 通道注意力与特征图分析
通道注意力与特征图分析





- 不同CNN层的特征图:不同通道的特征图
- 什么是注意力:注意力家族,类似于动物园,都是不同的模块,好不好试了才知道。
- 通道注意力:模型的定义和插入的位置
- 通道注意力后的特征图和热力图
作业:今日代码较多,理解逻辑即可
注意力机制
核心思想:聚焦重点,关注需要的信息的特征提取器。就像人类视觉会自动忽略背景,聚焦于图片中的主体(如猫、汽车)。
核心计算过程
注意力机制包含三个核心组件:查询(query:需要的信息)、键(key:输入序列中每个元素可供检索的“标签”或“标识”)、值(value:输入序列中每个元素实际的“内容”或“信息”)。
- 计算注意力分数:衡量Query和每个Key的相似度
- 归一化权重:使用Softmax函数将分数转换为概率分布:Attention Weights = Softmax(Score)
- 加权求和:将Value与权重进行加权求和,Output
= Σ(Attention Weights*Value)
注意:和卷积一样,注意力机制也是对输入特征进行加权求和。但是卷积是固定权重的特征提取,而注意力机制是动态权重的特征提取(权重与输入数据有关)。
主要类型
注意力机制这个大类别里(动物园),存在不同的注意力方法(不同动物,不存在包含关系)。比如自注意力(self-attention)是自己学习自己,是transformer(大模型)架构的核心。
- 多种注意力模块:不同场景下的关键信息分布不同,有时关注通道,有时关注空间等
- ‘万能’注意力模块:存在效率和灵活性限制。专用模块针对特定需求优化计算,成本更低;不同任务的核心需求差异大(如医学图像侧重空间定位,自然语言处理侧重语义长距离依赖),通用模块可能冗余或低效。
注意力机制(Attention Mechanism)
│
├── 编码器-解码器注意力(Bahdanau, Luong) → 用于 RNN Seq2Seq
│
├── 自注意力(Self-Attention) → Transformer 核心
│ └── 衍生:Multi-head, Axial, Windowed, etc.
│
└── CNN 注意力模块(与 Self-Attention 并行发展)
├── 通道注意力(SE Block, ECANet)
├── 空间注意力(SAM in CBAM)
└── 混合注意力(CBAM = Channel + Spatial)| 注意力类型 | 核心关注点 | 计算关系 |
|---|---|---|
| 自注意力 (Self-Attention) | 序列内部元素间的依赖关系 | 一个序列内部,元素与所有其他元素的关系 |
| 通道注意力 (Channel Attention) | 特征通道的重要性 | 同一特征图内部,不同通道之间的重要性权重 |
| 空间注意力 (Spatial Attention) | 空间位置的重要性 | 同一特征图内部,不同空间坐标(H, W) 的重要性权重 |
| 多头注意力 (Muti-Head Attention) | 不同子空间的联合信息 | 将输入投影到多个子空间,并行计算多个自/交叉注意力 |
| 编码-解码器注意力 (Encoder-Decoder Attention) | 两个序列间元素的关联关系 | Query来自序列A(解码器),Key/Value来自序列B(编码器) |
特征图可视化
特征图本质就是不同的卷积核的输出。浅层指的是离输入图近的卷积层,它的特征图通常较大。而深层特征图会经过多次下采样,尺寸显著缩小,尺寸差异过大时,小尺寸特征图在视觉上会显得模糊或丢失细节。
实现特征图可视化的步骤如下:
(1)初始化设置
使用之前代码训练CNN模型,然后将模型设为评估模式,准备类别名称列表(如飞机、汽车等)
#1-初始化设置
model.eval() # 进入评估模式
classes = ['飞机', '汽车', '鸟', '猫', '鹿', '狗', '青蛙', '马', '船', '卡车'] # 类别名称(2)数据加载与处理
从测试数据加载器中获取图像和标签,并设置处理图像的数量(前num_images张)
#2-数据加载与处理
image_list = []
label_list = []
for imgs,labels in test_loader:
image_list.append(imgs)
label_list.append(labels)
if len(image_list)*test_loader.batch_size >= num_images:
break
