




- tensorboard的发展历史和原理
- tensorboard的常见操作
- tensorboard在cifar上的实战:MLP和CNN模型
作业:对resnet18在cifar10上采用微调策略下,用tensorboard监控训练过程。
为什么使用tensorboard?将之前的手动可视化操作(如训练进度条、loss下降曲线、权重分布图等)集合在一起,实现训练过程的实时动态可视化监控。
一、Tensorboard的发展历史与原理
TensorBoard 是 TensorFlow 生态中的官方可视化工具(也可无缝集成 PyTorch),用于实时监控训练过程、可视化模型结构、分析数据分布、对比实验结果等。它通过网页端交互界面,将枯燥的训练日志转化为直观的图表和图像,帮助开发者快速定位问题、优化模型。
模型训练过程的监控屏幕:直观看到训练过程中的数据变化(比如损失值、准确率)、模型结构、数据分布等。
1.1 发展历史

1.2 原理
核心:把训练过程中的数据先记录到日志文件中,再通过工具把这些日志文件可视化,避免手动打印数据和画图。
- 存数据:训练模型时,训练数据(如loss、accuracy)和模型结构等信息会被写入日志文件中
- 看数据:tensorboard会启动一个本地网页服务,自动读取日志文件里的数据,用图表、图像、文本等形式展示出来(可视化),并且能够实时刷新
二、Tensorborad的常见操作
tensorboard中最经典的功能有:保存模型结构图;保存训练集和验证集的loss变化曲线;保存每一个层结构的权重分布;保存预测图片的预测信息等。
2.1 日志目录的自动管理
- 避免日志目录重复:为新训练创建新的目录,确保每次训练的日志独立存储(对比不同训练任务的结果)。
- 创建SummaryWriter对象:实现将数据写入日志,便于后续可视化
log_dir = 'runs/cifar10_mlp_experiment'
if os.path.exists(log_dir):
i = 1
while os.path.exists(f"{log_dir}_{i}"):
i += 1
log_dir = f"{log_dir}_{i}"
writer = SummaryWriter(log_dir) #关键入口,用于写入数据到日志目录
# writer.close() # 完成写入操作后,记得关闭写入器2.2 记录标量数据(Scaler)
记录损失值和准确率。
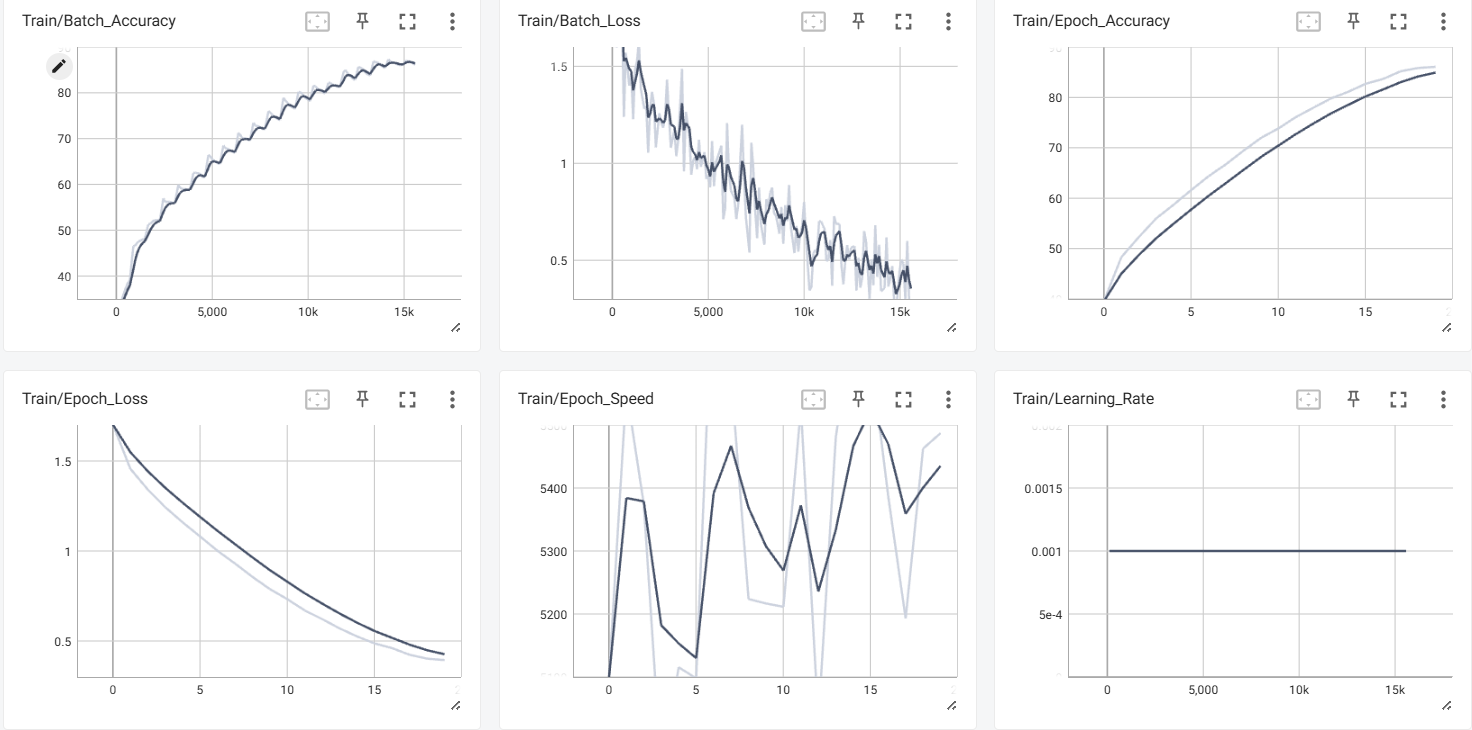
- batch-level:高频记录,使用全局步数(iteration数),曲线波动较大
- epoch-level:低频记录,使用周期数,曲线更加平滑(平均值)
# 记录每个 Batch 的损失和准确率
writer.add_scalar('Train/Batch_Loss', batch_loss, global_step) # global_step:全局步数,已处理的批次总数
writer.add_scalar('Train/Batch_Accuracy', batch_acc, global_step)
# 记录每个 Epoch 的训练指标
writer.add_scalar('Train/Epoch_Loss', epoch_train_loss, epoch)
writer.add_scalar('Train/Epoch_Accuracy', epoch_train_acc, epoch)2.3 可视化模型结构(Graph)
- 整体计算图:模型的完整结构,数据流动路径
- 节点详细信息:操作(卷积、池化、全连接),输入输出形状,参数数量
- 层级结构
dataiter = iter(train_loader) # 将数据加载器转换为迭代器
images, labels = next(dataiter) # 获取第一个批次的数据,一般只使用一个批次
images = images.to(device) # 将图像数据移动到指定设备
writer.add_graph(model, images) # 将模型和真实输入传递给tensorboard,生成模型的计算图2.4 可视化图像(Image)
- 原始图像:显示实际输入,查看数据增强效果
- 错误预测样本:寻找错误样本的共同特征,指导改进方向(数据增强、模型调整)
# 可视化原始训练图像
# TensorBoard需要CPU张量
img_grid = torchvision.utils.make_grid(images[:8].cpu()) # 将多张图像拼接成网格状(方便可视化),将前8张图像拼接成一个网格
writer.add_image('原始训练图像', img_grid) # 图像网格添加到tensorboard
# 可视化错误预测样本(训练结束后)
# wrong_images:存储预测错误的图像样本;display_count:限制显示数量
wrong_img_grid = torchvision.utils.make_grid(wrong_images[:display_count])
writer.add_image('错误预测样本', wrong_img_grid) # 图像网格添加到tensorboard2.5 记录权重和梯度直方图
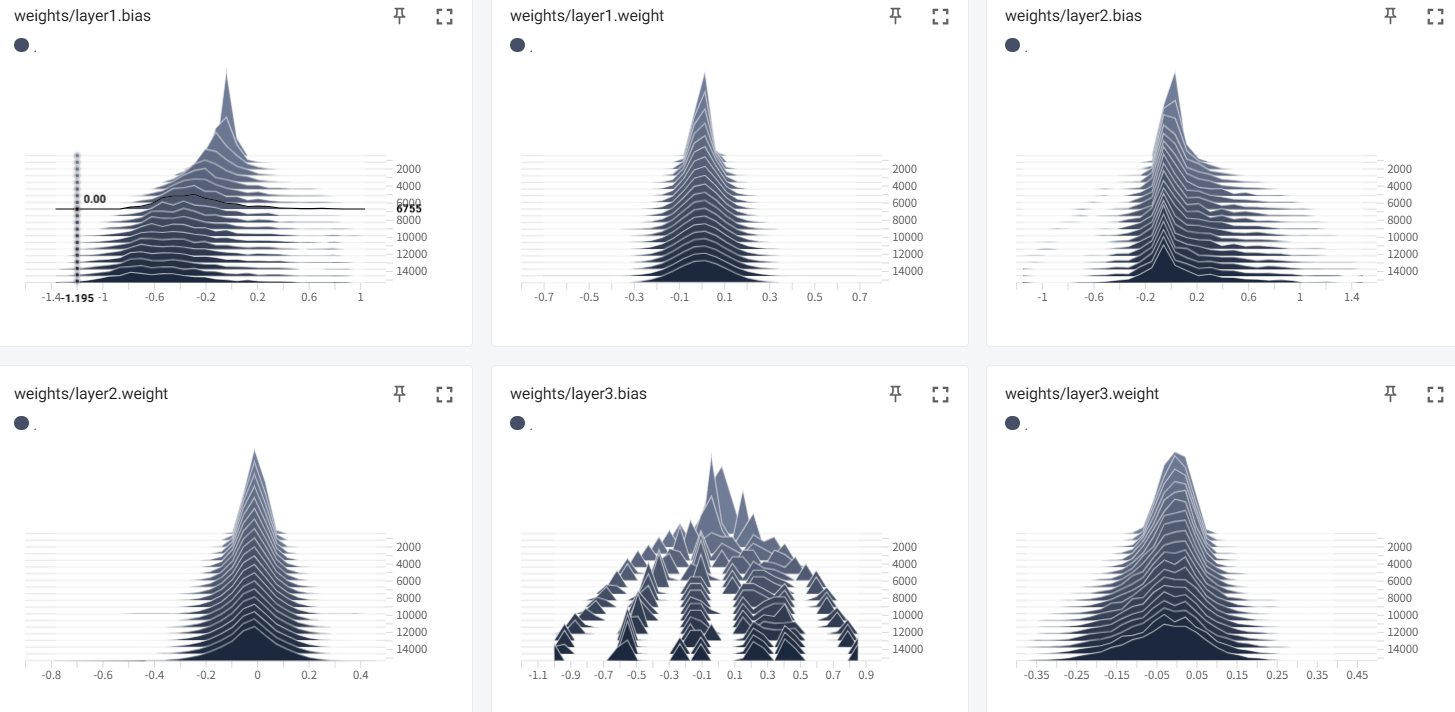
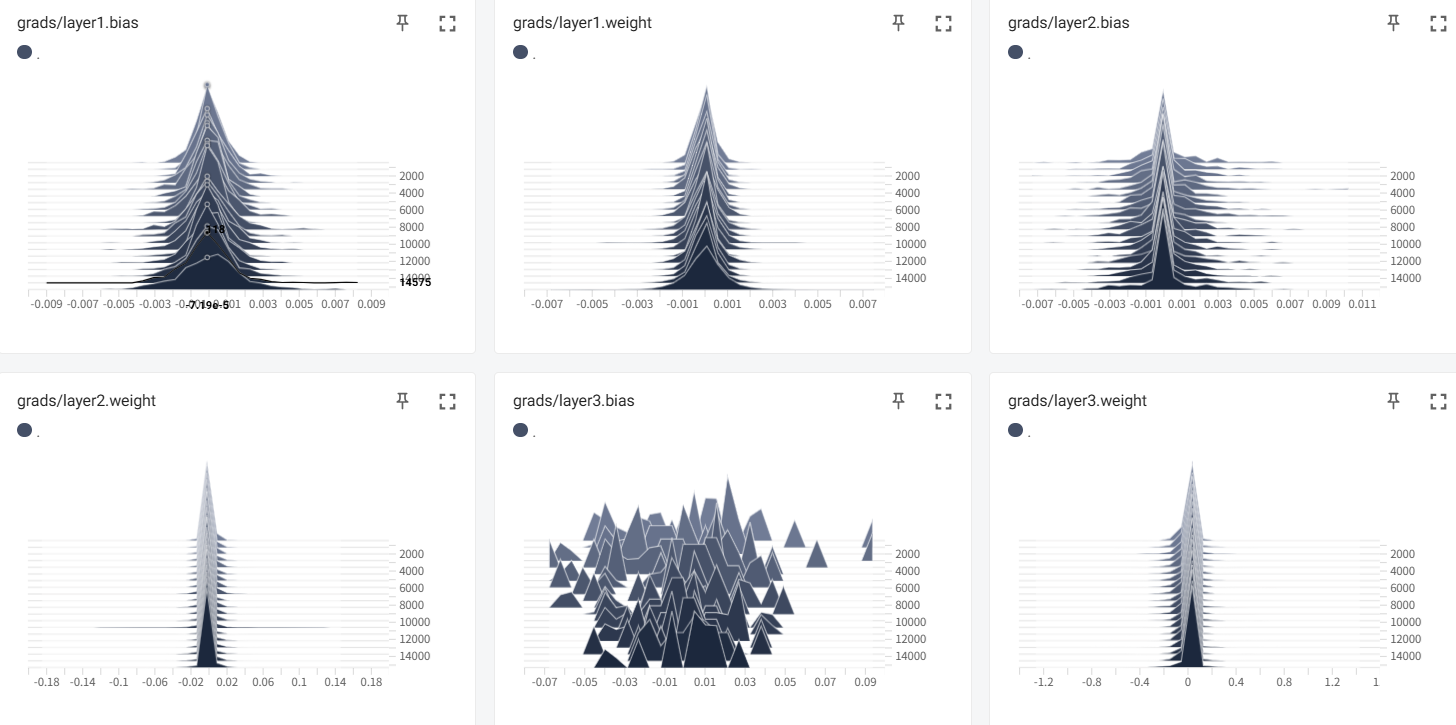
- 权重分布直方图:显示每个参数层的值分布。理论上分布比较稳定;异常(爆炸或消失)
- 梯度分布直方图:显示反向传播的梯度分布。理论上梯度适中;异常(爆炸或消失)
if (batch_idx + 1) % 500 == 0:
for name, param in model.named_parameters(): # 遍历可训练参数
writer.add_histogram(f'weights/{name}', param, global_step) # 权重分布
# 记录反向传播后计算的梯度
if param.grad is not None: # 某些层可能没有梯度
writer.add_histogram(f'grads/{name}', param.grad, global_step) # 梯度分布2.6 启动Tensorboard
运行代码后,会在指定目录(如 runs/cifar10_mlp_experiment_1)生成 .tfevents 文件,存储所有 TensorBoard 数据。
- 在终端执行(需进入项目根目录):tensorboard --logdir=runs # 假设日志目录在 runs/ 下
- 打开浏览器,输入终端提示的 URL(通常为 http://localhost:6006),查看可视化监控
注意:autodl云服务器,直接点击终端的链接,出现无法访问的问题。解决方案:进入容器实例后,点击自定义服务,可以访问端口的服务地址。


进入tensorboard后,可以看到上述选项卡位于左上角:

三、Cifar实战:MLP和CNN模型
