




文章较长,示例代码在第三个部分,如需要数据及源码,关注微信公众号【爱敲代码的破晓】,后台私信【20251220】
XGBoost(eXtreme Gradient Boosting)是一种基于梯度提升框架的机器学习算法,它通过集成多个弱学习器(通常是决策树)来构建一个强学习器。XGBoost在传统梯度提升决策树(GBDT)的基础上进行了优化,加入了正则化项、二阶导数信息、特征分位点划分等技术,从而在效率和准确性上都有显著提升。
一、XGBoost算法原理
算法基本思想
XGBoost本质上是一种梯度提升决策树算法,它通过集成多个相对简单的决策树模型来构建一个强大的预测模型。这种方法基于“三个臭皮匠,顶个诸葛亮”的理念,将许多表现平平的弱学习器组合成一个极其准确的强学习器。
逐树构建的过程
XGBoost采用逐步添加树的方式构建模型。每一棵新树都不是凭空创建的,而是专门针对之前所有树组合起来产生的预测误差进行训练。想象一下这样的场景:第一次预测后,模型发现自己的预测与真实值有差距,于是训练第二棵树专门去预测这些差距;第二次预测后,又产生了新的误差,于是第三棵树被训练来预测这些新的误差。这个过程持续进行,每棵树都专注于修正前面所有树累积的预测错误。
梯度指导的优化
"梯度提升"中的"梯度"指的是数学中的梯度概念。XGBoost不仅使用一阶梯度信息(类似于损失函数的斜率,告诉我们预测偏差的方向和大小),还创新性地使用了二阶梯度信息(类似于损失函数的曲率,告诉我们误差变化的速率)。这就像是开车时不仅知道方向错了,还知道错得有多严重、偏差在以多快的速度增加。这种双重信息使得XGBoost能够更精准地确定每棵树应该如何生长,以达到最优的误差修正效果。
正则化的智慧
XGBoost一个关键创新是引入了复杂的正则化机制。传统的决策树容易过度生长,过度拟合训练数据中的噪声。XGBoost通过多种方式限制树的复杂程度:惩罚树的深度、限制叶子节点的数量、约束叶子节点的权重值。这相当于给模型戴上了"紧箍咒",既允许它学习数据中的真实模式,又防止它过分关注数据中的随机波动。
并行处理的巧妙设计
虽然决策树算法本质上是顺序的(后一棵树依赖于前一棵树的预测结果),但XGBoost通过创新的并行化策略大大提高了效率。它在寻找最佳特征分割点时并行处理不同特征,在构建每棵树的层次结构时并行处理不同分支。这种设计使得XGBoost在处理大规模数据集时比传统梯度提升算法快得多。
二、时间序列预测中的方法对比
1. 传统统计方法
- ARIMA/SARIMA:基于线性假设,适用于平稳时间序列。需要手动进行差分和参数选择,对非线性关系捕捉能力弱。
- 指数平滑:适用于具有趋势和季节性的序列,但同样是线性模型,无法捕捉复杂非线性模式。
2. 机器学习方法
- 支持向量回归(SVR):通过核函数可以处理非线性关系,但核函数和参数的选择对性能影响大,且训练速度较慢,不适合大规模数据。
- 随机森林:可以捕捉非线性关系,但缺乏对时间序列顺序性的专门考虑,可能无法充分利用时间依赖关系。
3. 深度学习方法
- 循环神经网络(RNN/LSTM):专门为序列数据设计,能够捕捉长期依赖关系。但需要大量的数据和计算资源,训练时间较长,且容易过拟合。
- 卷积神经网络(CNN):可以通过卷积层捕捉局部模式,但在时间序列预测中通常需要结合其他结构(如因果卷积)来保证时间顺序。
4. XGBoost在时间序列预测中的优势
- 非线性关系捕捉:XGBoost能够自动学习特征之间的非线性关系,不需要事先假设数据分布。
- 特征重要性:XGBoost可以提供特征重要性排序,帮助理解哪些滞后特征对预测最重要。
- 处理缺失值:XGBoost内置缺失值处理机制,不需要额外预处理。
- 正则化:通过正则化项控制模型复杂度,减少过拟合风险。
- 效率高:与深度学习方法相比,XGBoost训练速度更快,资源消耗更少,尤其适合中小规模数据。
5. XGBoost在时间序列预测中的局限性