images = torch.cat(image_list,dim=0)[:num_images].to(device)
labels = torch.cat(label_list,dim=0)[:num_images].to(device)(3)注册钩子捕获特征图
为指定层注册前向钩子,并将这些层的输出(特征图)保存到字典中
#3-注册钩子捕获特征图
with torch.no_grad():
feature_maps = {} # 存储每层输出的特征图
hooks = [] # 存储Hook,便于后续移除
def hook(module,input,ouput,name):
feature_maps[name] = ouput.detach() # 获得输出,并存入字典
for name in layer_names:
module = getattr(model,name)
handle_hook = module.register_forward_hook(lambda m,i,o,n=name:hook(m,i,o,n))
hooks.append(handle_hook)
(4)前向传播与特征提取
模型处理图像,触发钩子函数,获取并保存特征图。完成后,移除钩子,避免后续干扰。
#4-前向传播与特征提取
out = model(images) # 前向传播,触发钩子,获取特征图
# 完成后,移除hook
for hook_handle in hooks:
hook_handle.remove()(5)可视化特征图(核心)
对每张图像:
- 恢复原始像素值并显示(反标准化)
- 为每个目标层创建子图,展示前 num_channels 个通道的特征图(如9个通道)
- 每个通道的特征图以网格形式排列,显示通道编号
注意:

#5-可视化特征图
for img_idx in range(num_images):
# 0-反标准化处理,便于imshow()显示
img = images[img_idx].cpu().permute(1,2,0).numpy() # 转换为numpy数组
mean = np.array([0.4914, 0.4822, 0.4465])
std = np.array([0.2023, 0.1994, 0.2010])
img = img*std.reshape(1,1,3) + mean.reshape(1,1,3) # 反标准化
img = np.clip(img,0,1) # 确保像素值在[0,1]之间
# 1-创建子图
num_layers = len(layer_names)
fig,axes = plt.subplots(1,num_layers+1,figsize=(4 * (num_layers + 1), 4))
# 2-绘制原始图像,axes[0]
axes[0].imshow(img)
axes[0].set_title(f'Original Picture\nClass Name:{classes[labels[img_idx]]}')
axes[0].axis('off')
# 3-绘制每一层,axes[1]、axes[2]...
for layer_idx,layer_name in enumerate(layer_names):
# 获取前n个通道
fm = feature_maps[layer_name][img_idx] # 获取当前图像在当前层的特征图输出
fm = fm[:num_channels] # 获取该图像的前n个通道的特征图
# 根据通道数目,计算网格排布
num_rows = int(np.sqrt(num_channels))
num_cols = num_channels // num_rows if num_rows != 0 else 1
# 创建子图网络(通道的)
layer_ax = axes[layer_idx+1] # 定位
layer_ax.set_title(f'{layer_name} Feature Map\n')
layer_ax.axis('off')
# 绘制当前层的每一个通道
for ch_idx,channel in enumerate(fm):
ax = layer_ax.inset_axes([
ch_idx % num_cols / num_cols, # 列数目
(num_rows - 1 - ch_idx // num_cols) / num_rows, # 行数目
1/num_cols, # 宽
1/num_rows # 高
])
ax.imshow(channel.cpu().numpy(),cmap='viridis')