3.1 MLP
在之前MLP代码的基础上加入tensorboard的常见操作,同时去除之前的可视化操作代码:
- 创建writer,同时注意目录不可重复
- 模型结构可视化
- 记录标量数据:loss(训练/测试、Batch/Epoch)、accuracy、learning_rate
- 分布直方图:weights、gradients
- 可视化图像:原始图像、预测错误样本图像
- 写入完成,记得关闭writer
# MLP
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import numpy as np
import matplotlib.pyplot as plt
import os
import time
# 设置随机种子以确保结果可复现
torch.manual_seed(42)
np.random.seed(42)
# 1. 数据预处理
transform = transforms.Compose([
transforms.ToTensor(), # 转换为张量
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 标准化处理
])
# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(
root='./data',
train=True,
download=True,
transform=transform
)
test_dataset = datasets.CIFAR10(
root='./data',
train=False,
transform=transform
)
# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# CIFAR-10的类别名称
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# 4. 定义MLP模型(适应CIFAR-10的输入尺寸)
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.flatten = nn.Flatten() # 将3x32x32的图像展平为3072维向量
self.layer1 = nn.Linear(3072, 512) # 第一层:3072个输入,512个神经元
self.relu1 = nn.ReLU()
self.dropout1 = nn.Dropout(0.2) # 添加Dropout防止过拟合
self.layer2 = nn.Linear(512, 256) # 第二层:512个输入,256个神经元
self.relu2 = nn.ReLU()
self.dropout2 = nn.Dropout(0.2)
self.layer3 = nn.Linear(256, 10) # 输出层:10个类别
def forward(self, x):
# 第一步:将输入图像展平为一维向量
x = self.flatten(x) # 输入尺寸: [batch_size, 3, 32, 32] → [batch_size, 3072]
# 第一层全连接 + 激活 + Dropout
x = self.layer1(x) # 线性变换: [batch_size, 3072] → [batch_size, 512]
x = self.relu1(x) # 应用ReLU激活函数
x = self.dropout1(x) # 训练时随机丢弃部分神经元输出
# 第二层全连接 + 激活 + Dropout
x = self.layer2(x) # 线性变换: [batch_size, 512] → [batch_size, 256]
x = self.relu2(x) # 应用ReLU激活函数
x = self.dropout2(x) # 训练时随机丢弃部分神经元输出
# 第三层(输出层)全连接
x = self.layer3(x) # 线性变换: [batch_size, 256] → [batch_size, 10]
return x # 返回未经过Softmax的logits
# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 初始化模型
model = MLP()
model = model.to(device) # 将模型移至GPU(如果可用)
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器
# 创建TensorBoard的SummaryWriter,指定日志保存目录
log_dir = 'runs/cifar10_mlp_experiment'
# 如果目录已存在,添加后缀避免覆盖
if os.path.exists(log_dir):
i = 1
while os.path.exists(f"{log_dir}_{i}"):
i += 1
log_dir = f"{log_dir}_{i}"
writer = SummaryWriter(log_dir)
# 5. 训练模型(使用TensorBoard记录各种信息)
def train(model, train_loader, test_loader, criterion, optimizer, device, epochs, writer):
model.train() # 设置为训练模式
# 记录训练开始时间,用于计算训练速度
global_step = 0
# 可视化模型结构
dataiter = iter(train_loader)
images, labels = next(dataiter)
images = images.to(device)
writer.add_graph(model, images) # 添加模型图
# 可视化原始图像样本
img_grid = torchvision.utils.make_grid(images[:8].cpu())
writer.add_image('原始训练图像', img_grid)
for epoch in range(epochs):
running_loss = 0.0
correct = 0
total = 0
# 记录时间
epoch_start = time.time()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device) # 移至GPU
optimizer.zero_grad() # 梯度清零
output = model(data) # 前向传播
loss = criterion(output, target) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新参数
# 统计准确率和损失
running_loss += loss.item()
_, predicted = output.max(1)
total += target.size(0)