- 顺序依赖:虽然可以通过创建滞后特征来引入时间依赖,但模型本身没有显式的时间顺序概念,可能无法像RNN那样自然捕捉长期依赖。
- 固定窗口:需要手动选择滞后窗口大小,窗口过大或过小都可能影响性能。
- 非自回归:在预测多步时,通常需要使用滚动预测(递归预测)或直接多步预测策略,这可能会累积误差。
三、xgboost的应用实例
1.先导入第三方库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
import xgboost as xgb
import joblib
from datetime import datetime
import warnings
warnings.filterwarnings('ignore')
2.中文设置,防止汇入出错:
# 设置中文显示(如果系统支持)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
3.加载数据并划分训练集、测试集
def load_and_prepare_data(file_path, n_lags=10):
"""
加载数据并创建时间序列特征
"""
# 读取CSV文件
df = pd.read_csv(file_path)
# 转换日期列
df['Date'] = pd.to_datetime(df['Date'])
df.set_index('Date', inplace=True)
# 使用Open列
data = df[['Open']].copy()
# 创建滞后特征
for i in range(1, n_lags + 1):
data[f'lag_{i}'] = data['Open'].shift(i)
# 创建时间特征
data['day_of_week'] = data.index.dayofweek
data['day_of_month'] = data.index.day
data['month'] = data.index.month
data['quarter'] = data.index.quarter
# 移除NaN值
data.dropna(inplace=True)
return data
def split_time_series(data, test_size=0.2):
"""
按时间顺序划分训练集和测试集
"""
split_idx = int(len(data) * (1 - test_size))
# 划分特征和目标
X = data.drop('Open', axis=1)
y = data['Open']
# 按时间顺序划分
X_train, X_test = X[:split_idx], X[split_idx:]
y_train, y_test = y[:split_idx], y[split_idx:]
return X_train, X_test, y_train, y_test
4.训练模型
def train_xgboost_model(X_train, y_train, X_test, y_test):
"""
训练XGBoost模型
"""
# 定义XGBoost模型参数
params = {
'n_estimators': 500,
'max_depth': 6,
'learning_rate': 0.01,
'subsample': 0.8,
'colsample_bytree': 0.8,
'random_state': 42,
'n_jobs': -1
}
# 创建并训练模型
model = xgb.XGBRegressor(**params)
print("开始训练模型...")
model.fit(
X_train, y_train,
eval_set=[(X_test, y_test)],
early_stopping_rounds=50,
