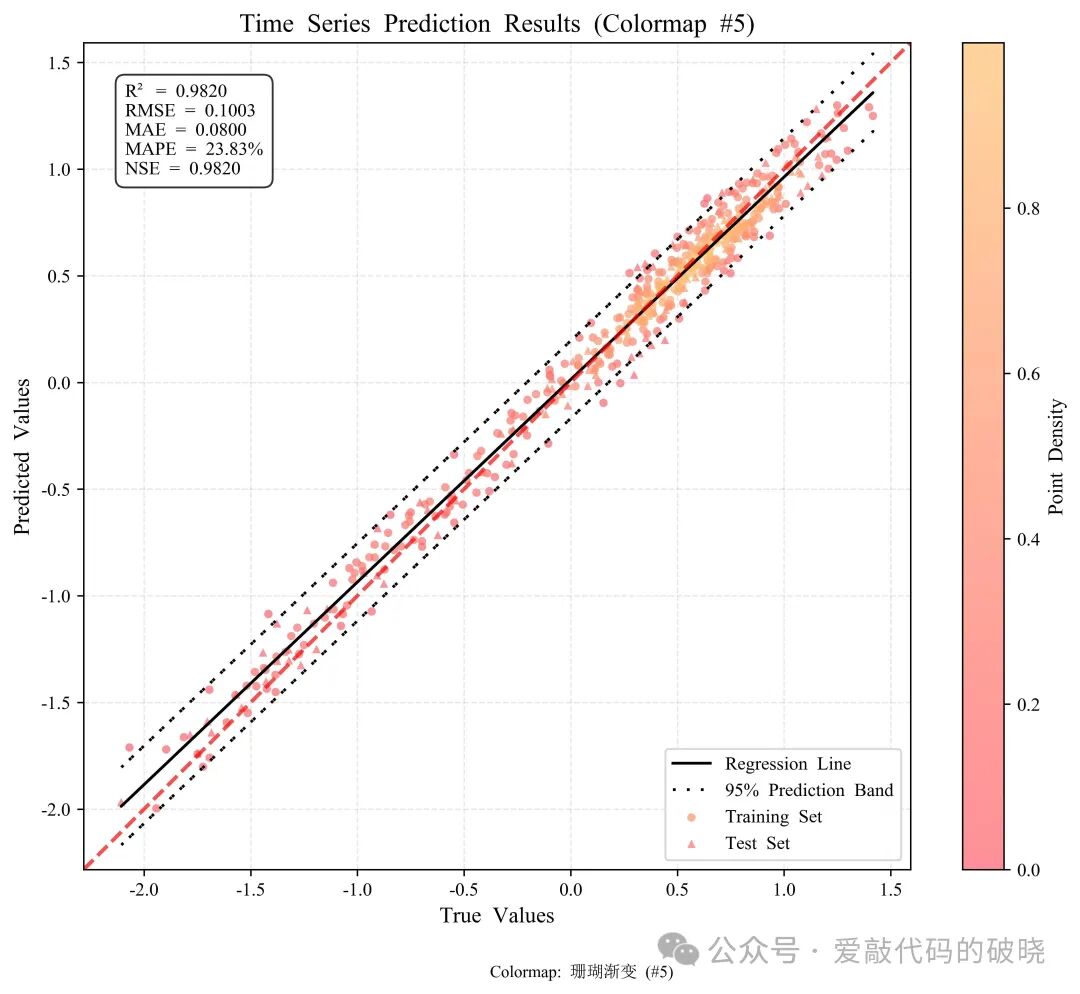
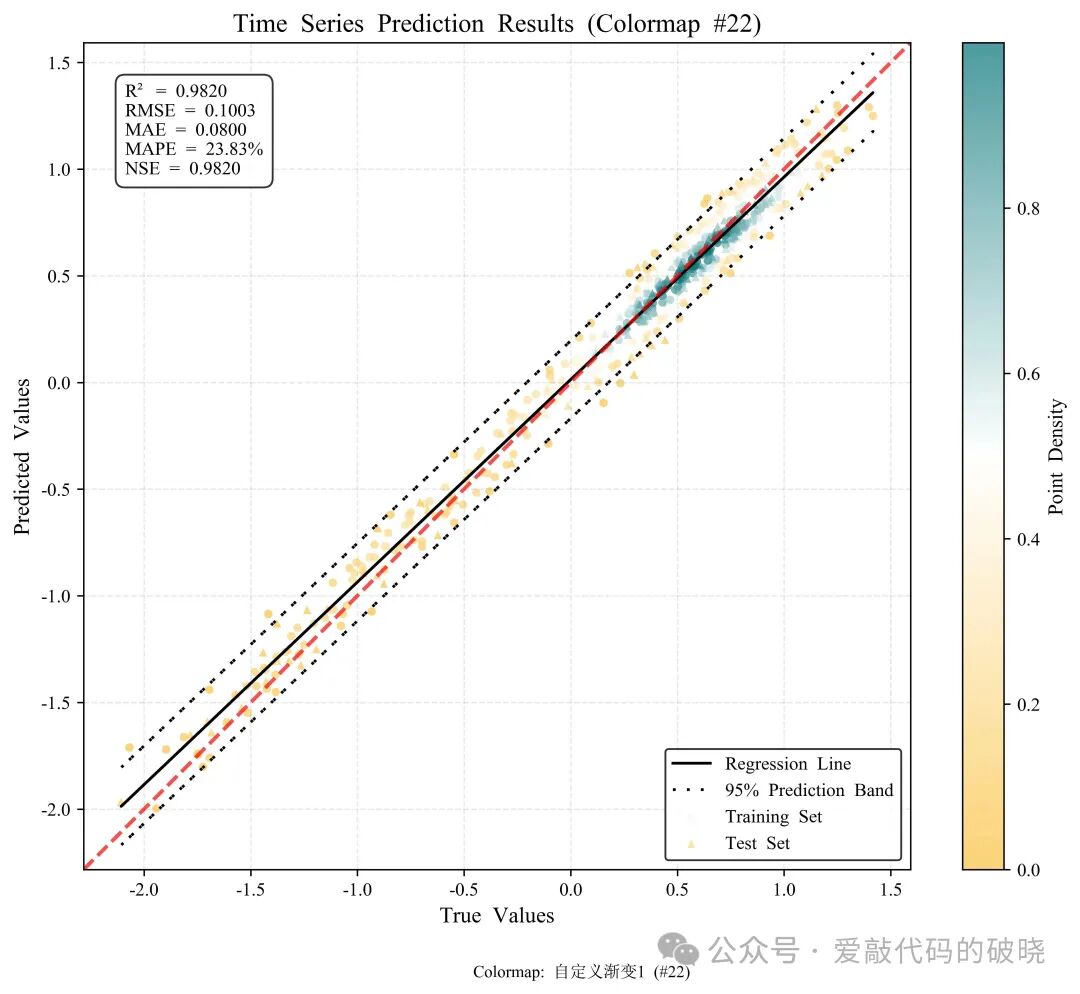
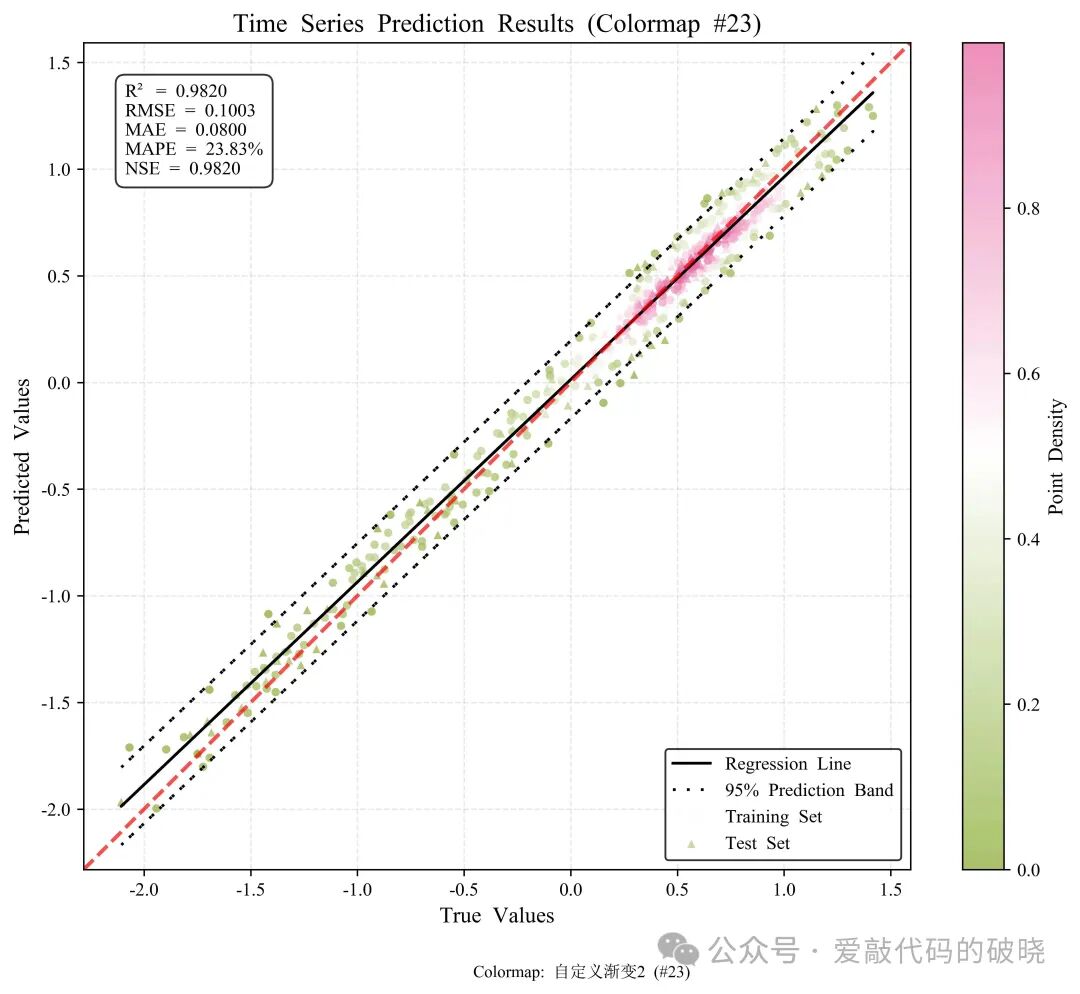
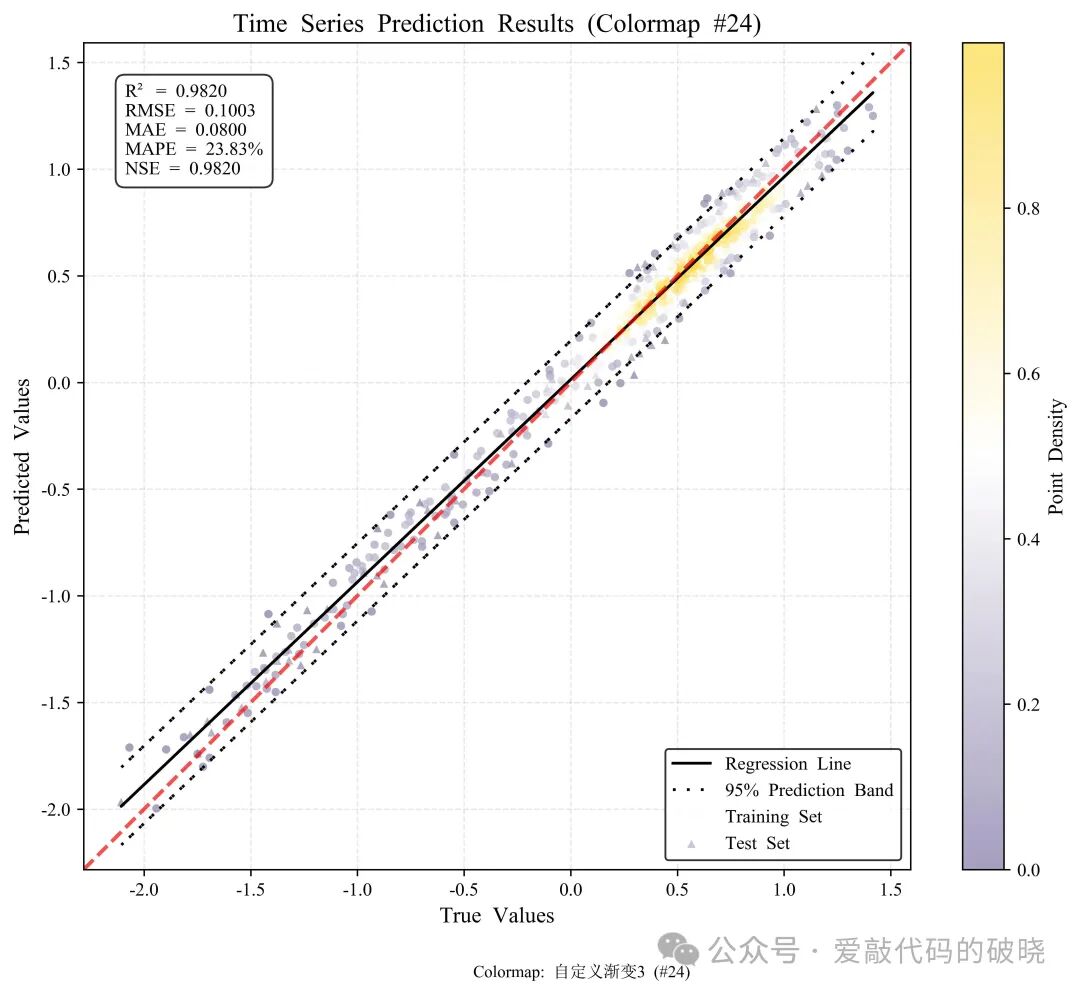
四、优势及总结
-