correct += predicted.eq(target).sum().item()
# 每100个批次记录一次信息到TensorBoard
if (batch_idx + 1) % 100 == 0:
batch_loss = loss.item()
batch_acc = 100. * correct / total
# 记录标量数据(损失、准确率)
writer.add_scalar('Train/Batch_Loss', batch_loss, global_step)
writer.add_scalar('Train/Batch_Accuracy', batch_acc, global_step)
# 记录学习率
writer.add_scalar('Train/Learning_Rate', optimizer.param_groups[0]['lr'], global_step)
# 每500个批次记录一次直方图(权重和梯度)
if (batch_idx + 1) % 500 == 0:
for name, param in model.named_parameters():
writer.add_histogram(f'weights/{name}', param, global_step)
if param.grad is not None:
writer.add_histogram(f'grads/{name}', param.grad, global_step)
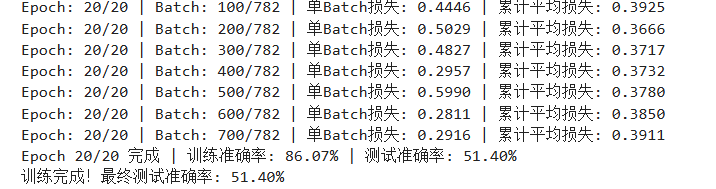
print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} '
f'| 单Batch损失: {batch_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')
global_step += 1
# 计算当前epoch的平均训练损失和准确率
epoch_train_loss = running_loss / len(train_loader)
epoch_train_acc = 100. * correct / total
# 记录每个epoch的训练损失和准确率
writer.add_scalar('Train/Epoch_Loss', epoch_train_loss, epoch)
writer.add_scalar('Train/Epoch_Accuracy', epoch_train_acc, epoch)
# 测试阶段
model.eval() # 设置为评估模式
test_loss = 0
correct_test = 0
total_test = 0
# 用于存储预测错误的样本
wrong_images = []
wrong_labels = []
wrong_preds = []
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += criterion(output, target).item()
_, predicted = output.max(1)
total_test += target.size(0)
correct_test += predicted.eq(target).sum().item()
# 收集预测错误的样本
wrong_mask = (predicted != target).cpu() # 返回布尔索引
if wrong_mask.sum() > 0:
wrong_batch_images = data[wrong_mask].cpu() # 提取错误图像 → [img2]
wrong_batch_labels = target[wrong_mask].cpu() # 对应的真实标签 → [dog]
wrong_batch_preds = predicted[wrong_mask].cpu() # 错误预测标签 → [cat]
# 使用extend直接得到一维列表,append会得到嵌套列表
wrong_images.extend(wrong_batch_images)
wrong_labels.extend(wrong_batch_labels)
wrong_preds.extend(wrong_batch_preds)
epoch_test_loss = test_loss / len(test_loader)
epoch_test_acc = 100. * correct_test / total_test
# 记录每个epoch的测试损失和准确率
writer.add_scalar('Test/Loss', epoch_test_loss, epoch)
writer.add_scalar('Test/Accuracy', epoch_test_acc, epoch)
# 计算每个epoch的速度
epoch_end = time.time()
epoch_duration = epoch_end - epoch_start
samples_per_epoch = len(train_loader.dataset) # 每个epoch处理的样本总数
epoch_speed = samples_per_epoch / epoch_duration
# 记录速度指标
writer.add_scalar('Train/Epoch_Speed', epoch_speed, epoch)
print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')
# 可视化预测错误的样本(只在最后一个epoch进行)
if epoch == epochs - 1 and len(wrong_images) > 0:
# 最多显示8个错误样本
display_count = min(8, len(wrong_images))
wrong_img_grid = torchvision.utils.make_grid(wrong_images[:display_count])
# 创建错误预测的标签文本
wrong_text = []
for i in range(display_count):
true_label = classes[wrong_labels[i]]
pred_label = classes[wrong_preds[i]]
wrong_text.append(f'True: {true_label}, Pred: {pred_label}')
writer.add_image('错误预测样本', wrong_img_grid)
writer.add_text('错误预测标签', '\n'.join(wrong_text), epoch)
# 关闭TensorBoard写入器
writer.close()
return epoch_test_acc # 返回最终测试准确率
# 6. 执行训练和测试
epochs = 20 # 训练轮次
print("开始训练模型...")