verbose=False
)
return model
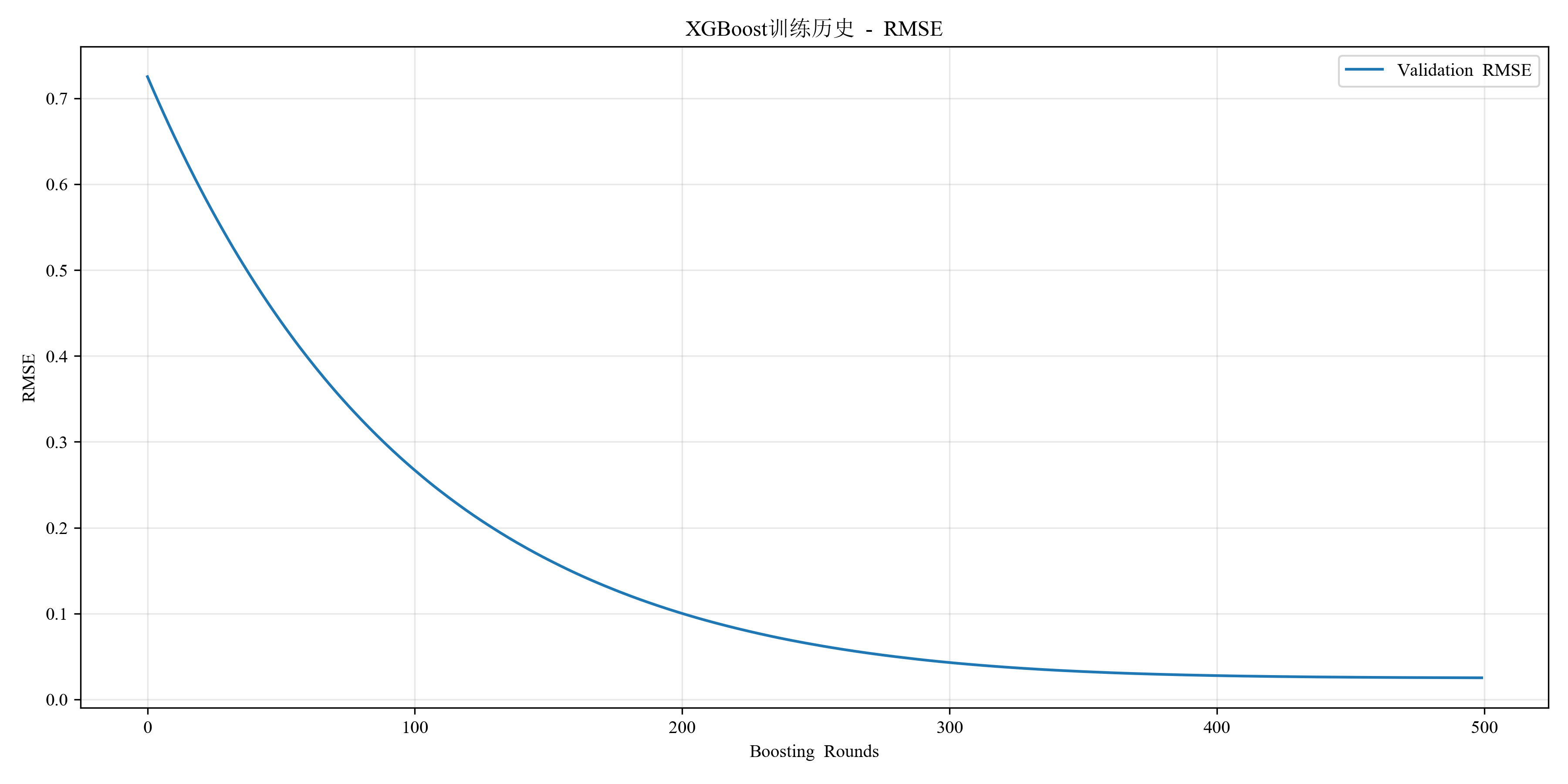
5.记录训练过程:
def plot_training_history(model):
"""
绘制训练历史
"""
results = model.evals_result()
plt.figure(figsize=(12, 6))
plt.plot(results['validation_0']['rmse'], label='Validation RMSE')
plt.xlabel('Boosting Rounds')
plt.ylabel('RMSE')
plt.title('XGBoost训练历史 - RMSE')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('training_history.png', dpi=300)
plt.show()
6.保存训练好的模型
def save_model_and_info(model, X_train, y_train, feature_names):
"""
保存模型和相关信息
"""
# 保存模型
joblib.dump(model, 'xgboost_time_series_model.pkl')
# 保存特征名称
feature_info = {
'feature_names': feature_names.tolist(),
'train_size': len(X_train),
'training_date': datetime.now().strftime('%Y-%m-%d %H:%M:%S')
}
joblib.dump(feature_info, 'model_info.pkl')
print(f"模型已保存为 'xgboost_time_series_model.pkl'")
print(f"模型信息已保存为 'model_info.pkl'")
7.加载模型,并对测试集预测并绘制图件
def main():
# 参数设置
FILE_PATH = 'AAC.AX.csv' # 替换为您的CSV文件路径
MODEL_PATH = 'xgboost_time_series_model.pkl'
INFO_PATH = 'model_info.pkl'
try:
# 1. 加载模型和模型信息
print("步骤1: 加载模型和模型信息...")
model = joblib.load(MODEL_PATH)
model_info = joblib.load(INFO_PATH)
print(f"模型训练日期: {model_info['training_date']}")
print(f"训练集大小: {model_info['train_size']}")
# 2. 准备数据
print("\n步骤2: 准备预测数据...")
feature_names = pd.Index(model_info['feature_names'])
n_lags = len([f for f in feature_names if f.startswith('lag_')])
X, y, original_data, dates = load_and_prepare_new_data(
FILE_PATH, feature_names, n_lags
)
print(f"预测数据形状: {X.shape}")
# 3. 进行预测
print("\n步骤3: 进行预测...")
y_pred = model.predict(X)
# 4. 评估预测结果
print("\n步骤4: 评估预测结果...")
metrics = evaluate_predictions(y, y_pred)
# 5. 绘制图形
print("\n步骤5: 绘制结果图形...")