解决过度绘制问题:相较于传统散点图,当数据点成千上万时,点重叠会掩盖真实分布。密度散点图用颜色梯度揭示重叠区域的密度,避免信息丢失,尤其适合大规模时间序列数据。
-
更全面的分布洞察:折线图仅显示时间维度上的预测值与真实值曲线,难以捕捉整体偏差;残差图主要关注误差分布,但忽略了原始值关系。密度散点图结合了散点图和密度图的优点,同时展示点位置和集中趋势,全面反映预测性能。
-
增强对比和可读性:与单一颜色的散点图相比,渐变色彩提供视觉层次,使高密度区域(如预测准确区)和低密度区域(如异常点)一目了然。配色方案(如中国传统色)可提升专业性和文化契合度,适合多样化应用场景。
-
集成多维度信息:该图可同时容纳训练集、测试集数据,并嵌入关键评估指标(如R²、MAE),在一个视图中提供模型评估所需的多维度信息,减少读者跨图表对照的认知负担。
-
适应性强且易于定制:通过调整渐变色方案、透明度、点大小等参数,可适应不同数据类型和展示需求(如学术论文、商业报告)。支持随机生成渐变色或自定义颜色,灵活性高。
总之,颜色渐变密度散点图在时间序列预测分析中,通过融合密度估计和色彩可视化,提供了直观、丰富且美观的评估手段,是提升模型解释性和结果呈现质量的有效工具。

















 713
713

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