print(f"TensorBoard日志保存在: {log_dir}")
print("训练完成后,使用命令 `tensorboard --logdir=runs` 启动TensorBoard查看可视化结果")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs, writer)
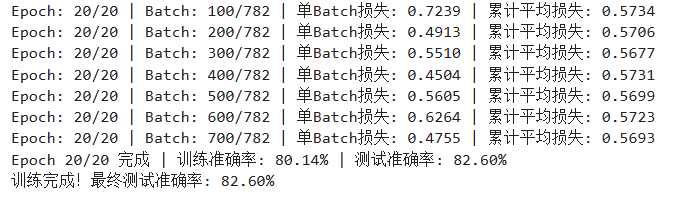
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")最终准确率为 51.40 %(epoch = 20)
进入tensorboard后可以看到所有的tag:
训练的batch和epoch的损失值和准确度:
权重
梯度
原始图像:

预测错误样本(最后一个epoch):

3.2 CNN
同样地,在之前的CNN代码加入tensorboard操作,同时去除冗余的可视化操作代码:
# CNN
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import matplotlib.pyplot as plt
import numpy as np
import os
import torchvision # 记得导入 torchvision,之前代码里用到了其功能但没导入
import time
# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
# 1. 数据预处理
train_transform = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),
transforms.RandomRotation(15),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(
root='./data',
train=True,
download=True,
transform=train_transform
)
test_dataset = datasets.CIFAR10(
root='./data',
train=False,
transform=test_transform
)
# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 4. 定义CNN模型的定义(替代原MLP)
class CNN(nn.Module):
def __init__(self):
super(CNN,self).__init__()
# 第一层卷积
self.conv1 = nn.Conv2d(3,32,kernel_size=3,padding=1)
self.bn1 = nn.BatchNorm2d(num_features=32) # 批量归一化层:对32个输出通道进行归一化,加速训练
# 第二层卷积
self.conv2 = nn.Conv2d(32,64,kernel_size=3,padding=1)
self.bn2 = nn.BatchNorm2d(num_features=64)
# 第三层卷积
self.conv3 = nn.Conv2d(64,128,kernel_size=3,padding=1)
self.bn3 = nn.BatchNorm2d(num_features=128)
# 池化层
self.pool = nn.MaxPool2d(kernel_size=2,stride=2)
# 第一层全连接层
self.flatten = nn.Flatten()
self.fc1 = nn.Linear(128*4*4,512)
self.dropout = nn.Dropout(p=0.5) # 训练时随机丢弃50%神经元,防止过拟合
# 第二层全连接层
self.fc2 = nn.Linear(512,10)
def forward(self,x):
# 第一层卷积
x =self.pool(self.bn1(F.relu(self.conv1(x)))) # 输出:32*16*16
# 第二层卷积
x = self.pool(self.bn2(F.relu(self.conv2(x)))) # 输出:64*8*8
# 第三层卷积
x = self.pool(self.bn3(F.relu(self.conv3(x)))) # 输出:128*4*4
# 第一层全连接层
x = self.flatten(x) # 展平
x = F.relu(self.fc1(x))
x = self.dropout(x)
# 第二层全连接层
x = self.fc2(x)
return x
# 初始化模型
model = CNN()
model = model.to(device) # 将模型移至GPU(如果可用)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(
optimizer, # 指定要控制的优化器(这里是Adam)
mode='min', # 监测的指标是"最小化"(如损失函数)
patience=3, # 如果连续3个epoch指标没有改善,才降低LR
factor=0.5, # 降低LR的比例(新LR = 旧LR × 0.5)
verbose=True # 打印学习率调整信息
)
# ======================== TensorBoard 核心配置 ========================
# 创建 TensorBoard 日志目录(自动避免重复)
log_dir = "runs/cifar10_cnn_exp"
if os.path.exists(log_dir):
version = 1
while os.path.exists(f"{log_dir}_v{version}"):
version += 1
log_dir = f"{log_dir}_v{version}"
writer = SummaryWriter(log_dir) # 初始化 SummaryWriter
# 5. 训练模型(整合 TensorBoard 记录)
def train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs, writer):
model.train()
global_step = 0 #全局步骤,用于 TensorBoard 标量记录
# (可选)记录模型结构:用一个真实样本走一遍前向传播,让 TensorBoard 解析计算图
dataiter = iter(train_loader)
images, labels = next(dataiter)
images = images.to(device)
writer.add_graph(model, images) # 写入模型结构到 TensorBoard
# (可选)记录原始训练图像:可视化数据增强前/后效果
img_grid = torchvision.utils.make_grid(images[:8].cpu()) # 取前8张
writer.add_image('原始训练图像(增强前)', img_grid, global_step=0)
for epoch in range(epochs):
running_loss = 0.0
correct = 0
total = 0
# 记录时间
epoch_start = time.time()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
# 统计准确率
running_loss += loss.item()
_, predicted = output.max(1)
total += target.size(0)
correct += predicted.eq(target).sum().item()
# ======================== TensorBoard 标量记录 ========================
# 每 100 个 batch 打印控制台日志(同原代码)
if (batch_idx + 1) % 100 == 0:
batch_loss = loss.item()
batch_acc = 100. * correct / total
# 记录标量数据(loss\accuracy)
writer.add_scalar('Train/Batch Loss', batch_loss, global_step)
writer.add_scalar('Train/Batch Accuracy', batch_acc, global_step)
# 记录学习率(可选)
writer.add_scalar('Train/Learning Rate', optimizer.param_groups[0]['lr'], global_step)
print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} '
f'| 单Batch损失: {batch_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')
# 每 200 个 batch 记录一次参数直方图(可选,耗时稍高)
if (batch_idx + 1) % 200 == 0:
for name, param in model.named_parameters():
writer.add_histogram(f'Weights/{name}', param, global_step)
if param.grad is not None:
writer.add_histogram(f'Gradients/{name}', param.grad, global_step)
global_step += 1 # 全局步骤递增
# 计算 epoch 级训练指标
epoch_train_loss = running_loss / len(train_loader)
epoch_train_acc = 100. * correct / total
# ======================== TensorBoard epoch 标量记录 ========================
writer.add_scalar('Train/Epoch Loss', epoch_train_loss, epoch)
writer.add_scalar('Train/Epoch Accuracy', epoch_train_acc, epoch)
# 测试阶段
model.eval()
test_loss = 0
correct_test = 0
total_test = 0
wrong_images = [] # 存储错误预测样本(用于可视化)
wrong_labels = []
wrong_preds = []
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += criterion(output, target).item()
_, predicted = output.max(1)
total_test += target.size(0)
correct_test += predicted.eq(target).sum().item()
# 收集错误预测样本(用于可视化)
wrong_mask = (predicted != target)
if wrong_mask.sum() > 0:
wrong_batch_images = data[wrong_mask][:8].cpu() # 最多存8张
wrong_batch_labels = target[wrong_mask][:8].cpu()
wrong_batch_preds = predicted[wrong_mask][:8].cpu()
wrong_images.extend(wrong_batch_images)
wrong_labels.extend(wrong_batch_labels)
wrong_preds.extend(wrong_batch_preds)
# 计算 epoch 级测试指标
epoch_test_loss = test_loss / len(test_loader)
epoch_test_acc = 100. * correct_test / total_test
# ======================== TensorBoard 测试集记录 ========================
writer.add_scalar('Test/Epoch Loss', epoch_test_loss, epoch)
writer.add_scalar('Test/Epoch Accuracy', epoch_test_acc, epoch)
# 计算每个epoch的速度
epoch_end = time.time()
epoch_duration = epoch_end - epoch_start
samples_per_epoch = len(train_loader.dataset) # 每个epoch处理的样本总数
epoch_speed = samples_per_epoch / epoch_duration
# 记录速度指标
writer.add_scalar('Train/Epoch_Speed', epoch_speed, epoch)
# (可选)可视化错误预测样本
# if wrong_images:
# wrong_img_grid = torchvision.utils.make_grid(wrong_images)
# writer.add_image('错误预测样本', wrong_img_grid, epoch)
# # 写入错误标签文本(可选)
# wrong_text = [f"真实: {classes[wl]}, 预测: {classes[wp]}"
# for wl, wp in zip(wrong_labels, wrong_preds)]
# writer.add_text('错误预测标签', '\n'.join(wrong_text), epoch)
# 更新学习率调度器
scheduler.step(epoch_test_loss)
print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')
# 关闭 TensorBoard 写入器
writer.close()
return epoch_test_acc
# (可选)CIFAR-10 类别名
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# 7. 执行训练(传入 TensorBoard writer)
epochs = 20
print("开始使用CNN训练模型...")