ax.set_title(f'Channel {ch_idx + 1}')
ax.axis('off')
plt.tight_layout()
plt.show()
完整代码(特征图可视化):
# 特征图可视化
def visualize_feature_maps(model,test_loader,device,layer_names,num_images=3,num_channels=9):
"""
可视化指定层的特征图(修复循环冗余问题)
参数:
model: 模型
test_loader: 测试数据加载器
layer_names: 要可视化的层名称(如['conv1', 'conv2', 'conv3'])
num_images: 可视化的图像总数
num_channels: 每个图像显示的通道数(取前num_channels个通道)
"""
#1-初始化设置
model.eval() # 进入评估模式
classes = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck'] # 类别名称
#2-数据加载与处理
image_list = []
label_list = []
for imgs,labels in test_loader:
image_list.append(imgs)
label_list.append(labels)
if len(image_list)*test_loader.batch_size >= num_images:
break
# 拼接并截取到目标数量,收集的数量可能超过目标数
images = torch.cat(image_list,dim=0)[:num_images].to(device)
labels = torch.cat(label_list,dim=0)[:num_images].to(device)
#3-注册钩子捕获特征图
with torch.no_grad():
feature_maps = {} # 存储每层输出的特征图
hooks = [] # 存储Hook,便于后续移除
# 定义钩子函数,捕获指定层的输出
def hook(module,input,ouput,name): # name自定义标识,用于区分不同层
feature_maps[name] = ouput.detach() # 获得输出,并存入字典
# 为每个目标层注册钩子,并保存钩子句柄
for name in layer_names: # 遍历所有想要监控的层名称,如layer_names = ['conv1', 'layer1', 'fc']
module = getattr(model,name) #通过名称从模型中获取对应的层对象,如model.conv1
handle_hook = module.register_forward_hook(lambda m,i,o,n=name:hook(m,i,o,n)) # 需要额外参数,引入匿名函数
hooks.append(handle_hook)
#4-前向传播与特征提取
out = model(images) # 前向传播,触发钩子,获取特征图
# 完成后,移除hook
for hook_handle in hooks:
hook_handle.remove()
#5-可视化特征图
for img_idx in range(num_images):
# 0-反标准化处理,便于imshow()显示
img = images[img_idx].cpu().permute(1,2,0).numpy() # 转换为numpy数组
mean = np.array([0.4914, 0.4822, 0.4465])
std = np.array([0.2023, 0.1994, 0.2010])
img = img*std.reshape(1,1,3) + mean.reshape(1,1,3) # 反标准化
img = np.clip(img,0,1) # 确保像素值在[0,1]之间
# 1-创建子图
num_layers = len(layer_names)
fig,axes = plt.subplots(1,num_layers+1,figsize=(6 * (num_layers + 1), 6))
# 2-绘制原始图像,axes[0]
axes[0].imshow(img)
axes[0].set_title(f'Original Picture\nClass Name:{classes[labels[img_idx]]}')