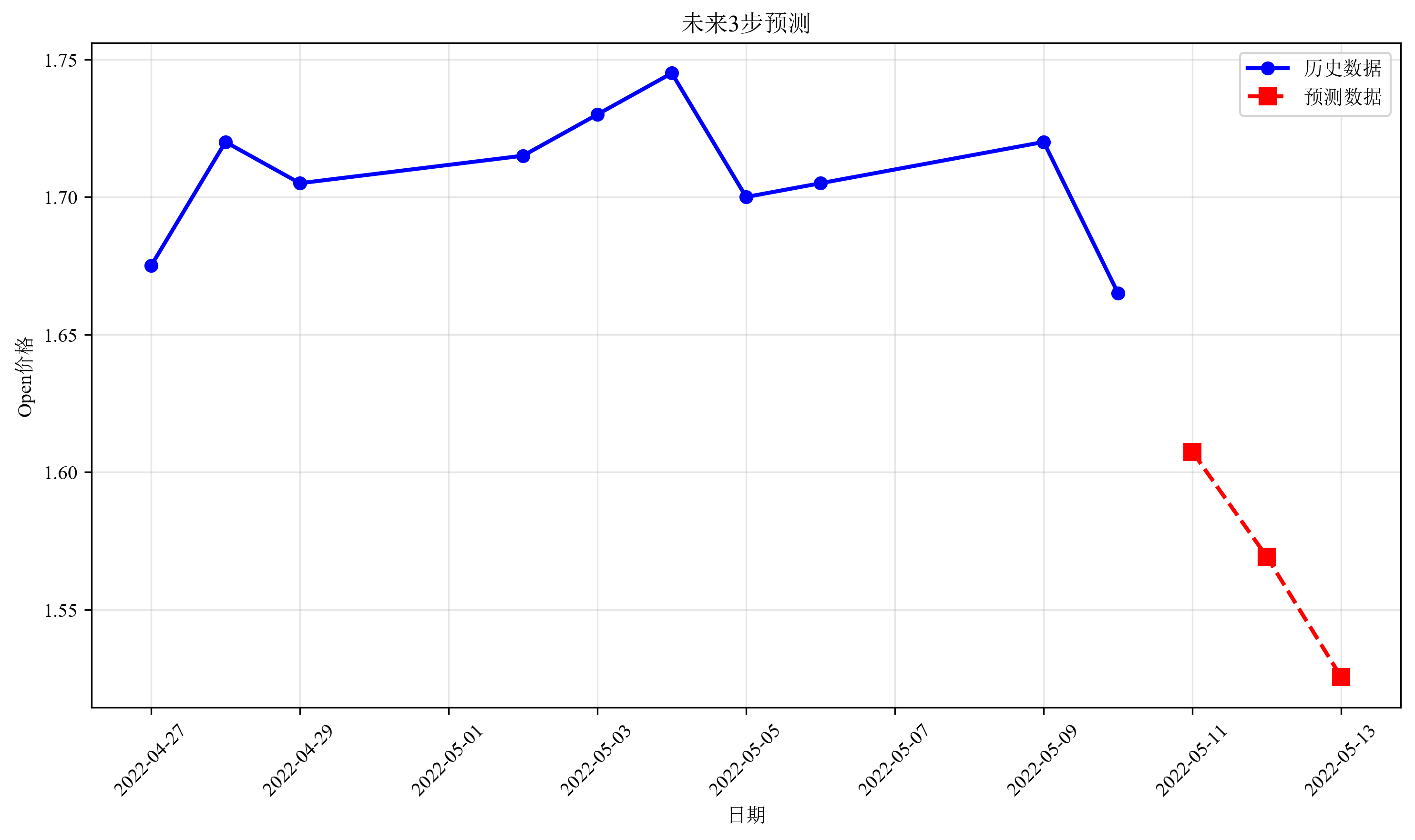
# 5.1 预测对比图
plot_predictions(y.values, y_pred, dates, "时间序列预测结果")
# 5.2 特征重要性
plot_feature_importance(model, X.columns)
# 5.3 预测区间(可选)
if len(y) > 100: # 仅在数据量足够时绘制
try:
plot_prediction_intervals(model, X, y)
except:
print("注意: 预测区间绘制失败,跳过此步骤")
# 6. 保存预测结果
print("\n步骤6: 保存预测结果...")
results_df = pd.DataFrame({
'Date': dates,
'Actual_Open': y.values,
'Predicted_Open': y_pred,
'Residual': y.values - y_pred
})
results_df.to_csv('prediction_results.csv', index=False)
print("预测结果已保存为 'prediction_results.csv'")
# 7. 打印预测统计
print("\n预测统计:")
print("=" * 50)
print(f"平均预测值: {np.mean(y_pred):.4f}")
print(f"预测标准差: {np.std(y_pred):.4f}")
print(f"最大预测误差: {np.max(np.abs(y.values - y_pred)):.4f}")
print(f"预测准确率(在±1%范围内): "
f"{np.mean(np.abs(y.values - y_pred) / y.values < 0.01) * 100:.2f}%")
except FileNotFoundError as e:
print(f"错误: 找不到文件 - {e}")
print("请先运行 train.py 训练模型")
except Exception as e:
print(f"错误: {e}")
if __name__ == "__main__":
main()
结论
XGBoost是一种强大且灵活的机器学习算法,在时间序列预测中,通过适当的特征工程(如滞后特征、时间特征)可以取得很好的效果。与传统统计方法相比,它能更好地捕捉非线性关系;与深度学习方法相比,它更易于训练和调参,且对数据量要求相对较低。然而,对于具有复杂长期依赖的时间序列,可能需要更专门的序列模型(如LSTM)来获得更好的性能。在实际应用中,可以尝试多种方法,并根据具体问题和数据选择最合适的模型。
如需要数据及源码,关注微信公众号【爱敲代码的破晓】,后台私信【20251220】

















 373
373

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