print(f"TensorBoard 日志目录: {log_dir}")
print("训练后执行: tensorboard --logdir=runs 查看可视化")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs, writer)
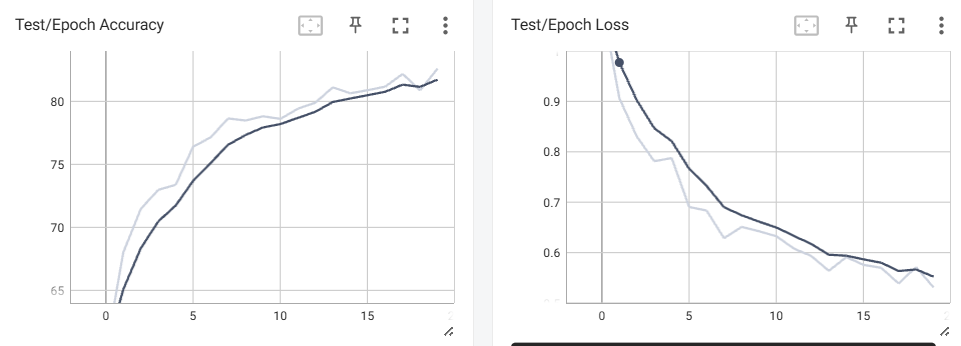
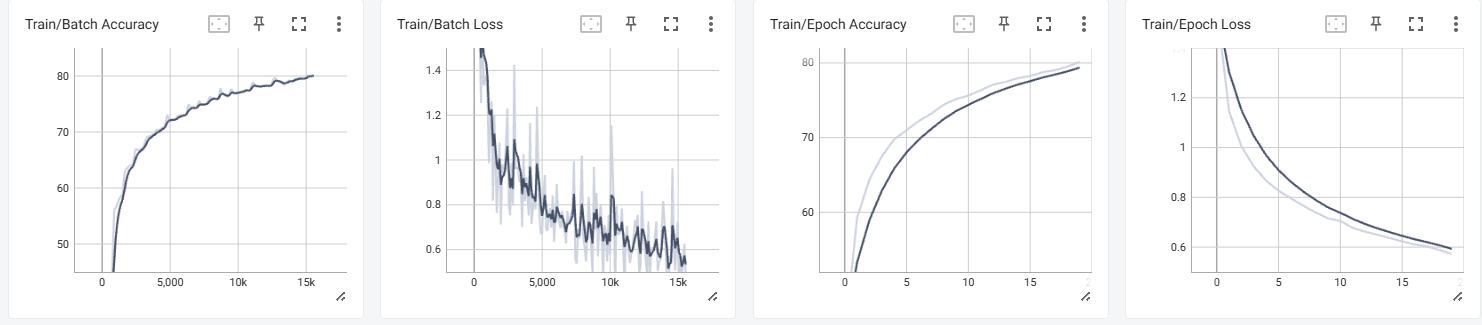
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")最终准确率为 82.60 %(epoch = 20)
原始图像:

测试的损失值和准确率:
训练的batch和epoch的损失值和准确度:
梯度:
四、作业:Resnet18预训练 + Tensorboard监控
# 作业:resnet18 预训练 + tensorboard监控
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import matplotlib.pyplot as plt
import numpy as np
import os
import torchvision
import time
# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
# 1. 数据预处理(训练集增强,测试集标准化)
train_transform = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),
transforms.RandomRotation(15),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(
root='./data',
train=True,
download=True,
transform=train_transform
)
test_dataset = datasets.CIFAR10(
root='./data',
train=False,
transform=test_transform
)
# 3. 创建数据加载器(可调整batch_size)
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 4-定义ResNet18模型
from torchvision.models import resnet18
def create_resnet18(pretrained=True,num_classes=10):
# 加载参数
model = resnet18(pretrained=pretrained)
# 修改全连接层:输出类别数目
in_features = model.fc.in_features # 获取最后一层的输入数目
model.fc = nn.Linear(in_features=in_features,out_features=num_classes) # 修改输出类别数
# 迁移模型
model = model.to(device) # device为全局变量
return model
# 5-定义冻结/解冻模型层的函数
def freeze_model(model,freeze=True):
# 冻结逻辑
for name,param in model.named_parameters():
if 'fc' not in name:
param.requires_grad = not freeze
# 打印冻结状态
# p.numel()返回张量中元素的个数
frozen_params = sum(p.numel() for p in model.parameters() if not p.requires_grad)
total_params = sum(p.numel() for p in model.parameters())
if freeze:
print('已冻结模型卷积层参数:{}/{} 参数'.format(frozen_params,total_params))
else:
print('已解冻模型所有参数:{}/{} 参数可训练'.format(total_params,total_params))
return model
# 创建TensorBoard的SummaryWriter,指定日志保存目录
log_dir = 'runs/cifar10_resnet18_experiment'