axes[0].axis('off')
# 3-绘制每一层,axes[1]、axes[2]...
for layer_idx,layer_name in enumerate(layer_names):
# 获取前n个通道
fm = feature_maps[layer_name][img_idx] # 获取当前图像在当前层的特征图输出
fm = fm[:num_channels] # 获取该图像的前n个通道的特征图
# 根据通道数目,计算网格排布
num_rows = int(np.sqrt(num_channels))
num_cols = num_channels // num_rows if num_rows != 0 else 1
# 创建子图网络(通道的)
layer_ax = axes[layer_idx+1] # 定位子图位置
layer_ax.set_title(f'{layer_name} Feature Map\n')
layer_ax.axis('off') # 关闭大子图的坐标轴
# 绘制当前层的每一个通道,避免重叠
for ch_idx,channel in enumerate(fm):
ax = layer_ax.inset_axes([
ch_idx % num_cols / num_cols, # 列数目
(num_rows - 1 - ch_idx // num_cols) / num_rows, # 行数目
1/num_cols, # 宽
1/num_rows # 高
])
ax.imshow(channel.cpu().numpy(),cmap='viridis')
ax.set_title(f'Channel {ch_idx + 1}')
ax.axis('off')
plt.tight_layout()
plt.show()
# 调用示例(按需修改参数)
layer_names = ['conv1', 'conv2', 'conv3']
visualize_feature_maps(
model=model,
test_loader=test_loader,
device=device,
layer_names=layer_names,
num_images=5, # 可视化5张测试图像 → 输出5张大图
num_channels=9 # 每张图像显示前9个通道的特征图
)可视化图的分析
结果
提取CNN中不同卷积层输出的特征图:
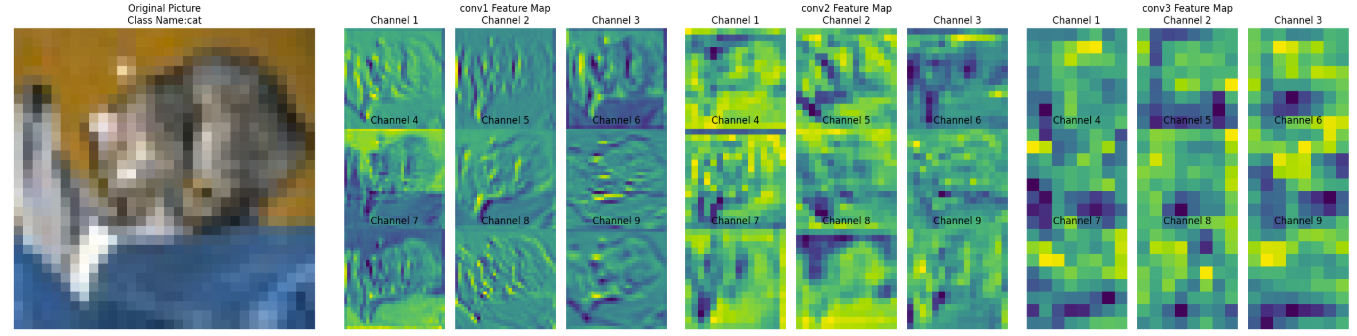
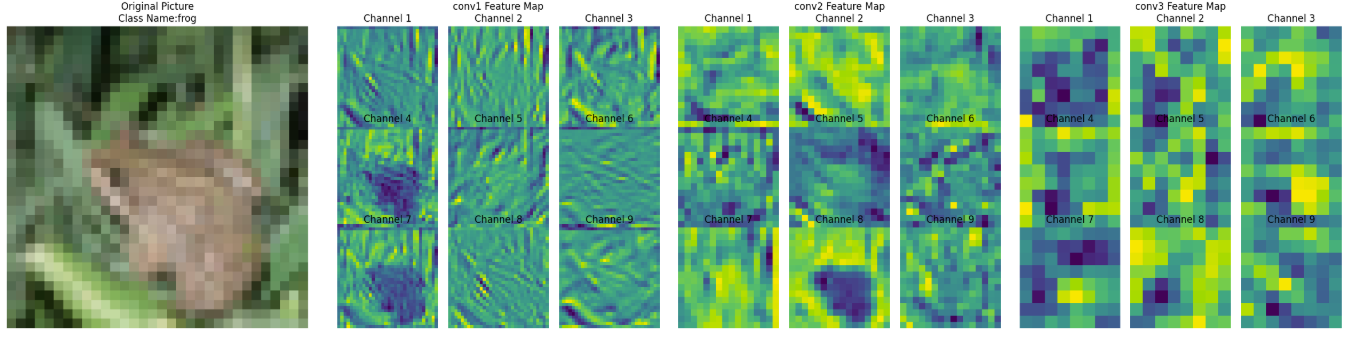
分析(Frog)
conv1 特征图——浅层卷积
捕获边缘、纹理等低级特征,类似人眼初步识别图像的轮廓和基础结构。
- 保留较多原始图像的细节纹理(如植物叶片、青蛙身体的边缘轮廓)。
- 通道间差异相对小,每个通道都能看到类似原始图像的基础结构(如通道 1 - 9 都能识别边缘、纹理)。
- 提取低级特征(边缘、颜色块、简单纹理),是后续高层特征的“原材料”。
conv2 特征图——中层卷积
类似人眼从“边缘轮廓”过渡到“识别局部结构”(如青蛙的身体块、植物的叶片簇)。
- 空间尺寸(高、宽)比 conv1 更小(因卷积/池化下采样),但语义信息更抽象。
- 通道间差异更明显:部分通道开始聚焦局部关键特征(如通道 5、8 中黄色高亮区域,可能对应青蛙身体或植物的关键纹理)。
- 组合与筛选 conv1 的低级特征,提取中级特征(如局部形状、纹理组合)。
conv3 特征图——深层卷积
组合低级特征形成语义概念,类似人眼最终“识别出这是青蛙”的关键依据,模型通过这些特征判断类别。
- 空间尺寸进一步缩小,抽象程度最高,肉眼难直接对应原始图像细节。
- 通道间差异极大,部分通道聚焦全局语义特征(如通道 4、7 中黄色区域,可能对应模型判断“青蛙”类别的关键特征)。
- 全局整合 conv2 的中级特征,提取高级语义特征(如物体类别相关的抽象模式)。
小结
- 特征逐层抽象:从“看得见的细节”(conv1)→ “局部结构”(conv2)→ “类别相关的抽象模式”(conv3),模型通过这种方式实现从“看图像”到“理解语义”的跨越。
- 通道分工明确:不同通道在各层聚焦不同特征(如有的通道负责边缘,有的负责颜色,有的负责全局语义),共同协作完成分类任务。
- 下采样的作用:通过缩小空间尺寸,换取更高的语义抽象能力(“牺牲细节,换取理解”)。

通道注意力
明日学习

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