if os.path.exists(log_dir):
i = 1
while os.path.exists(f'log_dir_{i}'):
i += 1
log_dir = f'log_dir_{i}'
writer = SummaryWriter(log_dir=log_dir)
# 6. 训练函数(支持学习率调度器)
def train_with_freeze_schedule(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs,freeze_epochs,writer):
global_step = 0 # 全局步数
# 可视化模型结构
dataiter = iter(train_loader)
images,labels = next(dataiter)
images = images.to(device)
writer.add_graph(model,images)
# 可视化原始图像样本
img_grid = torchvision.utils.make_grid(images[:8].cpu())
writer.add_image(tag='Original_Image',img_tensor=img_grid)
# 冻结
if freeze_epochs > 0:
model = freeze_model(model=model)
# 遍历epoch
for epoch in range(epochs):
# 记录时间
epoch_start = time.time()
if epoch == freeze_epochs: # 解冻
model = freeze_model(model,freeze=False)
# 解冻后调整优化器(可选)
#optimizer.param_groups[0]['lr'] = 1e-4 # 降低学习率防止过拟合
model.train() # 设置为训练模式
running_loss = 0.0
correct_train = 0
total_train = 0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
# 统计训练指标
running_loss += loss.item()
_, predicted = output.max(1)
total_train += target.size(0)
correct_train += predicted.eq(target).sum().item()
# 每100批次打印进度
if (batch_idx + 1) % 100 == 0:
batch_loss = loss.item()
batch_acc = 100. * correct_train / total_train
# 写入损失值和准确率
writer.add_scalar(tag='Train/Batch_Loss',scalar_value=batch_loss,global_step=global_step)
writer.add_scalar(tag='Train/Batch_Accuracy',scalar_value=batch_acc,global_step=global_step)
# 记录学习率
writer.add_scalar('Train/Learning_Rate', optimizer.param_groups[0]['lr'], global_step)
print(f"Epoch {epoch+1}/{epochs} | Batch {batch_idx+1}/{len(train_loader)} "
f"| 单Batch损失: {batch_loss:.4f}")
# 直方图(权重和梯度)
if (batch_idx + 1) % 500 == 0:
for name,param in model.named_parameters():
writer.add_histogram(tag=f'weights/{name}',values=param,global_step=global_step)
if param.grad is not None:
writer.add_histogram(tag=f'grads/{name}',values=param.grad,global_step=global_step)
global_step += 1
# 计算 epoch 级指标
epoch_train_loss = running_loss / len(train_loader)
epoch_train_acc = 100. * correct_train / total_train
# 记录每个epoch内的训练损失和准确度
writer.add_scalar('Train/Epoch_Loss', epoch_train_loss, epoch)
writer.add_scalar('Train/Epoch_Accuracy', epoch_train_acc, epoch)
# 测试阶段
model.eval()
correct_test = 0
total_test = 0
test_loss = 0.0
# 存储预测错误的样本
wrong_images = []
wrong_labels = []
wrong_preds = []
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += criterion(output, target).item()
_, predicted = output.max(1)
total_test += target.size(0)
correct_test += predicted.eq(target).sum().item()
# 收集预测错误的样本
wrong_mask = (predicted != target).cpu() # 返回布尔索引
if wrong_mask.sum() > 0:
wrong_batch_img = data[wrong_mask].cpu() # 提取错误图像 → [img2]
wrong_batch_labels = target[wrong_mask].cpu() # 对应的真实标签 → [dog]
wrong_batch_preds = predicted[wrong_mask].cpu() # 错误预测标签 → [cat]
# 使用extend直接得到一维列表,append会得到嵌套列表
wrong_images.extend(wrong_batch_img)
wrong_labels.extend(wrong_batch_labels)
wrong_preds.extend(wrong_batch_preds)
epoch_test_loss = test_loss / len(test_loader)
epoch_test_acc = 100. * correct_test / total_test
# 记录每个epoch内的测试损失和准确度
writer.add_scalar('Test/Loss',epoch_test_loss,epoch)
writer.add_scalar('Test/Accuracy',epoch_test_acc,epoch)
# 计算每个epoch的速度
epoch_end = time.time()
epoch_duration = epoch_end - epoch_start
samples_per_epoch = len(train_loader.dataset) # 每个epoch处理的样本总数
epoch_speed = samples_per_epoch / epoch_duration
# 记录速度指标
writer.add_scalar('Train/Epoch_Speed', epoch_speed, epoch)
# 可视化预测错误的样本(只在最后一个epoch进行)
if epoch == epochs - 1 and len(wrong_images) > 0:
# 最多显示8个错误样本
display_count = min(8, len(wrong_images))
wrong_img_grid = torchvision.utils.make_grid(wrong_images[:display_count])
# 创建错误预测的标签文本
wrong_text = []
for i in range(display_count):
true_label = classes[wrong_labels[i]]
pred_label = classes[wrong_preds[i]]
wrong_text.append(f'True: {true_label}, Pred: {pred_label}')
writer.add_image('错误预测样本', wrong_img_grid)
writer.add_text('错误预测标签', '\n'.join(wrong_text), epoch)
# 更新学习率调度器
if scheduler is not None:
scheduler.step(epoch_test_loss)
# 打印 epoch 结果
print(f"Epoch {epoch+1} 完成 | 训练损失: {epoch_train_loss:.4f} "
f"| 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%")
#关闭TensorBoard写入器
writer.close()
return epoch_test_acc # 返回最终测试准确率
# 定义主函数
def main():
# 参数设置
epochs = 40 # 总共的训练轮次
freeze_epochs = 5 # 冻结轮次
lr = 1e-3 # 初始学习率
weight_decay = 1e-4 # 权重衰减:添加L2正则化项惩罚大的权重值,防止过拟合
# 创建resnet18模型
model = create_resnet18(pretrained=True,num_classes=10)
# 创建损失函数、优化器、调度器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(),lr=lr,weight_decay=weight_decay)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(
optimizer=optimizer,
mode='min',
patience=2,
factor=0.5,
verbose=True # 当学习率发生变化时是否打印提示信息
)
# 训练
print('开始训练')
print(f"TensorBoard 日志目录: {log_dir}")
print("训练后执行: tensorboard --logdir=runs 查看可视化")
final_acc = train_with_freeze_schedule(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs,freeze_epochs,writer)
print(f'训练完成!最终测试准确率为:{final_acc:.2f}%')
# # 保存模型
# torch.save(model.state_dict(), 'resnet18_cifar10_finetuned.pth')
# print("模型已保存至: resnet18_cifar10_finetuned.pth")
# 调用主函数
if __name__ == '__main__':
main()
最终准确率为 86.06 %(epoch = 40,使用resnet18预训练模型)
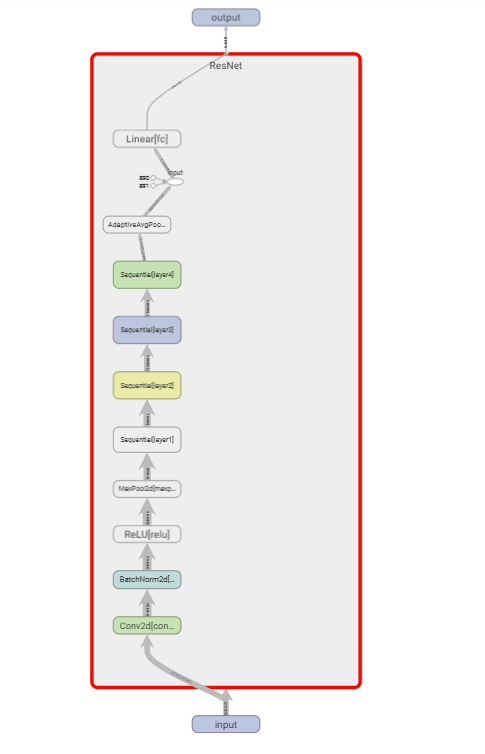
4.1 模型结构(Graph)
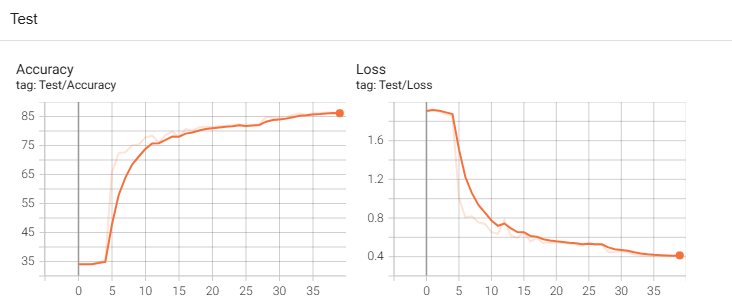
4.2 测试和训练的loss、accuracy(Scaler)
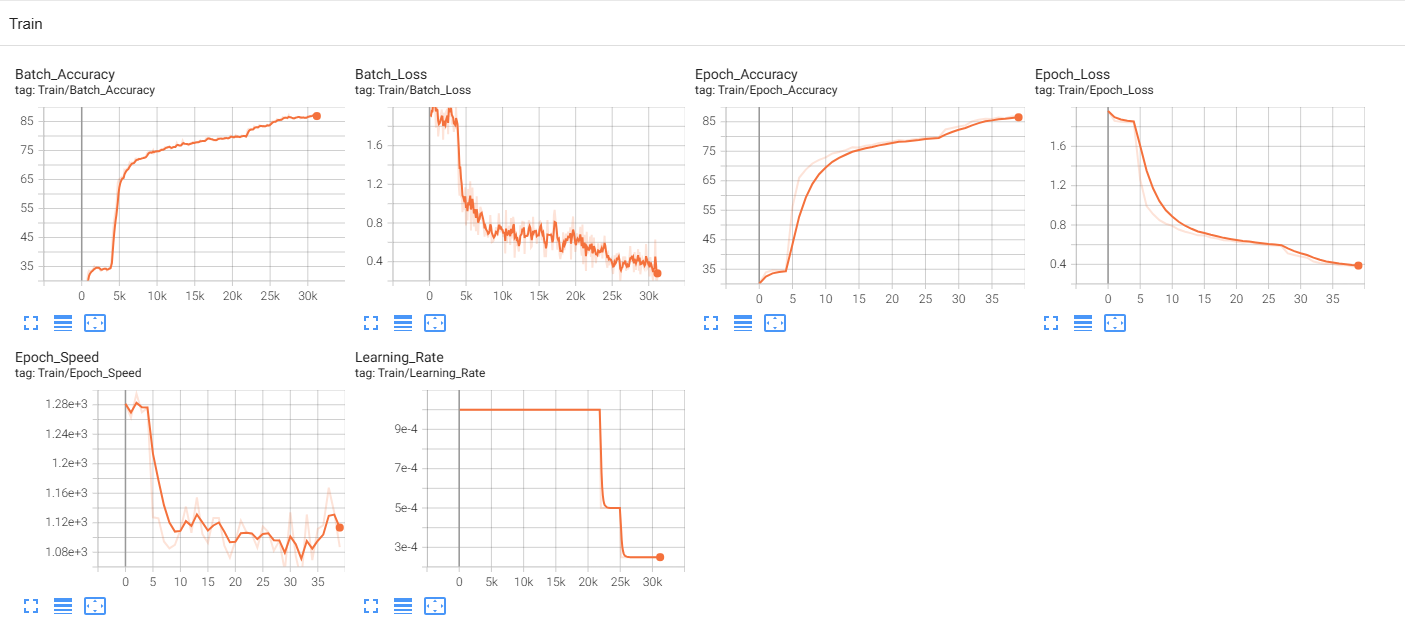
4.3 原始图像和预测错误的样本图像(Image)


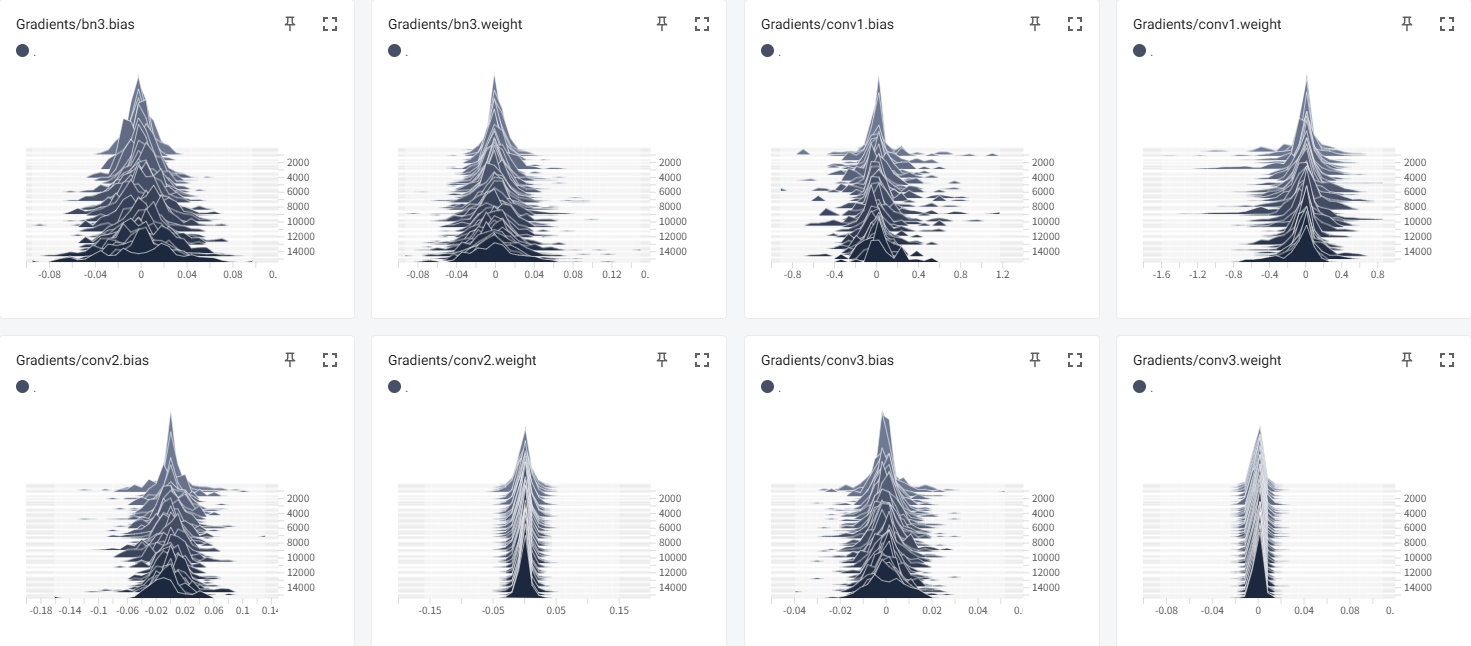
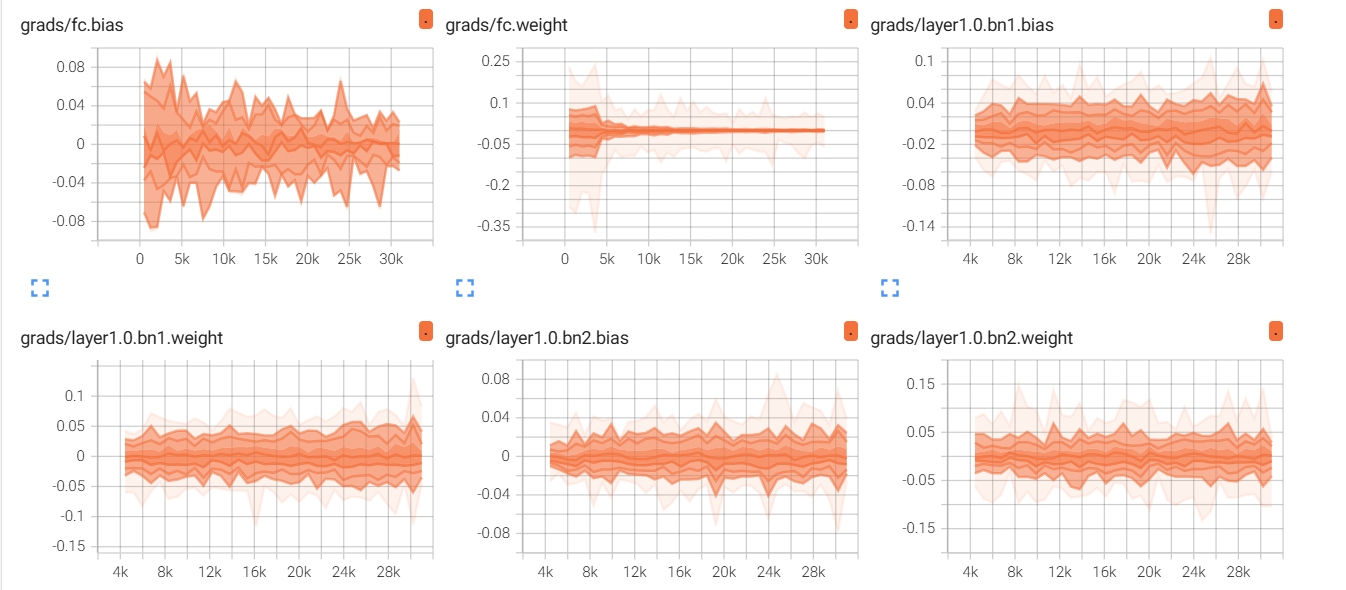
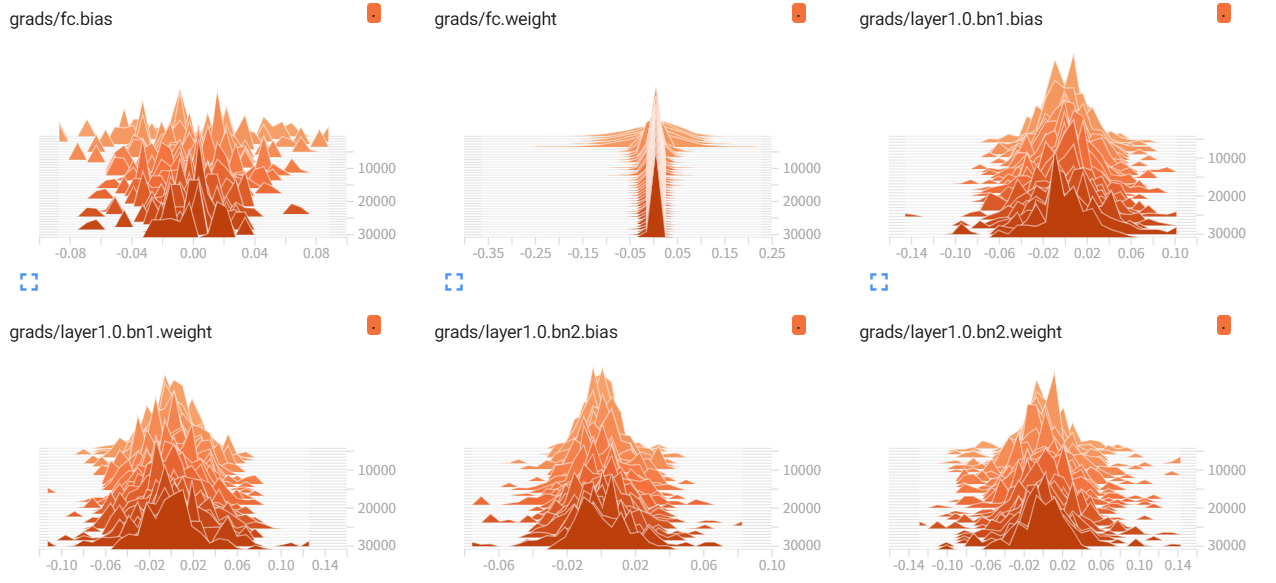
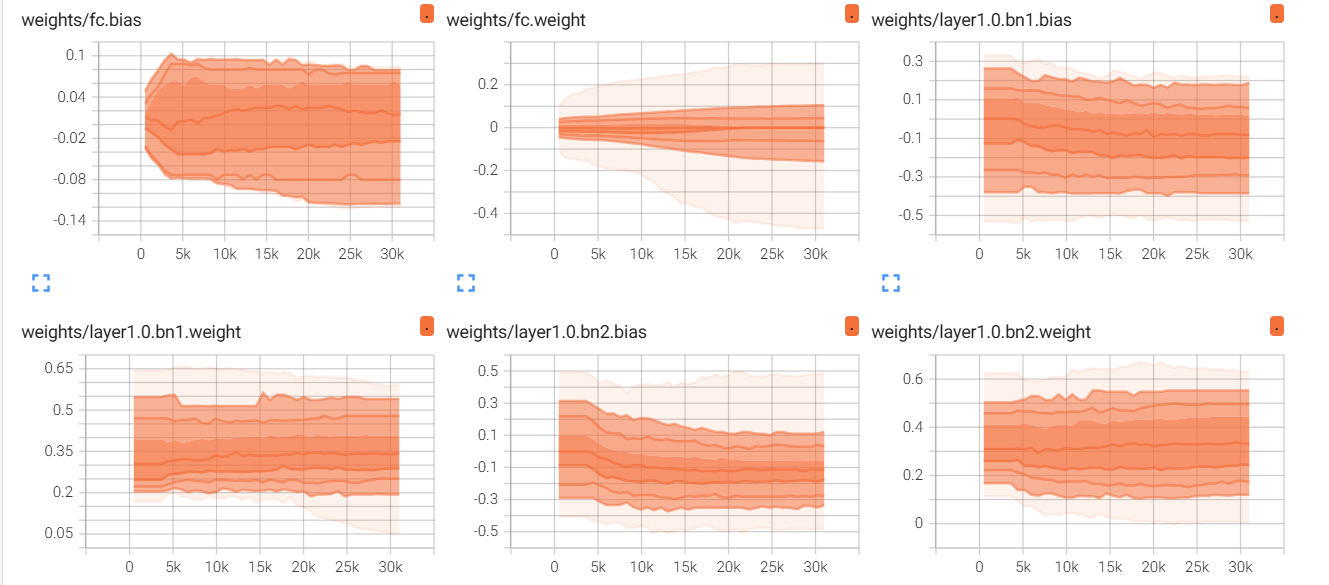
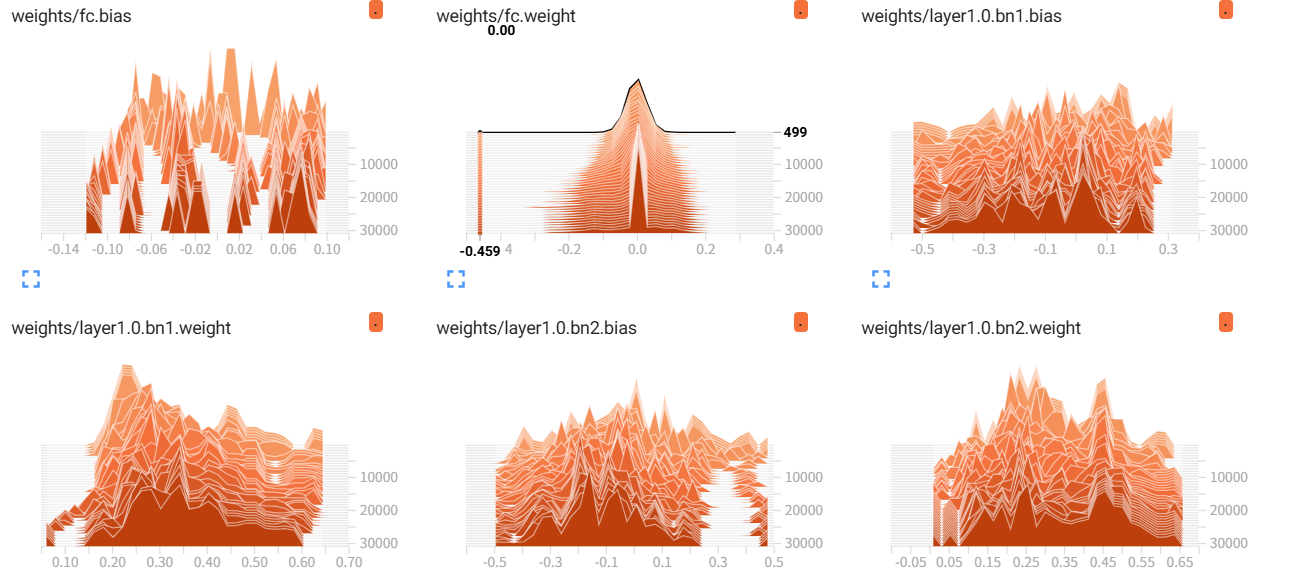
4.4 梯度和权重的分布
(1)梯度
(2)权重
五、注意事项
(1)虽然tensorboard的代码有一定的记忆量,但实际上深度学习的经典代码都是类似于八股文,看多了就习惯了。实际上对目前的ai而言,你只需要先完成最简单的demo,然后让他给你加上tensorboard需要打印的部分即可。
(2)核心是弄懂tensorboard可以打印什么信息,以及如何看可视化后的结果。把ai当成记忆大师用到的时候通过它来调取对应的代码即可。
(3)对于autodl云服务器直接点击终端的链接,可能出现无法访问的问题:进入容器实例后,点击自定义服务,可以访问端口的服务地址。

















 694
694

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









